



Facebook Adds Retro Relational to Massive Hadoop Analytics
If there is one lesson that all extreme scale system designs teach us over and over again, it is that you have to tailor the system for the specific job.
You can't make a general-purpose machine scream with performance. Instead, you have to pick the right tools for the job and you have to tune them up. This is precisely what social media giant Facebook has been doing with its massive Hadoop infrastructure, and this philosophy has led the company to a kind of heresy in adopting relational database technology for some of its analytics work.
This has been something of a shock to many of the Hadoop enthusiasts at Facebook, Ken Rudin, head of analytics at the company, explained to EnterpriseTech in an interview at the Strata/Hadoop World conference in New York this week. Rudin also gave a keynote address that explained how relational database technologies fit into Facebook's analytics infrastructure and admonished the Hadoop faithful that the important thing was to get the right tool for the job, not get bogged down in the technology, make insights from data, and then follow through and make an impact on the business based on those insights.
Rudin knows a lot about relational database technologies and jokingly referred to himself as a "born again SQL fan." Back in the late 1980s, he led the team at Oracle that created the PL/SQL programming language for Oracle's relational database, and then he moved on to lead the team that created Oracle Parallel Server, the parallel implementation of Oracle's databases designed for data warehouses. Rudin left Oracle in the mid-1990s to run his own database consultancy, and then joined Salesforce.com to head up products and engineering. He ran marketing for Oracle's Siebel customer relationship management business for a few years, launched another startup, and then was vice president of analytics and platform technologies at online game maker Zynga for several years. Rudin joined Facebook in his current capacity running its massive analytics operations in April 2012.

Ken Rudin, head of analytics at Facebook
Facebook has over 1 billion users, and it has tens of thousands of servers in each of its three major and self-designed datacenters – the exact number has not been divulged, but it is very likely north of 100,000 machines, which are used for running PHP front ends, Memcached caching software, backend databases for the content on the site, and massive photo archives that hold exabytes of data. The analytics engine that drives the site as well as the advertising operation that gives Facebook the bulk of its revenues is also massive.
"It's big," Rudin tells EnterpriseTech. "It is tens of thousands of nodes, and the latest metric we have is that the data warehouse has 300 petabytes, which is also kind of big. That is just the data we analyze. It doesn't include the actual posts that people do, or the photos that they upload. This is really just the analytic data."
Think about this for a second. Facebook probably has over 100,000 servers and has tens of thousands of machines just to store analytics data from those systems and chew on it.
Facebook runs its own heavily modified version of Hadoop, which has been extended so the Hadoop clusters can span multiple datacenters and yet act as one cluster to the analytics users. Facebook would prefer to have all of this data in one giant Hadoop cluster, but this is not possible. So the extensions that Facebook has come up with are kind of like NUMA clustering in multi-socket servers: Facebook has figured out what kinds of data tend to get queried together and then co-locates this information in one of the datacenters so when queries are run, the majority of the time they are being run against the HDFS file system in that single location.
"The source of truth is our Hadoop system, and it runs HDFS, and a MapReduce layer on top of that, there is Hive relational layer on top of that, which was created at Facebook," explains Rudin. "We have come up with a new relational layer called Presto, which is a lot like Impala from Cloudera. Presto basically pulls out the MapReduce layer, splitting Hadoop into two parts. So you have got HDFS as the file structure and MapReduce is the traditional way you get to that data. But MapReduce is really a way to get to HDFS, it is not the way. You can get to HDFS through a true relational engine, and that is what Presto really is. It is used very broadly internally and it is a very fast true relational engine."
Facebook created Hive to add SQL-like functions to Hadoop because it could not wait for the commercial Hadoop distributors to do it, and the same hold true for Presto. With Cloudera working on Impala and EMC (now Pivotal) working on Hawq to bring true SQL querying to HDFS, you might be thinking that Facebook could have waited for these projects to come to fruition.
"First, we can't wait, and second, most things that other people build don't work for us just because of the scale," says Rudin. "It is not that we are better engineers and that we can build things that scale further than they can. A lot of the ways we make things scale is by cutting out the things we don't need. The other relational products include things that their entire customer base needs, so they have to have a broad range of capabilities. Each time you add more capability, you are adding a little bit more overhead. We can get our systems to scale much higher because we just cut all of that out. We would rather have something that works well enough than wait for an industrial-strength version of something eighteen months later because that, for us, is an eternity. We tend to break everything we bring in house because it collapses under the weight of the data we put on it."
In cases where Presto is not fast enough, Facebook has created an in-memory database cluster called Scuba. This runs on hundreds of Open Compute servers, each equipped with 144 GB of memory, and it is ingesting data to the tune of millions of rows per second from Facebook's code regression analysis, bug report monitoring, ad revenue monitoring, and performance debugging systems. The Scuba system runs nearly 1 million queries per day.
"The biggest challenge that we have is that everyone wants to run everything on Scuba," says Rudin. "And there is a process to figure out what we really should be running on Scuba."
But even with all of this innovation, Facebook has gone to an outside – and unnamed – vendor for a data warehouse underpinned by a good, old-fashioned relational database.
Rudin is not at liberty to say which vendor is supplying the data warehouse, but says it comes from "one of the more common names out there that does the big data warehousing kinds of stuff." When EnterpriseTech suggested that it could not be Microsoft's SQL Server, he confirmed that it was indeed not SQL Server after chuckling a bit. A betting man would put down cash on Teradata, or maybe Oracle given Rudin's background.
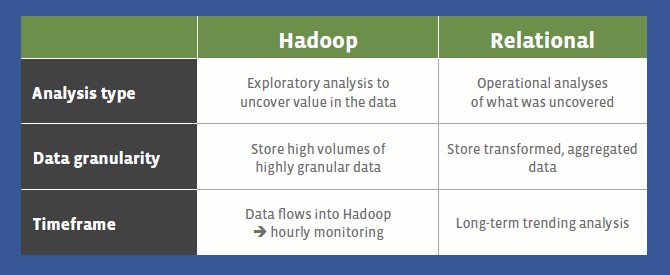
"Way back when the company was just getting started, Facebook was relational," explains Rudin. "The interesting part was when Facebook got serious and started using Hadoop. And we have found that Hadoop is not optimal for everything – and in retrospect that is an obvious conclusion. But there really was an attitude internally, fed by what is going on in the industry as well, that relational has had its day in the sun and everything now needs to move to Hadoop. It is just faster and better, more flexible with no rigid schemas, and so on. We bought into this quite a bit and it took us very, very far, and we could not have gotten to where we are today if we had stayed purely on relational. But every day we want to look at daily and monthly active users by geography and by the type of phone they are using, and Hadoop – particularly with MapReduce – was designed as a generic parallel processing framework and is not optimized for doing these kinds of queries. When you run these traditional business queries – which are not going away – that is the kind of query that relational was optimized for."
There may, however, come a day when Facebook moves such queries to Presto, and the company talks about that internally.
"We had this big discussion about whether we should be using Presto for this," Rudin admits. "The practical reality is that Presto is new, and it can't handle ten petabytes of information and run these complex queries on it – just yet. It is not ready for that level, but it probably will be within a year and half. And at that time we will see. If the relational system that we bought still excels over Presto in many ways, we will continue to use it."
What Rudin is advocating for is the idea that big data means using Hadoop, relational databases, in-memory databases, and any other technology that might be applicable without any kind of chauvinism. And as for SQL and relational databases, this is the query language of business and so many people know it that it is not practical to try to teach them something else.
"That almost sounds like you want to get away from SQL, but you can't," Rudin said when EnterpriseTech suggested that this is a big issue. "I am not even sure you want to get away from SQL. For the types of questions it is good at answering, it is the best way of answering those questions that I have seen so far. This notion of no SQL really took hold, and I hope that we as an industry are really over it. I have never seen anyone that is not using Hive with Hadoop, and that is SQL. Yes, it is converting it to MapReduce, but it is still SQL."
The other thing that Rudin is evangelizing for within Facebook, and now the industry at large, is to get analytics in the hands of as many employees as possible. About half of the employees at Facebook run queries against that 300 PB data warehouse stored in HDFS and surrounded by the Presto, Scuba, and relational data warehousing systems.
The way that Facebook is doing that is interesting. The company has started two week boot camps for employees, getting more and more people trained to use its array of analytic tools. The company has also experimented with various organizational structures to get analytics embedded in every business team.
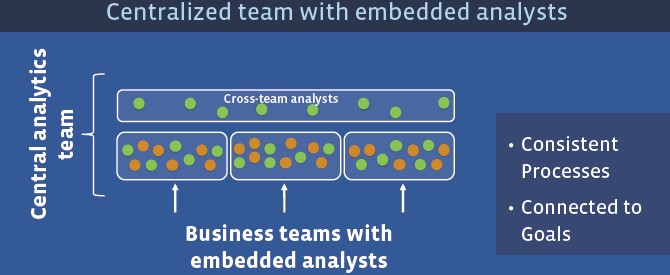
In a centralized hierarchy, analysts sit above the business teams and they are reactive to those teams, not proactive. In a decentralized organizational structure, where you embed analysts with the business teams, you get better analytics, but you also end up with redundant efforts across those teams and inconsistent approaches to solving similar problems. So Facebook takes a hybrid approach, embedding analysts with the business teams but also having cross-team analysts that make sure Facebook has consistent processes while at the same time ensuring their work is connected to the goals of their individual teams.
"My analytics team is trying to work itself out of a job. We will become the SWAT team for analytics, but everybody else should be fluent in how to use data to do their jobs better."
Here's a good example where you can only do your job at Facebook if you use analytics. The company has over 1 million advertisers, but only several hundred advertising salespeople. How do they figure out who to call to sell more ads? You need to identify who is a really good prospect and separate them from those who are just spamming to try to sell Viagra. If you reach out to those who have already spent a lot, that is probably not the best tactic.
But the most important message Rudin had was for analysts to make an actual impact, and he said it best at the end of his keynote: "You need to own the outcome. You need to use data to move the needle. It doesn't matter how brilliant our analyses are. If nothing changes, we have made no impact. If nothing changes, then it doesn't even make a difference if you work at that company. You have to hold yourself accountable and make sure that your insights actually lead to an impact."






