



Shared Memory Clusters: Of NUMA And Cache Latencies
In the introduction article in this series, I explained that NUMA topology-based SMP systems with two levels to the memory (DRAM) hierarchy have been around and kicking for quite a few years now. We added a third level to this memory hierarchy when we added Shared-Memory Clustering (SMC). Either way, all memory (DRAM and processor cache) is potentially accessible to all processors. So what's the big deal? It's just one really big SMP, right? Well, yes, but it's what you can do efficiently with such a system that matters here.
Let's build this up slowly, and again start with a basic single-chip system as in the following figure. From the point of view of one of these processor cores, an access of the L1 cache – a cache very close to the arithmetic logic units (ALUs) – is typically accomplished in one or two processor cycles. For the L2 cache access, let's call that 10 cycles (it varies between processor designs), and the L3 cache is 100 cycles (typically well less); think for now factor of 10 differences. In the event of a cache miss, a memory access is required. Let's call the latency to main memory about 500 cycles; it is typically a bit faster than that. (We are after a concept here, not precision.)
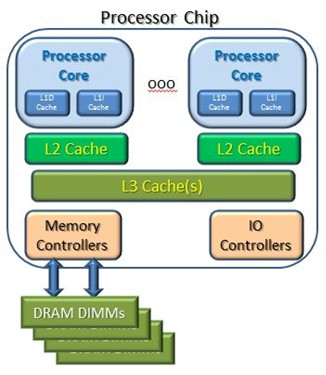
Now, for the next concept: Modern processor cores have scads of fine grain parallelism. In the event that the cores are getting L1 cache hits, these cores are capable of executing quite a few instructions per processor cycle. But, again, for reasons of explaining a concept, let's say that the cores are executing just one instruction per processor cycle. (That's not an unreasonable guesstimate even with L1 cache hits for reasons we won't get into here.)
Now add another simplification – this is leading somewhere important – suppose that after executing each set of 500 instructions, our program takes a cache miss that is satisfied from the DRAMs. Said differently, we execute 500 instructions at the rate of one instruction per cycle – totaling 500 cycles - and then the core waits for 500 cycles for the needed data to be pulled into the core's cache. All told, we've just executed 500 instructions in 1000 cycles or about 2 cycles per instruction, or 2 CPI in the chip lingo. (In reality, given fairly probable cache fills from L2 and L3 caches, and even from other core's caches, this rate of instruction execution is considered high for many workloads, but let's go with this.)
Let's now factor in the second level of the NUMA hierarchy as we again see in the following figure.
Here, too, we have cores capable of accessing their own local memory with the same latency as in the previous example. If every core's accesses were satisfied only from local memory, and DRAM access probability remains the same, all cores would perceive an execution rate of 2 CPI. We are about to change that assumption.
For the purposes of this article, let's say that the number of cycles for a reference core on Chip A to access the memory from Chip B (i.e., remote memory) is twice that of local memory. (For such point-to-point SMP fabric connections, twice the latency is considered high.) The added latency is due to Chip A's cache miss processing needing to send a request from Chip A to Chip B, have Chip B process the request including accessing Chip B's local memory, and sending the response data back to Chip A.

So now let's change the memory accesses and have all of the DRAM accesses on the cores on Chip A be from remote Chip B's memory; twice as long means assuming that these take 1000 processor cycles. So we again have 500 cycles executing instructions at the rate of 1 instruction/cycle plus an extra 1000 cycles for each remote memory access. This totals 1500 cycles or – having executed 500 instructions - 3 cycles per instruction (3 CPI). As compared to the previous case this is 50 percent slower. Fortunately, for all sorts of reasons, reality moderates this quite a bit, but the point is that it could be this much; perhaps think of it as an upper limit.
Now mentally redraw that very same picture, but let's have the two chips reside in different nodes of the SMC cluster. Functionally, programmatically, it's still an SMP but now the latency of a remote access – we are calling this a "far" access in these articles – is higher. Every design and every topology will have different latencies, but for purposes of explaining the effect, let's call a far access five times longer than local memory as opposed to previous case – to remote memory – being 2 times longer.
So, again, we have 500 instructions at 1 instruction per cycle (500 cycles) plus 2500 cycles for the far DRAM access, totaling 3000 cycles. This is 6 cycles/instruction, 6 CPI versus the 2 CPI for the strictly local accesses and 3 CPI for strictly remote. This is three times slower. Clearly enough, when looking at such a system, you will want to ask about such relative latencies. Some topologies with multiple "hops" may be still higher. But don't panic; read on.
At this point you might be thinking: "Why would anyone use a machine based on this?" The why is that, your application could find all of its data in another far node, but it typically won't. I will explain why and what you can do to ensure that. I outlined all of the above for you to understand that the operating systems and applications want to do something about this. This is not just one big SMP with scads of processors and buckets of memory.
Consider a couple of fairly straightforward suggestions (not rules):
- Put the work where the data is and
- Put the data where the work is.
What these do is to influence the probability of an access to local memory versus remote memory and to remote memory versus far memory. Again, shared memory clusters can be functionally very big SMPs, so it functions where we fail with these suggestions, but performs better the more that we can succeed in following these suggestions.
Let's drive that last point home a bit more. Consider this NUMA-based system, each processor chip with, say, 8 cores per chip and perhaps 256 GB per node; we will have four chips making a closely coupled node and have a total of four nodes. This is a 16-chip, 128-core, 4 TB system. And this is not a big system; more dense DIMMs, more chips per SMP system, and more nodes – either configured as a two-level NUMA system and or nodes of an SMC cluster allow this example to grow. This is also basically an SMP, just one with lots of processors. As each task (a.k.a., thread) becomes dispatchable, if there is a single OS spanning all of this, it could (stress "could") execute on any core of this entire system. If the OS were unaware of the NUMA boundaries, it would perceive any core as being just as good as any other.
![]()
Similarly, as each page (typically 4096 bytes per page) of physical memory is allocated for use by that task, it too could have been allocated from any of this memory. Although we all look at this picture and see otherwise, at some level this SMP is just 128 cores attached to 4 TB of memory. But with no knowledge that these NUMA-based SMC systems really are something else, that would be how it gets used. If that is all that happened, if the OS ignored these suggestions – if any core and any memory got used – in this 16-chip system, each task would have only a 1 in 16 chance of finding its needed data in local DRAM memory. If the four nodes shown were nodes of an SMC, the probability of far access is 75 percent. (Processor caches, of course, increase the probability of locally accessing data.)
This system is not a vanilla SMP; it is something else, and you, your applications, and the OS know this. So what can the OS, at least, do about it?
The OS is fully aware of this system's nodal topology. It therefore also knows that in this particular system, a task can be dispatched to any one of a chip's eight cores and can also allocate the task's storage needs from that same chip's local memory and both would provide local memory access latencies. If later it can be re-dispatched to these same cores and continue to allocate its memory locally, all of these memory accesses remain local accesses. For all storage that is thread-local (that is, the program stack) or often process-local (that is, the heap), this falls out naturally. At low to moderate utilization of each, that is a fairly straightforward thing to do. Again, refer to our placement suggestions earlier.
One fairly easy trick to do takes nothing more than providing each task, perhaps each process, with an identifier of a preferred chip and, from there, a preferred node. Ideally, storage accesses are local, but some reasonable sharing in remote memory (local to a node) is often fine as well. It is similarly not a bad thing for a task to temporarily be bumped to a core of a non-preferred chip. Using our simplistic calculation of CPI used earlier, as much as 20 percent of the memory accesses could be to remote memory and it would still impact that thread's performance by less than 10 percent.
Most OSes also provide the means whereby applications and system admins can hint to the OS that there are additional opportunities for maximizing local accesses as well. Again, two-level NUMA has been around for a while. (Indeed, patting myself on the back, yours truly is an author on a number of patents relating to such.)
This perhaps nonchalant attitude toward local versus remote-based NUMA control needs to be taken a bit more seriously when the latency to far memory goes up considerably. It is not that the occasional accesses to remote memory are bad or that for very good performance reasons in its own right you really do want to directly access another node's far memory. (The alternative, after all, could have a considerably larger impact on performance.) The question really is, to what extent can we treat all of the cores and all of the memory of these SMC systems as being just part of a vanilla SMP?
Going back to our simplistic calculation of CPI, ignoring the truly needed far accesses, we can stay within 10 percent of the performance of strictly local accesses if the percentage of accesses to far memory was within 5 percent of all accesses. (Again, don't expect precision here; this is to aid with understanding the concepts.) Take another look at the basic suggestions for managing NUMA:
- Put the work where the data is and
- Put the data where the work is.
Again, in the two-level NUMA systems, these are largely suggestions. With this shared memory cluster system and its three NUMA levels to latency, perhaps these suggestions should approach being rules. But before we go on, consider that distributed-memory systems would tend to treat these suggestions more as requirements. These shared-nothing system have technologies for doing such and are being enhanced at this writing. They exist, though, because the user knows that they can't share data except through various forms of messaging. Now you also know that these shared memory clusters are not simple shared-memory SMPs, but you also know that they can share data. Here you are not dealing with the absolutes implied by a shared-nothing topology. Instead, what you know now is that you have the options to choose amongst a set of performance and economic trade-offs. You may want to choose what goes where and to do so you will want to have some level of control over it. But absolutes here are not really a requirement.
Articles In This Series:
Shared Memory Clusters: Of NUMA And Cache Latencies
After degrees in physics and electrical engineering, a number of pre-PowerPC processor development projects, a short stint in Japan on IBM's first Japanese personal computer, a tour through the OS/400 and IBM i operating system, compiler, and cluster development, and a rather long stay in Power Systems performance that allowed him to play with architecture and performance at a lot of levels – all told about 35 years and a lot of development processes with IBM – Mark Funk entered academia to teach computer science. [And to write sentences like that, which even make TPM smirk.]He is currently professor of computer science at Winona State University. If there is one thing – no, two things – that this has taught Funk, they are that the best projects and products start with a clear understanding of the concepts involved and the best way to solve performance problems is to teach others what it takes to do it. It is the sufficient understanding of those concepts – and more importantly what you can do with them in today's products - that he will endeavor to share.






