



Prompt Engineer: The Next Hot Job in AI

Technology professionals who want to catch the hottest wave in AI at the moment may consider becoming prompt engineers, which appears to be one of the most in-demand professions for 2023. And developers who want to get the most out of large language models such as ChatGPT may want to check out prompt engineering tools, an emerging category of tools designed to direct the LLM toward a desired outcome.
Launched just over two months ago, ChatGPT has caught the business world’s attention for the compelling and detailed written responses it can give to questions. While there are concerns about the accuracy of the information it generates in response to the prompts it’s given, businesses nevertheless are moving quickly to incorporate LLMs into all manners of customer communication.
LLMs have been on the AI scene for a few years, and developers are still exploring the best ways to interact with them. While some LLMs are small enough (not to mention open source enough) for developers to download them and train them on their own data, such as BERT, that’s just not possible with some of the bigger LLMs, such as GPT-3. These LLMs are trained and hosted on the cloud, and developers typically interact with them via APIs.
Instead of training these types of deep learning models on custom datasets, as many companies have done with traditional machine learning and early deep learning approaches, building custom AI applications with a pretrained LLM looks decidedly different. In fact, some LLM experts say you can throw out all the classic data science training when working with LLMs like GPT-3.
So, how do developers build applications with LLMs? The answer is rather new field called prompt engineering. Instead of building and training a machine learning or deep learning model, prompt engineers typically work with pretrained LLMs hosted on the cloud. Getting the LLMs to behave correctly and generate the appropriate response is the name of the game, and prompt engineers do this by manipulating the input that is fed into the LLM, or its prompt.
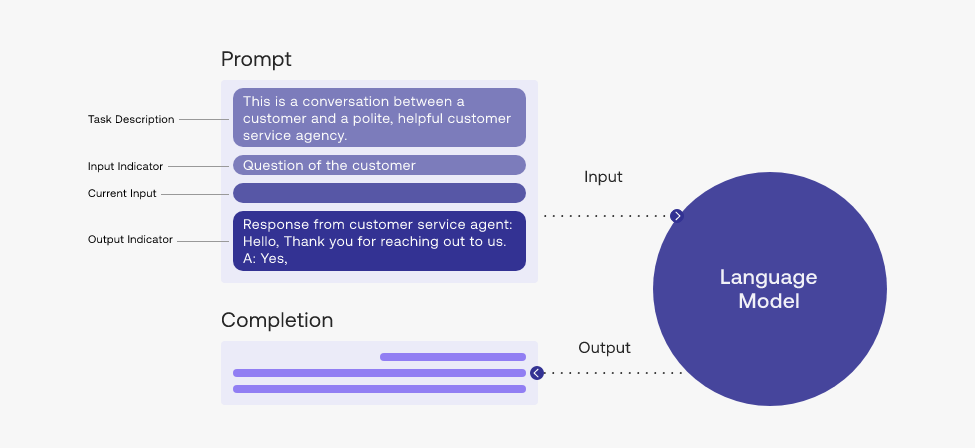
Prompt engineering is about manipulating the input to a LLM to get the desired response (Image courtesy Cohere)
According to Cohere, one of the earliest and most successful developer of tools for natural language processing (NLP) and LLMs, a successful prompt engineer will find a way to guide the model to generate useful output. One way to do this, the company explains in its guideline for prompt engineers, is to try multiple formulations of a prompt. “Different formulations of the same prompt which might sound similar to humans can lead to generations that are quite different from each other,” the company says.
Showing the LLM examples of the output you would like to see, also called few shot learning, is one of the techniques that prompt engineers use with their models, Cohere says. Changing the context of the prompt is also important, the company says. This is important to discover “particular words, phrases, or structures that the model has trouble understanding,” Cohere says.
One of the big benefits of prompt engineering versus traditional model training is that prompts can be changed as needed in real time, says Josh Tobin, the founder and CEO of Gantry, which develops machine learning tools.
“When you train a model, you’re doing this on historical data, so there’s always a lag between when you see the data and when that data is incorporated into the models’ weights,” Tobin tells Datanami in a recent interview. “But with this context engineering approach, part of what people are calling prompt engineering…[you can] change that on the fly in response to user behavior, in response to application state, and in response to really anything else, in a way that you just can’t really do if you’re actually training models, because that’s just too slow.”
While traditional data science and machine learning engineering is not going away any time soon, the rise of LLMs has spurred a rush for folks who are prompt engineers. The position is so new that Tobin, a former OpenAI researcher, jokes that there are perhaps two people in the world who identify as prompt engineer.
Indeed, the position is so new that job boards haven’t adapted to it yet. ZipRecruiter rejects it as an invalid job title, and CareerBuilder consider it a quality of engineers (as in “being prompt to showing up for work”).
Prompt Engineering Tools
In addition to new techniques, prompt engineers use a new class of tools. These prompt engineering tools (for lack of a better name) are designed to help the developer automate the tasks involved in prompt engineering as they build chatbots, autonomous agents, or other generative AI applications.
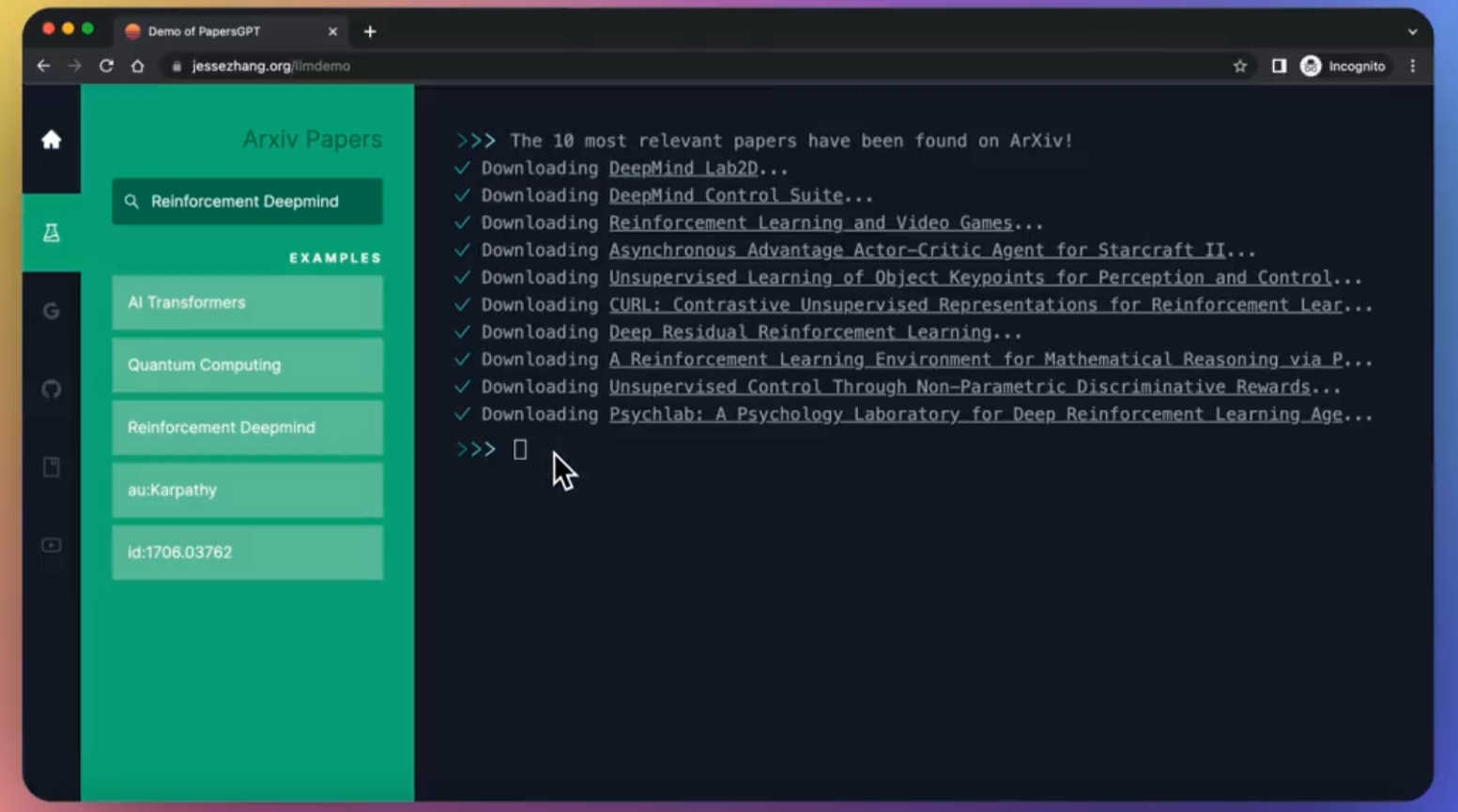
PapersGPT was created by Jesse Zhang using GPTIndex (Image courtesy Jesse Zhang)
LangChain is one of the more popular prompt engineering tools. According to its website, LangChain includes six modules for tasks such as automating management of prompts (the input you give to the LLM); handling document loaders; creating conversational AI agents; chaining sequences of events together; and persisting state between calls of chains and agents.
Another popular prompt engineering tool is GPT Index, which is designed to be “a simple, flexible interface between your external data and LLMs.” One of GPT Index’s goals is to help the user “feed knowledge” to the LLM. However, LLMs such as GPT-3 Davinci have a limit of 4,096 tokens (a token is a word or a word fragment that is used as a prompt for the model).
GPT Index helps developers get around those limits by providing optimized data structures that allow them to easily connect their external data to an LLM, such as GPT-3. After generating the optimized data structure (or index), the user can then use the index to query the LLM.
Text-to-image prompting is also gaining steam as a way to automatically create novel images using generative models like DALL-E, Stable Diffusion and Midjourney, and prompt engineering is finding a place here, too.
As generative AI gets better, the ways that developers interact with AI is changing. That’s particularly true with few shot learning, in which a model requires just a few examples of what the user is looking for before it can behave in the appropriate way.
Few shot learning “takes advantage of the latent knowledge in these models,” Tobin says. “In many cases the models are able to generalize really relatively well from that.”






