



Wall Street Wants Tech To Trade Smarter And Faster

The HPC Linux on Wall Street conference was held in New York City this week, and a lot of the talk at the event was on high frequency trading in the wake of Flash Boys, the new book by Michael Lewis that was announced a week ago causing an uproar in the financial services sector. Everyone at the show adamantly (and obviously) disagreed that the stock market is rigged, which is the contention of the book, and then focused in on talking about issues of performance, latency, and cost as it relates to all kind of trading in financial markets – not just the high frequency kind.
High frequency trading now accounts for more than half of the trades done on the NYSE and NASDAQ exchanges. The talk at the show was that HFTs provide liquidity in the market, as do the myriad dark pool private exchanges, and that this not only closes the gaps between buyers and sellers but also lowers the cost per transaction for all of us who have investments in equities, bonds, and other assets. Moreover, with systems being able to parse language, humans simply cannot keep up. No matter how you feel about HFT or automation in general, one thing is clear: such automation is not going away and no one is going to bring book runners back onto a human-based trading floor.
To illustrate this point during the opening keynote, George Kledaras, founder and chairman of FIX Flyer, which creates algorithmic trading platforms, talked about how impossible it is for people to keep up and used the day when the statements from the Federal Open Markets Committee of the US Federal Reserve Bank are put out. The entire cycle, from the nanosecond that the FMOC statement was released, including the transmission of trading instructions from Chicago, where the report came out, to the exchanges in New York, took 150 milliseconds. After that, most of the trading was done.
"The machines have 100 percent taken over, and no human being, even with fingers right over the keyboard, could react," said Kledaras. "This is the debate that is going to go on. The computers are making the decisions, not just doing the trading. They have to parse English, because it is written in English, and they have to be able to rip it out in terms of the trading and do that all at the same time. It is amazing how far we have come in just a few years."
It is no wonder, then, that the topic of high intelligence trading, which means injecting more data analytics into the trading systems, was the subject of the keynote. As EnterpriseTech has previously reported, IBM and financial services consultancy Integration Systems are working together to pitch Big Blue's Power Systems as a better alternative to X86 iron for trading systems, high frequency or otherwise. And in the keynote, Terry Keene, CEO at iSys, reiterated the idea that some trading firms were willing to sacrifice some speed in exchange for having less jitter in their transactions from end to end. Because the Power7+ and soon the Power8 processors have such large caches on the processors and soon in the memory controllers and so much higher I/O and memory bandwidth as well as higher clock speeds compared to X86 iron, this can have a dramatic effect on reducing jitter in the system.
But high intelligence trading is not just about building a better server or trading system mousetrap. It is about embedding more analytics into the trades themselves, and the reason is because being an HFT with a good set of algos is no longer sufficient to make money.
"In the past two years, people have started using big data tools like Hadoop and have come to realize that they do not need the absolute flat out fastest pipes and fastest FIX engine and the fastest everything to be the first one in the trading queue," explained Kledaras. "If I can instead predict that I am going to be first in the queue 80 percent of the time, I think I can get there. A high frequency trader told me about a year ago that you have to consistently be among the top 30 in the queue, otherwise there is no way for you to make any kind of money. And only a few firms can afford to play at that level."
So today, the big players are starting to use machine learning and predictive analytics not only to do statistical arbitrage, but to predict where they can get to the front of the queue before they execute a trade. "This has been a very successful trading strategy, and if I get one more picture of a 28 year old standing in front of a Tesla, I am going to go crazy," added Kledaras with a laugh.
"It is changing very fast," Keene concurred. "We have a number of high frequency trading customers whose algorithms basically sit and watch for minutes to respond, looking for the exact right configuration of the market criteria they need, and when the minute they get the right criteria, then they begin trading. So they are not doing this on a continuous basis where they need pure speed."
To do such trading takes a lot of data, of course, as Alex Tsariounov, principal architect of the London Stock Exchange, explained. There is a tremendous amount of post-market data that gets chewed on, and it often takes two days to run simulations and risk analysis against that data. "The problem is that by the time you make decisions, the data is slightly stale. So what we want to be able to do is real-time analysis on that data and make that data available essentially as a market feed to trading participants."
Tsariounov said that almost all of the traders interfacing with the LSE were looking at this, either creating their own in-line analytics or hoping the LSE will do it as a feed. "The key is to bring some of this data into the pre-trade process," he explained. "In trading, you are thinking about microseconds. In post trade, you are really thinking in seconds. This imbalance needs to be addressed."
Traders are also trying to figure out how to mash up social media and news feed data with the market data, but no one offered up any insights on who was doing it or how. (We will start chasing that story for you.)
NUMA's Revenge
Fadi Gebara, a senior manager at IBM Research, said that Wall Street firms were taking a hard look at shared memory systems. After analyzing code at financial services firms, IBM has figured out that a lot of what applications are doing is shuffling around bits rather than chewing on them and on a cluster of X86 servers you can, as he put it, "get MPI'd to death getting all of that communication going."
"Data movement is very expensive," Gebara continued. "Programs are moving data left and right and all over the place, and we have found that 80 to 90 percent of what the program is doing is moving data."
IBM has a few solutions to this problem. The first is to use data compression to crunch data so it is smaller as it moves, and the second is to use accelerators like FPGAs to do sorting routines and searches, where they can run considerably faster than on the CPU, leaving the CPU available to do other work. The other thing to do is to move from clusters to shared memory systems, which converts the milliseconds of latency between cluster nodes on a high speed InfiniBand or Ethernet network.
"This problem was solved many years ago by scale up," explained Gebara. These systems were expensive, and that is why financial services firms, like supercomputing centers, were among the first to switch to clusters of cheaper X86 servers running Linux and using Beowulf clustering. "Everything that is old is new again," he said about resurgence in shared memory systems. "If you are clustering, hats off to the networking guys because they are doing a great job, but you are never going to beat a scale-up machine in terms of overall efficiency."
Oracle, of all companies, recently made a similar argument comparing a cluster of its Sparc T5 servers to a massive Sparc M6-32 system. A network of sixteen of the Sparc T5 servers cost the same as the M6-32, and has a third more cores and threads. But the bandwidth across the "Bixby" interconnect used on the M6-32 system, which has 32 sockets with six cores per socket, is 24 Tb/sec, or 37 times higher than the Sparc T5 cluster running on 10 Gb/sec Ethernet, and the network latency, at 150 nanoseconds, is a factor of 100 times lower.
Tsariounov explained that the London Stock Exchange was indeed looking at shared memory systems and how they might be deployed to better run applications. At the typical exchange these days the state of the art is to have a hundred of so 16-core servers in a cluster supporting a workload, with 40 Gb/sec or 56 Gb/sec InfiniBand or 10 Gb/sec Ethernet links. This works fine for some workloads, Tsariounov said, but if you look at a scale-up machine with perhaps hundreds to thousands of cores with a huge amount of memory and a single system image, you can leverage this hardware in a number of different ways. You can load up OpenMP or other parallel programming environments and run cluster code on top of it, or you can rewrite your code to specifically take advantage of the underlying threads and other hardware features in the system. The other option is to port only the messaging layer, essentially converting from whatever cluster interconnect you had so it runs atop the shared memory fabric of the system.
"The benefit here is obviously much faster communication times, much faster routing times, because you don't have to deal with contention – and I hate to use the word contention because you will always have to deal with contention – in an external switch takes longer than with internal routers."
The idea, then, is that you might need a much larger shared memory system to merge together market data, social media sentiment data, and other data before executing a trade, and it is so much easier to stream this all into the memory of a single system where it can be processed at high speed. This problem almost demands a shared memory system rather than a loosely coupled cluster, said Keene.
Not everybody thinks this way, of course. There are other approaches, and Andrew Bach, chief architect for financial services at switch maker Juniper Networks, outlined the challenges that traders face and how they might address them to reduce the latency in trading.
The problem, said Bach, is that processor speeds have long since leveled off, so you can't execute trades any faster by goosing the CPUs. Moreover, the port-to-port latency in top-of-rack switches converged to just below 450 nanoseconds for InfiniBand and Ethernet, with Ethernet narrowing the gap. (Depending on the vendor, latencies are somewhere between 200 and 400 nanoseconds.) While vendors will seek to push this down, it is precisely as difficult as cranking up clock speeds on processors. Every tiny incremental step requires an exponential increase in power consumption and heat dissipation, both of which are unacceptable in power-constrained co-location facilities.
Here is the typical trading scenario as Bach sees it:
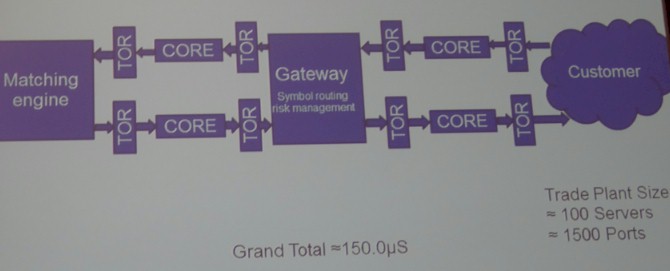
So the typical trading plant might have 100 servers with 1,500 ports in total, and after going in and out of core switches and top-of-rack switches and through gateways where symbol routing and risk management routines are calculated before a trade is executed, it might take something on the order of 150 microseconds to execute a trade.
"If we start to think about how we design our network infrastructure and systems more holistically, we can move things around," explained Bach. "We can start distributing computing resources into different technologies. We can take the general-purpose computing in a server and start to move some of its computations into an FPGA on a network interface card. With custom programming, these FPGAs can do preprocessing, and that is a redistribution of cycles to a more appropriate environment. You can also use top-of-rack switches that support independent VMs and move the application into the switch. Some of these switches also support FPGAs, and you have a tremendous amount of compute capacity at the switch level. Once you go through this, you can easily reduce the number of servers."
In this particular scenario, here is how it ends up:
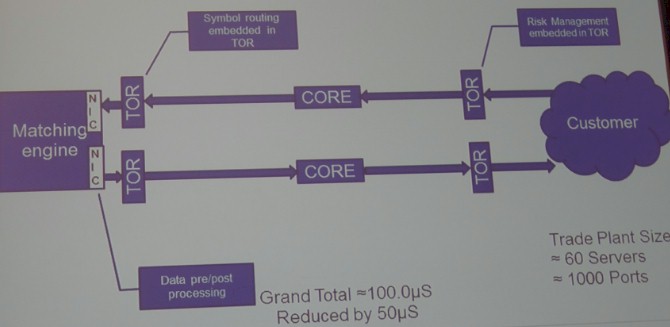
The risk management is embedded in one set of top-of-rack switches, these kink out to the core switches, and the symbol routing that was done in the gateway is pushed into the top-of-rack switches out above the matching engine. The data pre-processing and post-processing is pushed down into the network interface cards on the servers in the matching engine. When this is all done, the trade plant has a 40 percent reduction in server count, to 60 machines, and only needs 1,000 ports instead of 1,500 ports, a 33 percent reduction. More importantly, the trades can execute in 100 microseconds, a 33 percent reduction.
When asked that could be done beyond this to reduce latencies, Bach said he was trying not to bet on the invention of warp theory, but that he was optimistic that the way that FPGAs were progressing that there would come a day when an entire application would fit on a single FPGA, with 100 Gb/sec networking in and out, significantly cutting down on latency again. Beyond that, it is hard to say.






