



Shared Memory Clusters 101
Shared memory clusters are one of those technologies that is at the same time just evolutionary, but also – because of what it will become – potentially revolutionary. Although related technologies like distributed shared memory or virtual memory sharing within clustered systems – essentially message-passing "shared-nothing" architectures – have been around for a few years now, with shared memory clustering (SMC) it is as if the right set of engineers, computer architects, and HPC and Big Data programmers finally got together and decided to build what they have really wanted all along.
And better yet, SMC is now beginning to show up in products from quite a few vendors, all of them about the same time realizing that we can do this.
So what is an SMC really? You will get a relatively complete answer by reading to the end of this series articles, but I will try to give you a quick introduction in this first article. As cool as it is, as big a deal as this can become, I will tell you right up front that SMC does have some goinks and gothchas. The short answer, though, is what the marketing wings of these vendors are telling you with some strong basis:
- All the memory residing in your otherwise distributed systems now becomes directly accessible from all of their processors. Think hundreds to perhaps thousands of processors, each with direct access to what could be hundreds of terabytes of physical memory.
- You get large – indeed very large – systems with linear (per node) pricing, not the relatively hardware cost-independent capacity-driven system prices of large SMP (symmetric multi-processor) based systems.
- Truly huge in-memory databases can now really fit in memory.
- You can program just as you would in an SMP and access massive amounts of memory-resident data.
- The rapid inter-process communications and sharing that you can expect within an SMP is now largely available across clustered systems as well, rather than needing to rely on more traditional network-based data copying techniques.
All true. But just like the set of blind men together asked to fully describe an elephant, to really get a sense for this technology, to really understand how to deploy it, we need to start by describing it via metaphor, building up the notions of the actual enabling technologies. Most have been around for some time, many with which you are likely to already be familiar; they are just extended to produce something really new and potentially remarkable in computing.
So where to start? Vulcan mind melds are not yet an option, but would come in handy here. Let's start by overstating the two ends of the spectrum of today's computing. Purists in both camps will be, and ought to be, upset with me, but I need to set the stage first for everyone.
In one corner we have distributed systems. They make up what has been variously called client/server computing, the grid, the cloud, the Internet, and also clusters to name a very few. Techies in both hardware and software have for a lot of years produced remarkable strides in speeding communications between these systems. At the bottom of it all is specialized hardware with the basic purpose of reading blocks of memory from one system and copying it to another. In general, the shorter the distance between systems, the fewer the number of hops required to forward the memory contents, the faster it is. On top of that though, software – minimally on both sides – gets involved to provide the right source data to the right target.
Almost from the beginning of modern computing, it is not a processor doing the actual data copying; it is an asynchronously executing engine – I will be calling it a DMA engine (Direct Memory Access) – which software on a processor invokes to begin the actual process of reading the data block(s) out of the source system's memory. At the receiving end is another DMA engine, which writes the received data blocks into the target system's pre-allocated memory and which when complete typically interrupts a processor to tell it that new data has arrived. Software then gets involved – sometimes a lot of it, sometimes considerably less – to complete the copied data's delivery. Perhaps this gets hidden from the application, often times not. But almost always the existence of this asynchronous data copying does get perceived somehow. (I will be devling into this in greater detail in future stories.)
In the other corner is what most folks think of as the single-system image. This is a machine with some or many processors, all capable of accessing physical memory (e.g., DRAM), all typically maintaining a coherent cache or set of caches, all executing on behalf of some set of applications within a single operating system. As I will be discussing later,the boundary lines here get blurred.
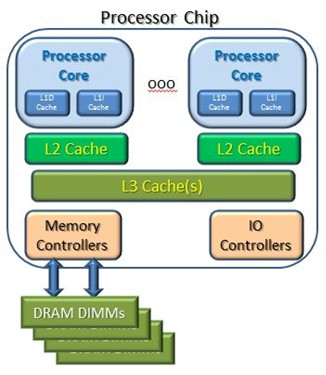
So, let's draw a very simplified picture of the processor system you are likely using to read this article. As a relatively simple data flow:
- Programs execute on cores, accessing primitive data types.
- Processor cores read from cache.
- Processor cores write to the cache.
- Caches are filled with blocks of data from the DRAM or from the caches of other cores.
- Data blocks in cache are stored to DRAM.
Said differently, the processor cores don't actually access the DRAM directly. Instead, multi-byte blocks (32, 64, 128 bytes) are filled from the DRAM to the cache, and changed blocks are stored from the cache to the DRAM. This is done no matter the number of bytes needed or changed. In addition, if another core wants the data block in another core's cache, it can get it from there. And, by the way, this all takes time. So, why is this important and what does this have to do with SMC? To get closer to that, we need to look at a slightly larger but still a very real system consisting of multiple chips.
What follows is also a relatively simple two-socket system. As with the single-socket system, the contents of all memory (DRAM and cache) is accessible to all cores, no matter on what chip they reside. These are the basic rules of all SMP-based system. Note, though, that a cache fill by a processor on Chip A, needing data found local to Chip B, makes its request over and has the data block delivered via the inter-chip SMP fabric. (At some level, that link rather looks like a point-to-point network, doesn't it?)

An important thing to see here is this notion of local memory and remote memory. Each chip has its own local DRAM and cache; the other chip's cache and DRAM is considered remote to cores on the first chip. As you might expect, accesses by Chip A's cores to its local memory (DRAM and cache) is completed slightly faster than a similar access to remote memory found attached to Chip B. This is the basic characteristic of a NUMA (Non-Uniform Memory Access) topology. I'll add here that this two-socket system is considered small by systems developer; NUMA SMPs with tens of chips and roughly ten cores per chip are common.
Systems based on NUMA topology have been around for quite a few years now. NUMA exists largely to effectively increase the bandwidth and minimize the latency to local memory. Each additional chip provides more bandwidth simply because there are then more available busses. (I won't show it here, but mentally picture what it would take if tens or hundreds of processors were all attempting to access DRAM over a common set of busses.)
I will get into NUMA in more depth in later articles, but for now, just realize that the OS(es) on such a system are fully aware of the existence of this topology and manage work and data appropriately to minimize latency. But, again, all memory is accessible to all processors. The OS may manage latency to improve single-task performance and overall system capacity, but from a basic functional point of view, your applications and the operating systems do not care. Don't get me wrong, though, there is benefit to performance in a number of forms by having this awareness, but far and away most of us don't need such knowledge. (We'll get into performance on SMCs in a future article.
So why tell you all this? It relates directly to the shared memory clusters. Notice in the NUMA SMP figure that, from the point of view of some reference core, we have "local" memory and we have "remote" memory; this is two levels to the memory hierarchy. Shared memory clusters offer a third NUMA level; I'll here call it "far" just to drive the point home. But it is NUMA; memory is accessible from any processor. I will cover the effects of different latencies in another article; for now just know that occasionally it will matter.
The key concept to note, though, is that using potentially the very same programming and addressing model that you use to access memory in two-level NUMA systems, the memory of this third level can be accessed as well. We have a way to go yet, but you see now the basic starting point of why it could work.
So now, slowly returning to distributed-memory systems, picture two processes – one thread each per process – wanting to communicate. Let's first have these two processes residing in the same two-level NUMA system and they want to communicate. You have got quite a few options open to you via Inter-Process Communications, some of which include shared memory. With shared memory, the two threads can be accessing and even modifying exactly the same data at exactly the same moment. And, using shareable memory, even the data copy-based forms of communications can be done efficiently. It seems clear that these concepts can be mapped onto SMC's three-level NUMA systems.
We could also have these two processes residing on different non-SMC-based nodes (a.k.a., systems). In such systems, using communications-based hardware and software protocols is your only option. Even with the "sharing" being abstracted by a programming language or OS hypervisor, as good as this hardware and software may be, making copies of that data is still required. This takes longer. Interestingly, in any SMP, copying of data is also occurring, but that copying is done at via the caches and that is a subject of another article and it is also transparent to software.
Now, let's come all the way back to why shared memory clusters – or even distributed memory clusters – should exist in the first place. They multiply whatever processor capacity or memory capacity that is available in any one SMP. From an essentially economic view only, you would expect that such an SMC-based system's hardware price would increase roughly linearly with the number of units, memory, and cores. True enough. That happens to be less the case with today's two-level NUMA SMP-based system prices. Although for a large class of uses, SMP systems increase capacity linearly with the number of cores, their price increases faster. So we have a trade-off. Do we go with larger SMPs and their faster inter-chip latency or with more nodes of SMCs? Good questions that need examination.
There remain still very good reasons for both the networked systems, especially networked clusters via Ethernet or InfiniBand, just as there remain very good reasons for SMP and NUMA SMPs, especially large ones. But now we have a new technology that allows us to keep the performance and programming productivity benefits of SMPs and grow it into the realm of many-node clusters.
To try to explain the trade-offs further and to try to outline the various attributes of the differences better, I will also be – at this writing - covering:
- SMT (Simultaneous Multi-Threading, HyperThreading),
- Relative NUMA latency trade-offs and topologies
- Far node cache coherence
- NUMA management
- Virtualization options
- Persistent memory
- Addressing and Security
Stay tuned.
Articles In This Series:
Shared Memory Clusters: Of NUMA And Cache Latencies
After degrees in physics and electrical engineering, a number of pre-PowerPC processor development projects, a short stint in Japan on IBM's first Japanese personal computer, a tour through the OS/400 and IBM i operating system, compiler, and cluster development, and a rather long stay in Power Systems performance that allowed him to play with architecture and performance at a lot of levels – all told about 35 years and a lot of development processes with IBM – Mark Funk entered academia to teach computer science. [And to write sentences like that, which even make TPM smirk.] He is currently professor of computer science at Winona State University. If there is one thing – no, two things – that this has taught Funk, they are that the best projects and products start with a clear understanding of the concepts involved and the best way to solve performance problems is to teach others what it takes to do it. It is the sufficient understanding of those concepts – and more importantly what you can do with them in today's products - that he will endeavor to share.






