



Xilinx Keeps Pace in AI Accelerator Race

FPGAs are increasingly used to accelerate AI workloads in datacenters for tasks like machine learning inference. A growing list of FPGA accelerators are challenging datacenter GPU deployments, promising to unburden already overworked CPUs in datacenter servers.
Earlier this month, Intel (NASDAQ: INTC) launched its Stratix 10 NX FPGA with an eye toward AI model training and inference. Xilinx (NASDAQ: XLNX) has countered with validation of its Alveo FPGA running on VMware’s vSphere cloud computing virtualization platform.
VMware used a Xilinx Alveo U250 accelerator card for the test, provisioning machine learning models via Docker containers incorporated with the FPGA maker’s new Vitis AI development stack for machine learning inference. The open source stack supports Caffe and TensorFlow frameworks.
The partners reported this week that low-latency performance for machine learning inference was “nearly identical” between virtual and bare metal deployments.
Using a Direct Path I/O configuration, the FPGA was accessed by applications running inside a virtual machine. That setup bypassed the hypervisor layer to boost performance and reduce latency
“The testing validates that the performance gap between virtual and bare metal is capped at 2 percent, for both throughput and latency,” Xilinx noted in a blog post describing the results of the vSphere test.
“This indicates that the performance of Alveo U250 on vSphere for [machine learning] inference in virtual environments is nearly identical to the bare-metal baseline.”
Xilinx and FPGA competitor Intel are promoting their latest datacenter accelerator cards as meeting growing enterprise demand for heterogenous architectures and performance boosts as customers run more AI workloads. Along with reduced latency, FPGAs are promoted as reducing costs associated with underutilized silicon capacity in general purpose CPUs.
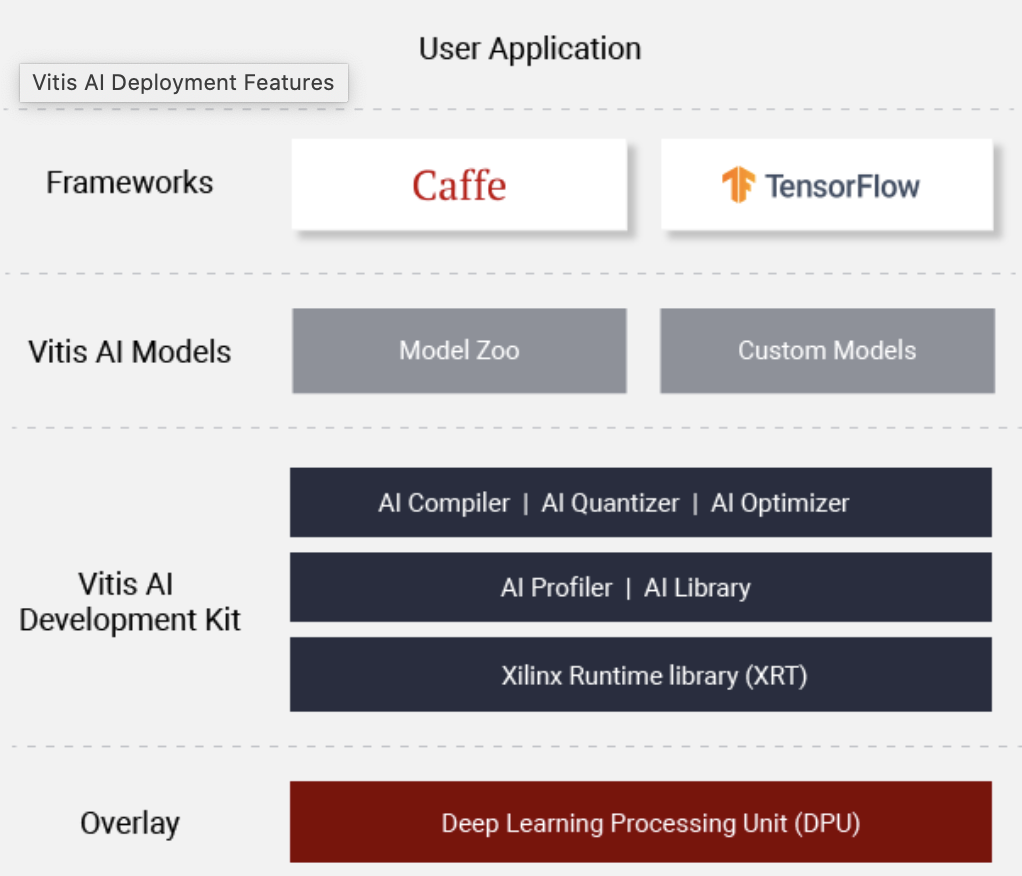
Xilinx Vitis AI Toolkit
FPGAs are gradually moving into the mainstream to challenge GPU accelerators as new tools emerge to ease FPGA programming and development.
The Vitis AI tool from Xilinx, for example, is positioned as a development platform for inference on hardware ranging from Alveo cards to edge devices. Vitis includes chip IP, tools, libraries and models designed to speed AI inference.
Along with an “AI model zoo,” the toolkit includes features like an “AI optimizer” designed to compress models by up to 50-fold to boost AI inference performance. Meanwhile, a profiler tracks the efficiency and utilization of inference implementations while the AI library runtime includes C++ and Python APIs for application development.
The Xilinx AI inference development stack is available on GitHub.
Meanwhile, rival Intel is following a similar path toward heterogeneous computing with its Stratix 10 NX introduction. The chip maker’s strategy also includes hardware and software integration, along with the integration of standard libraries and frameworks used in application development.






