



SAP Scales Out HANA In-Memory For Clouds

Software giant SAP is announcing new packaging and transparent pricing for its HANA in-memory database running on its own SAP Cloud. The announcement comes as SAP is claiming to have set the Guinness World Record for the largest data warehouse in the world with a hybrid machine that marries its HANA in-memory database with its SAP IQ columnar relational database.
The HANA Cloud Platform, which debuted last October, has now been renamed the SAP Cloud to demonstrate that it is not just about HANA any more, but about running all of SAP's applications as well as those from third parties atop the HANA in-memory database. The SAP Cloud is running in fifteen different SAP datacenters worldwide, and partners such as Amazon Web Services are also reselling their own HANA slices.
On the SAP Cloud, Xeon E7 v1 machines are configured to run HANA, and you buy this just as you would any other infrastructure cloud service. (You can see the initial configurations here.) The entry configuration comes with 128 GB of memory for HANA and applications and 1.28 TB of disk capacity for application storage and costs $1,595 per month. You keep doubling the memory and capacity up to get larger configurations, and the price doesn't quite double as you do so. A large configuration comes with 1 TB of main memory and 10 TB of disk and costs $6,495 per month. Sikka says that SAP can provide HANA server slices that scale up to 10 PB if customers request it. Obviously, the SAP Cloud has to have that much spare iron installed to deliver this, and no one is suggesting SAP has several hundred machines around on which to support an uncompressed 10 PB database.
To give a sense of what this infrastructure cloud costs compared to actually buying the hardware, Vishal Sikka, chief technology officer at SAP and the person driving the HANA effort, together this table for the launch of SAP Cloud. This is for systems based on the new Xeon E7 v2 processors rather than on the older Xeon E7 v1 chips:
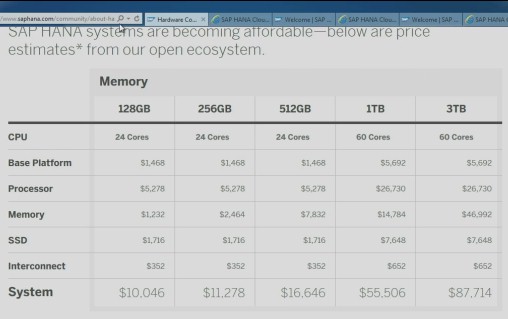
SAP, which has been aloof about publishing pricing for its software for decades, is putting out prices for cloud versions of HANA, and this is something it has to do to ease the sales cycle. It cannot personally negotiate every cloud deal with a sales rep. No cloud vendor can.
Sikka says that customers who already have HANA licenses can move them to the SAP Cloud if that suits them better, and they can move them back to on-premises equipment if that makes sense further down the road. Licenses can move back and forth between cloud and on-premises fluidly. It is not clear if licenses can move fluidly between the SAP Cloud and the similar AWS HANA service or between on-premise setups and HANA in the AWS cloud.
Aside from published pricing for HANA software, SAP is also breaking HANA down into consumable chunks so customers do not have to buy the whole stack at once. The HANA Base Edition in-memory database comes with partitioning, compression, and the base rules engine and it costs $4,595 per month on the base 128 GB configuration (presumably with ten cores), so that means the base HANA software itself costs $3,000 on that machine. The HANA Platform Edition setup has the advanced engines for planning, geospatial, predictive, graph, text search, and text analytics as well as Hadoop integration and a predictive analytics library and a planning software development kit and costs $11,195 on that base hardware slice, and if you do the math, then the HANA Platform Edition license costs $9,600. Remember, these are monthly charges.
On the largest 1 TB configuration, if you do the math, then HANA Base Edition costs $24,000 per month and Platform Edition costs $76,800 per month. Presumably this is on a 40-core system. And as you can see, the cost of the database software dwarfs the cost of the hardware on these larger configurations.
Above and beyond this, SAP is peddling HANA App Services on top of this database stack to integrate applications with mobile applications, provide collaboration tools for development, security and systems management, and other features. These features also allow third party companies to sell their own HANA-based applications on the HANA Marketplace, which also opens today. One of them, by the way, will be SAP's own Genomics Analyzer, which is used to speed up alignment, annotation, and analysis of genetic data to try to make correlations faster between participants in clinical studies.

SAP CTO Vishal Sikka
In one example, rather than taking months to cross-check gene snippets for diabetes research on a few dozen participants, the Genomics Analyzer running in HANA was able to handle 125 variants on 625 people in a matter of minutes. An early result from this test, which is getting ready to be published, is that the geographic region that you are from is a bigger determinant in the possibility of getting diabetes than other factors such as diet and exercise.
The point that SAP is trying to make is that HANA is not just a database, and it is not just about supporting SAP ERP applications, but rather is a full-on application development platform.
The press event was not just about the pricing and packaging for HANA online, or SAP showing off that it had paid the Beach Boys to do a remake of one of their most famous songs into Help Me HANA for the event. SAP also wanted to show off how far SAP could scale HANA if customers needed more.
To that end, SAP has created a data warehouse setup weighs in at 12.1 PB and it runs on a fairly modest collection of hardware by scale-out standards. It is not clear what the definition of a data warehouse is that is being used by Guinness, but as EnterpriseTech has reported, Facebook operates a data warehouse with tens of thousands of server nodes and over 300 PB of data. Telecommunications and media research companies have generally also had very large data warehouses on the scale of the systems that SAP is touting. That said, for all but the largest enterprises, 12.1 PB is still a lot of data.
On a webcast announcing the data warehouse record and the tweaks to the HANA in-memory database offerings, Vishal Sikka, chief technology officer at SAP and the person driving the HANA effort, said that this particular setup was "multi-temperate," by which he means that hot data is stored in HANA and cooler data is stored in SAP IQ database, formerly known as Sybase IQ and one of the early columnar databases to come to market.
The data warehouse cluster that SAP built was comprised of 25 servers from Hewlett-Packard, and because the setup ran HANA, it has to be a server that uses a Xeon E7 chip from Intel because these are the only processors that are certified to support HANA. SAP didn't wait for the new "Ivy Bridge-EX" Xeon E7 v2 iron to come out to do its test, but rather went with the prior generation of Xeon E7 v1 systems that it had in a lab in Palo Alto, California that it shares with Intel. These machines are a bit long in the tooth, but they still do the job. Specifically, SAP configured up HANA and SAP IQ on four-socket ProLiant DL580 G7 servers using one variant of the E7-4800 v1 processors. Which processor and the exact memory and storage configuration was not available at press time. The HANA servers were configured with SUSE Linux Enterprise Server 11 and the SAP IQ servers were running on top of Red Hat Enterprise Linux 6.4.
The setup had 20 of NetApp's E5460 storage arrays linked to the servers using 8 Gb/sec Fibre Channel switches.There were four HANA nodes plus one hot spare, plus 20 nodes running SAP IQ in this test setup. To federate the databases to provide cross-search capability as well as data integration and migration between the platforms, SAP chose the EDMT 9 data integration tools from BMMSoft. This tool is used to federate repositories of email, documents, multimedia files, and transactional databases, from whence it gets its name. The current release of HANA and SAP IQ 16 were installed on the cluster, and it is not clear if all the nodes ran both bits of software or if the nodes were dedicated to either HANA or SAP IQ. The dataset that SAP loaded up and is testing on the machines right now is half structured and half unstructured data, and across both databases SAP was able to achieve a 4 to 1 compression ratio. This, says SAP, models the kind of data mix it typically sees at enterprise customers these days.
Performance testing is now being done on this setup, and results will be published in the coming months, according to a blog post on the data warehouse.
Sikka reported that SAP itself has moved its internal ERP systems, based on its own code of course and supporting 67,000 end users, to run on top of the HANA in-memory database. The databases behind the ERP system have been compressed by a factor of seven, Sikka said, and added that usage by end users is up by 30 percent. He did not give statistics on how much faster transactions were being processed after the move to HANA.






