



The Math On Big NUMA Versus Clusters
Even if you are not thinking of buying a big Sparc/Solaris server, some new math by Oracle might get you to thinking about shared memory machines as opposed to clusters.
This is particularly important as Intel is getting ready to revamp its high-end Xeon E7 processor line and SGI and Hewlett-Packard, and perhaps others, are forging shared memory machines based on these Xeon E7 chips that go well beyond the normal two and four sockets. SGI, as EnterpriseTech has reported, is working on a "HANA Box" variant of its UV 2000 system that will span up to 64 TB of shared memory, tricked out with the just-launched "Ivy Bridge-EX" Xeon E7 v2 processors and tuned specifically to run SAP's HANA in-memory database. HP is working on "DragonHawk," which is based on its own chipset and interconnect, which is based on the Xeon E7 v2 processors as well, and which will span hundreds of cores and tens of terabytes of shared memory. There is a variant of this system in the works, code-named "Kraken," that will also be tuned up for SAP HANA.
In days gone by, during the dot-com boom where processing capacity was a lot more scarce than it is today, Sun Microsystems had a tidy business reselling its "Starfire" E10000 NUMA systems to just about every startup and plenty of enterprises looking to offload work from IBM mainframes or aggregate it from proprietary minicomputers. The Starfire systems were kickers to the Cray CS6400, a line that Sun bought from Cray in 1996 and from which it literally minted billions of dollars. The Starfire was the most scalable RISC server on the market at the time, with its 64 sockets and a whopping 64 GB of main memory across its sixteen system boards.
Oracle's Sparc M6-32, which was announced last fall, is the great-great grandchild of the Starfire system, and it is also one of the most scalable systems on the market today. The fact that it is not based on an X86 architecture makes it a tough sell in a lot of datacenters, but because Oracle controls its own chipsets and interconnects, it can scale the M6 system up to 96 sockets and 96 TB of shared memory. The company has not done that yet, so SGI's "UltraViolet" UV 2000 system, which has 256 sockets and 64 TB of shared memory, is still ruling when it comes to scalability on general purpose machines. The word on the street is that HP will span sixteen sockets with DragonHawk, but it could do more than that. The chipsets it created for its Itanium-based Superdome 2 machines span up to 32 sockets, and HP has engineered 64 socket machines in the past, too. And, of course, Cray's Eureka massively multithreaded machine, based on its own XMT-2 processors, is the most scalable shared memory system ever created. It can have 8,192 processors, 1.05 million threads, and 512 TB of shared memory in a single system image.
Suffice it to say, there could be a resurgence of shared memory systems, particularly among customers whose workloads are sensitive to bandwidth and latencies between nodes and will run better in a shared memory system than they do across clusters of standard two-socket X86 nodes lashed together with Ethernet or InfiniBand fabrics.
The fun bit of math that Oracle did in a recent whitepaper to try to peddle its new M6-32 system was to compare one of these big bad boxes to a cluster of its own Sparc T5-2 systems. Take a look:
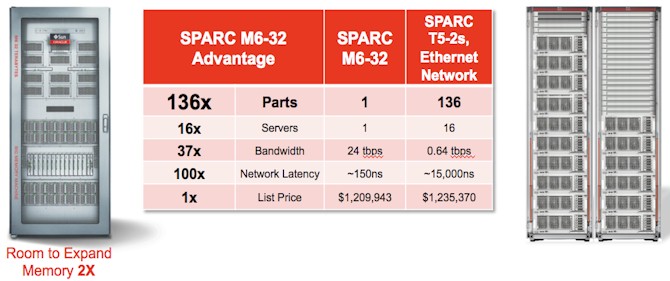
The Sparc M6 processor has twelve cores running at 3.6 GHz, so the 32 socket machine has a total of 384 cores and 3,072 threads in a single system image. The M6 chip has 48 MB of L3 cache that is shared across those dozen cores and can have up to 1 TB per socket of main memory. EnterpriseTech attempted to get the precise memory configuration used in this comparison, but it was not available at press time. Based on the comment that there was room to expand the memory by a factor of two in this chart, it stands to reason that this M6-32 machine as configured with 16 TB of memory across those 32 sockets.
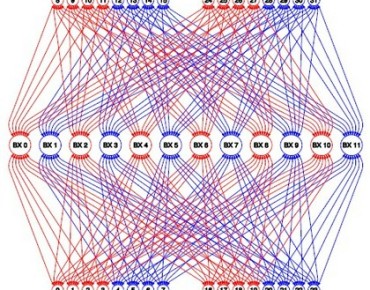
The shared memory system is enabled by a homegrown interconnect called "Bixby," and as you can see, it provides significant advantages in terms of bandwidth and low latency between the processors compared to a network of sixteen Sparc T5-2 two-socket servers using the Sparc T5 chip. The Sparc T5 chip runs at 3.6 GHz as well and is based on the same "S3" core as is used in the M6 chip. However, the T5 has sixteen cores on the die, but only 8 MB of shared L3 cache across those cores and can only have a maximum of 512 GB of memory per socket. Oracle has normalized the memory across the shared memory and clusters so they both have 16 TB, but the T5 cluster has 512 cores (33 percent higher than the M6-32 system) and 4,096 threads (again, 33 percent higher).
The interesting thing is that the M6-32 system has a factor of 100X lower latency between processors than the T5 cluster connected by 10 Gb/sec Ethernet switches and has a factor of 37 more bandwidth across that interconnect. And, amazingly, Oracle is charging, at a little more than $1.2 million, about the same price for the two machines.
The more interesting comparison perhaps would start with a 96-socket M6-96 with 96 TB of memory, or better still, twice that with even fatter memory sticks when they become available. To this, it would be intriguing to see what a Sparc T5 cluster with 10 Gb/sec Ethernet would cost and then perhaps a bare-bones hyperscale system using InfiniBand interconnect equipped with the latest twelve-core "Ivy Bridge-EP" Xeon E5 chips from Intel.






