



Nvidia’s Strategy to Put a GPU in Every Server: A Conversation with Manuvir Das
As the head of enterprise computing for Nvidia, Manuvir Das works with his team daily to help enterprises explore AI technologies and find new ways to use them in their businesses.
Das is the GPU maker’s point person and public face when it comes to AI in the enterprise, speaking regularly at Nvidia’s GTC conferences and participating in frequent product announcements about Nvidia’s latest innovations.
He is heavily involved in the company’s AI product roadmap and speaks AI fluently, passionately and without hesitation about what AI is, where it is going and what it can do for businesses.
Das joined Nvidia in November of 2019, coming over from Dell EMC, where he worked for seven years as a vice president of product engineering for unstructured data storage. He previously worked for Microsoft as the general manager of Windows Azure for six years, as the general manager of Windows Server for two years and as a principal researcher for four years.
He recently spoke with EnterpriseAI through a videoconference to discuss where Nvidia is today in its short-term and long-term AI strategies and how he and the company are continuing to work on delivering AI technologies to its customers.
Some of those ideas are particularly intriguing, such as his vision that GPUs will commonly come to enterprise servers in the next five years to make AI even more accessible and achievable for users. Keep reading for more insights and views about the rapidly changing and maturing world of AI from the leader of Nvidia’s enterprise computing division.
The interview is edited for brevity and clarity.

Manuvir Das of Nvidia
EnterpriseAI: Nvidia started out as a graphics card maker, but in the last 10 years it continues to dive more deeply into enterprise computing, supercomputing, HPC and future technologies. Can you tell us about the company’s AI strategy, starting from the last few years to where it is going?
Manuvir Das: Nvidia moves fast as you know, and we keep producing new things. When it comes to AI, it is basically a complete workflow. You acquire data. You process and prepare the data. You label it, you structure it and then you train the model with the data. And finally, when you have the model and you apply it, you do inference to use the model for whatever application you write. It is a process of multiple steps here. And the training part is very compute intensive, so you need big machines to do the training; the inference less so.
For the last 10 years, our AI strategy was about proving that AI is practical, that it can be done. And then if it is done, that it is useful in different domains. That was our entire focus initially. We were not thinking about broad adoption or ease of use or cost factors.
And the reason it has been more than a decade is that sometimes, when you start something new, you spend a few years just working on it in your own garage before the world knows that you have been working on it. That shift happened because the same computational units inside the GPU that we use for graphics turned out to be really good for inference training as well.
EnterpriseAI: How did someone figure that out, that GPUs could be used for AI inferencing?
Das: Really, it was the community at large beyond Nvidia which had the insight. It was a natural extension of the idea of training the models on GPUs. If training on GPUs was so much more efficient than training on CPUs, then why not look at the use of the trained model inferencing on the GPU as well? That is where it came from.
As it progressed, an Nvidia team later created a general purpose API on top of the GPU, with the intent that any developer could use the capability of the GPU for a lot more than graphics.
The field of AI had existed for some time and the algorithms existed, but it was not practical initially because the amount of CPU horsepower you would need to run those algorithms was too high. A GPU takes thousands of operations that would have to happen one at a time, one after the other or serially on a CPU and it can do them in parallel, or at the same time, on a GPU. It does that by using vector math. You put it all into one vector and you run the whole vector at one time. So, any computation where you must do thousands of things, and you can pack them together, it goes much faster on the GPU.
Computer science, at its origins, was about new concepts but for the last few decades, computer science research is about putting two and two together. It is about taking this idea from here, and that concept from there and marrying them together.
EnterpriseAI: How does this bring us to the Nvidia of today with AI?
Das: We are on a three phase AI journey. Phase one was, let us show the world that AI is real, that it is doable, and it has value when it is done. Let us go build the Lamborghini of AI. It did not matter what it cost, it did not matter how hard it was to use at that point. Let us just achieve these things. We really focused on the early adopters, the big internet companies who need AI because they want to tell you what to buy next or what to read next or what to see next. That is the phase we were in for a few years.
We are very happy with phase one, we were able to prove this out and reached a few thousand companies. But if you look at the landscape of enterprise customers, there are hundreds of thousands of companies out there, so this is not even the tip of the iceberg in terms of our reach.
Now we are at the beginning of phase two, which is the democratization of AI. What we mean is let's reach the 100,000 enterprise customers out there and let them have value by making it available to everyone.
This phase must be all about making the technology accessible, affordable, easy to deploy, consumable and showing customers how they can produce solutions that provide immediate value. So, you are not sitting there for a year playing with this stuff before you see the results.
EnterpriseAI: That is one of the things we hear all the time from enterprises, that AI is too hard to use, that they do not know how to get started and that they ultimately do not know what to do with it.
Das: Exactly. There are two kinds of people who use technology – there are builders and there are buyers. Builders say give me the parts and I will build my own [AI infrastructure]. Buyers ask where is the [AI infrastructure they can use].
In phase one, we were all about the builders. Now we are squarely in phase two, so the Nvidia product announcements you see from us, they are all about packaging together the AI and providing things that buyers can consume.
To put it in context, that is where several recent products come in. When you do AI, you need to do two things – the development – which is to get the data and produce the model. For that, we built Nvidia Base Command. Log in to Base Command and it has a simple interface. You do not care about the hardware or the software stack underneath. It is all hidden from you. You just submit your job, add your data and AI algorithm, and then we take care of everything. Your AI development happens, and you get a model out of it. We call it Base Command because it is done in your headquarters or in your data center somewhere.
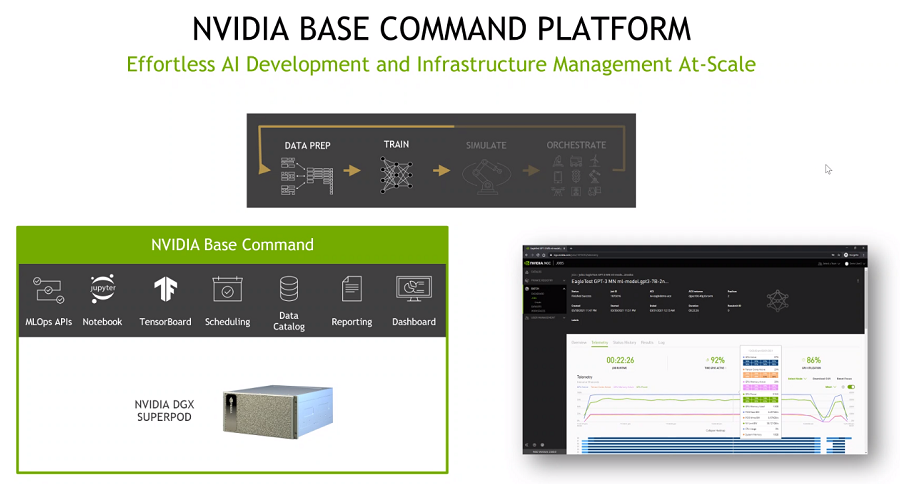
Nvidia Base Command
Then we have Nvidia Fleet Command, which looks at what you are going to do with the model. You have video cameras in all your stores, you have a server in every store, and now you want to send the model out to all those places so that the AI can run. That is what Fleet Command does. right. And then once you have your model, you send it out to the world with Fleet Command. It is called Fleet Command because with the edge, you do not have one building with 1,000 servers. You have a store here with one server, you have a store there with another server, and you cannot have people running around managing the servers. You must have some centralized way of managing it all.
Das: Then we have phase three, the true proliferation of AI from Nvidia, which comes when enterprise customers are adopting and using AI without having to learn about AI at all. In phase two, customers, whether banks or hospitals or whatever, they had to understand Nvidia Base Command, they had to understand Nvidia Fleet Command. They had to understand that they were building and using models.
In phase three, for example, a bank might have SAP deployed. And this year the bank is upgrading to the new version of SAP, and now SAP says that for the new version to run well that the server configuration must include a built-in GPU. And the reasons for this could be that SAP worked with Nvidia, and they infused the AI from Nvidia into the application. It can be done transparently, and the customer does not know that they just got a better application.
EnterpriseAI: So, the idea is to work with other vendors to integrate AI into their applications and hardware infrastructures using GPUs to make AI easier to deploy and use?
Das: Exactly. Here are three examples today. In Microsoft Word, you can enable a feature where you can type a sentence and it will show you possible completions of the sentence using infused AI. In Adobe Creative Studio, as you are building a scene, it will suggest things you can do, or images you can use, all via AI. And the Cloudera data platform, which is used by a lot of enterprises for big data on premises, just announced a new release where it is fully integrated in this fashion and the customer changes nothing. They are running the same cluster workloads, but they just happen to run faster and better, because there is a GPU underneath, and there is nothing the customer must know about or change.
Our expectation is that phase three will basically be this happening everywhere. A great example right of why we believe this will happen is to think back to the 1990s. Everything was command line applications from a console. Then the Graphical User Interface (GUI) came along, and it was this new thing. Some software vendors were skeptical and wondered who among them was really going to redo their applications to use a GUI. Well, everybody ended up doing that, because it was so powerful that if you did not put a GUI on your application that you were going to be left behind. We see exactly the same thing happening here.
EnterpriseAI: What are your thoughts on the wide range of newer AI uses that are in the marketplace today, from conversational AI to using AI for insurance analysis, product and service recommendation systems and vehicle crash damage estimators? Verizon is even using AI to locate new 5G cell towers.
Das: You should care about that. If you ask us the average person to describe AI, they think of what has been popularized in science fiction novels, of the Holy Grail of AI, which is a machine or something that behaves like a human. When we think of AI for enterprise customers at Nvidia, we tone it down one level by saying that we are not trying to replicate a human, but we are taking a particular function that a human would do and are providing an automatic way to do that function using AI.
In healthcare, a function is a doctor looking at an X-ray image and using their intelligence to say they see a problem, a fractured bone. That is a function that a human performs, and we can create software with AI that says that the software will do the same function.
With using AI to locate cell towers, that is another function humans were doing at Verizon where they were poring through spreadsheets and correlating data to say what was the best place to put a cell tower. Now, the AI software can perform that function. A recommender system is another example of what we do in our human conversations every day when friends call for recommendations on many things.
Our individual knowledge is just a set of data, and AI says it will take that data to train its neural network so it can answer questions for you through a recommender system. Conversational AI is like people having conversations with others all the time and responding to questions. You asked me about the weather, and I tell you it is a cloudy day. Those things are not as different as you think. They are just many different examples of the common concept, which is a human or group of humans do a particular function that is valuable. Now the question is can I build a piece of software with AI to do that function?
EnterpriseAI: Where does this all potentially lead for AI in society?
 Das: We are trying to say this is how the world works because humans do thousands of different functions in every industry, every day, and let us provide a software solution for that function. That would then give humans the time and freedom to do other things. And if it is done by software then it is repeatable and scalable.
Das: We are trying to say this is how the world works because humans do thousands of different functions in every industry, every day, and let us provide a software solution for that function. That would then give humans the time and freedom to do other things. And if it is done by software then it is repeatable and scalable.
EnterpriseAI: Thanks again for speaking with us today, Manuvir. Here is my last question for now: what will Nvidia be doing with AI in five years in terms of its roadmap and AI strategy?
Das: On this idea of really spreading AI wide in the enterprise, we are under no illusions that it will happen overnight. Where I hope that we will be five years from now is to have seen the adoption of AI go from thousands of companies to at least tens of thousands of companies.
Today, if you go to any data center that a company has, whether it is JPMorgan Chase, or wherever, and you open and look inside a random server, you will not likely find a GPU inside that server. That is because the number of servers that ship today with GPUs in them is in single digit percentages.
But over the next five years, we expect to see that pretty much every server that is deployed in the data center has a GPU in it. The reason is because so many of the applications that those companies are using will be based on AI and will require those server configurations we talked about earlier.
In the data center, it will be just like they have CPUs and memory and network cards, etc. It will just be de facto to have a GPU in there. That is another way of thinking about what we expect to see, this validation.






