



Google Creates AI that Can Generate Music from User Text

Google researchers have created an AI that can generate music based on a text description provided by a user.
Research on the Noise2music program, which was published last week and is still in its early days, adds a new dimension to what conversational AIs can do.
Users can already request AIs like DALL·E 2 to generate images based on simple text descriptions. ChatGPT can generate full answers, write essays or even generate code based on a user’s request.
The Noise2music AI can now generate customized sound at a user’s request.
It has been a busy month for Google, which is rushing to commercialize its AI research after being upstaged last week by Microsoft, which is putting AI technology from OpenAI into its products. OpenAI created ChatGPT conversational AI and the image-generating DALL·E 2.
The Noise2music research uses the same large language model called LaMDA, which Google used for its Bard conversational AI, which the company plans to incorporate in its search engine.
Google announced Bard last week after Microsoft's surprise announcement that it was incorporating a ChatGPT-style chatbot in its Bing search engine. Google had largely kept its major AI projects away from public view, though it has published research papers.
Some other major Google AI projects include Imagen, which can generate images and video based on text descriptions, and PaLM, which is a large language model with 540 billion parameters.
Large language models run on the Transformer architecture, introduced by Google in 2017, which helps tie together relations between parts of sentences, images, and other data points. By comparison, convolutional neural networks look at only immediate neighboring relationships.
The Google researchers fed Noise2music hundreds of thousands of hours of music, and attached multiple labels to the music clips that best described the audio. That involved using a large-language to generate descriptions that could be attached as captions to audio clips, and then using another pre-trained model to label the audio clip.
The LaMDA large-language model generated 4 million long-form sentences to describe hundreds of thousands of popular songs. One description included "a light, atmospheric drum groove provides a tropical feel.”
"We use LaMDA as our LM of choice because it is trained for dialogue applications, and expect the generated text to be closer to user prompts for generating music," the researchers wrote.
The researchers used the diffusion model, which is used in DALL·E 2 to generate higher-quality images. In this case, the model goes through an upscaling process that generates higher-quality 24kHz audio for 30 seconds. The researchers generated AI processing on TPU V4 chips in the Google Cloud infrastructure.
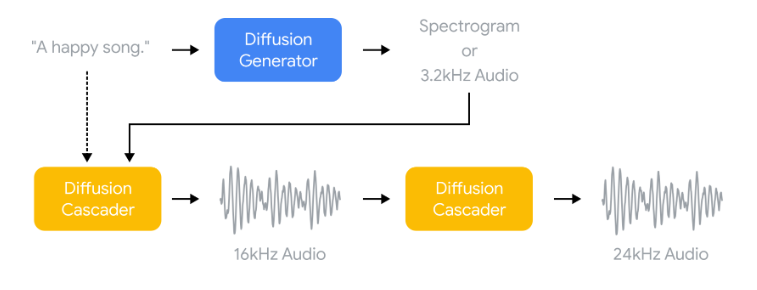
Noise2Music End-to-End Diffusion depiction (Source: Google)
The researchers posted sample audio generated by the Noise2music AI on Google Research's Github website. EnterpriseAI ran the audio clips through song recognition application Shazam, and the app couldn't recognize any clip as an existing song.
The researchers noted that there is much work to be done to improve the music generation based on text prompts, and one direction for this AI could be "to fine-tune the models trained in this work for diverse audio tasks including music completion and modification," the researchers noted.
The improvements may need to be done with the help of musicians and others to develop a co-creation tool, the researchers noted.
"We believe our work has the potential to grow into a useful tool for artists and content creators that can further enrich their creative pursuits," the researchers noted.






