



Mesosphere Wants To Run Clusters At The Global 2000
A few years back, search engine giant Google invented a term called warehouse-scale computing to talk about the hyperscale that it operates its applications within. That term never really caught on, but the idea of operating applications across large clusters of machines as if they were one single machine has persisted. To do so requires another level of abstraction up from servers, storage, and networks, something that we could properly call a data center operating system.
Such a stack of software is what VMware is talking about when it describes its Software Defined Data Center, a collection of its server, storage, and network virtualization middleware coupled with orchestration and monitoring software to allow multiple workloads to be scheduled across virtualized clusters. In the hyperscale world, some work runs on bare metal and some within software containers or full-on hypervisor server slices, so the uber-operating system that controls all of this has to be able to manage the various ways that distributed applications are spread across servers and networks. As it turns out, large enterprises have a similar mix of bare metal and virtualized applications, and it is the upper echelon of the Global 2000 in particular that Mesosphere is targeting with its new Mesosphere Data Center Operating System, which launches in beta today after several years of development.
As EnterpriseTech has previously reported, Mesosphere’s DCOS draws its inspiration from the internal cluster management and job scheduling programs at Google, known as Borg and Omega. The Mesos project, which is one of the many open source projects under the Apache Foundation that have transformed modern information technology, on which the Mesosphere DCOS is based got its start at the University of California at Berkeley several years ago when researchers were trying to figure out how to run software on multicore processors more efficiently. As it turns out, when you solve job scheduling issues on a multicore processor, the same techniques can be used to schedule work across clusters. The fundamental idea with Mesos is not to partition a cluster into server node chunks and try to run jobs on specific nodes, but rather to run multiple jobs in parallel, side by side, on the nodes in the cluster. The idea is to drive up the utilization as high as possible on all of the nodes in the machine, to think at the datacenter level instead of at the node, rack, or cluster level.
Mesopshere, the commercial entity formed to bring a supported version of Mesos to the masses, was founded by Tobi Knaup, a software engineer at Airbnb who created its search and fraud detection systems and the Marathon framework for Mesos, and Florian Leibert, who built the search and analytics systems at Twitter and then moved to Airbnb where he, among other things, created the Chronos fault tolerant job dependency scheduler that runs atop Mesos. Leibert is the company’s CEO, and Matt Trifiro, who was chief marketing officer at platform cloud provider Heroku, is senior vice president in charge of marketing. Ben Whitehead, who built distributed systems at Goldman Sachs, has been tapped to work on backend tools for Mesos. Tim Chen, a committer on the Apache Drill ad-hoc query system that complements MapReduce batch processing on Hadoop, is also on the Mesosphere team, and most recently Benjamin Hindman, who founded the Mesos project while at UC Berkeley and who worked on it further at Twitter, and Christos Kozyrakis, an expert on cloud and job scheduling software at Stanford University, have joined Mesosphere.
“Treating a datacenter like a bunch of different machines is a really broken concept,” says Leibert. And the early adopters of the code, who have driven the Apache Mesos project, agree. The Mesos software that is at the heart of the Mesosphere DCOS has been put into production already at eBay, PayPal, Groupon, Netflix, OpenTable, HubSpot, Salesforce.com, Vimeo, Conviva, and Best Buy, just to name a few companies who admit to putting it into production even though Mesosphere is only now getting early release code ahead of its commercial launch early next year.

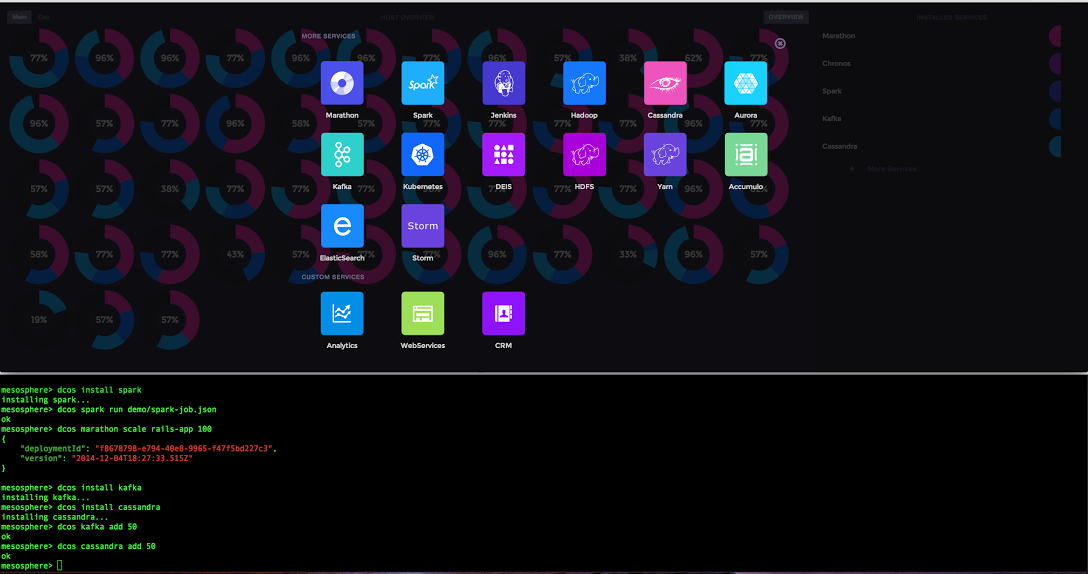
Trifiro says that Mesosphere DCOS is not only a true operating system, but the first new one that the IT industry has seen since the launch of Android, for smartphones and tablets, by Google seven years ago. What makes Mesosphere DCOS an operating system? Well, it has a user interface, it has a software development kit for building new applications, it has applications in a repository that were created to run at scale and that can be deployed as easily from that repository as download an application for a PC or smartphone, and it runs on any private infrastructure that has a Linux operating system or the major public cloud providers. To be specific, Mesosphere DCOS is officially supported on bare metal machines running Red Hat Enterprise Linux and its CentOS clone, CoreOS, or Canonical Ubuntu Server. It is supported on VMware’s ESXi hypervisor and any private clouds that are based on this abstraction layer as well as on the VMware vCloud Air public cloud. It is also supported on public and private clouds that run the OpenStack cloud controller and the KVM hypervisor and is supported on the Amazon Web Services, Microsoft Azure, Google Compute Engine, Rackspace Cloud, and DigitalOcean public clouds.
The heart of this DCOS stack is the Mesos kernel, which acts as a traffic cop between applications above and hardware below just like a kernel of an operating system does on a single server node. This Mesos kernel starts and stops applications, and it runs on every node in the cluster, abstracting the compute, memory, storage, networking, and other resources of its server nodes. The allocator portion of the kernel presents all of these resources across the nodes in a cluster as a single pool of resources, and a containerizer can allocate software into those resources in Docker or LXC containers or inside of ESXi or KVM virtual machines. The Mesos stack includes Marathon, which is analogous to the Init system in a Linux machine; it provides a framework to launch applications and a means for controlling how applications scale across the cluster. The Mesos cluster ensures high availability by running multiple copies of its application scheduler across the cluster and also running multiple copies of applications if this is warranted by required service levels. Marathon has a REST API stack so it can be controlled programmatically as well as a graphical user interface. For those who want to use the new Kubernetes Docker container system as their cluster Init, this also plugs into the Mesos stack. The Chronos element of Mesos is used to run short-lived applications onto of the cluster operating system, analogous to the cron scheduler in Linux; it has a command line and a GUI to suit both types of users. Marathon and Chronos are broader frameworks, and they can be used to launch any conventional Linux application, such as a relational database. But generally speaking Marathon is used to launch long-running applications and Chronos for short-lived ones.
For storage, Mesosphere DCOS has the Hadoop Distributed File System (HDFS) installed by default, and this stands to reason since so many of the modern distributed applications that will initially be deployed at scale depend on HDFS for their storage. Applications run on frameworks in Mesos, of which Marathon is but one. The application frameworks currently supported are for Hadoop and its MapReduce job scheduler; the next-generation YARN job scheduler is also supported. There are Mesos frameworks for the Cassandra distributed database, the Accumulo distributed key-value store, the Spark in-memory system that is often used as an add-on for MapReduce, the Kafka distributed messaging system, and the Storm streaming system.
But don’t think that the Mesosphere DCOS is just limited to this set of applications. The Message Passing Interface (MPI) protocol commonly used with parallel supercomputing workloads is supported as a framework atop the Mesos kernel, too.
“You can run MPI on top of Mesosphere today,” Leibert tells EnterpriseTech. “You could also start a Lustre cluster on top of Mesosphere using static reservations in order to guarantee access to any state you persisted via local storage. The plumbing of this is implemented by Apache Mesos. We do have some early adopters that have been using Lustre with Mesosphere. The advantage of using HDFS on Mesosphere today is that it takes advantage of the Apache Mesos primitives in order to better handle failures and datacenter/machine maintenance. That way, you don’t need to use static reservations, which can significantly simplify management.”
Mesosphere DCOS is in beta testing right now with “lighthouse” customers, says Leibert and the company is targeting general availability for sometime in the first quarter of 2015. At the moment the plan is to offer Mesopshere in two versions. The Community Edition will have the complete stack of Mesos software and frameworks, and will be distributed for free. The Enterprise Edition will include some goodies aimed specifically at those Global 2000 customers that they will want to pay a premium for, and Mesosphere is not outlining all of these features until the product launch in early 2015. But, Leibert did give a few examples of the kind of feature that would be in the Enterprise Edition and carry a subscription license. One will be a more sophisticated security system than is available in the Community Edition, and another is an augmented application scheduler that is being developed by Kozyrakis that employs machine learning techniques to squeeze maybe 10 percent to 15 percent more performance out of a cluster.
“Any feature whose absence would hinder the adoption of Mesos is free, and any feature that would really only be of benefit to the Global 2000 customers will have a license,” Leibert explained. Mesophere is, by the way, partnering with DataStax to offer commercial support for Cassandra and TypeSafe and DataBricks for supported versions of Spark. The idea is to partner with the official commercializer of any distributed application or framework and then if there is not one, then to provide community support until one is created. (As just happened a few weeks ago with Kafka, for instance.)
Mesosphere is not talking about pricing yet, but Leibert says that the “pricing will be expensive but fair compared to the value it delivers.” Being able to fire up a Hadoop cluster with one command is a pretty valuable bit of code, and so is automagically being able to scale the cluster up and down as needed. Being able to run multiple jobs side-by-side on the same cluster instead of on distinct clusters is also a very valuable thing. How valuable remains to be seen because, quite frankly, no one has done this well as yet. The market will decide. But the idea is to have a single admin run up to 10,000 server nodes and their applications instead of the couple of hundred in a typical enterprise datacenter, and so it will probably be quite pricey indeed given this and the fact that Mesosphere will take the place of workload managers, job schedulers, and other software that enterprises currently use to manage their systems and workloads.
The venture capitalists are willing to place some big bets on Mesosphere. The company also announced that it has closed its Series B round of funding at $36 million, a round that was led by Khosla Ventures, which was founded by Sun Microsystems co-founder Vinod Khosla. Andreesen Horowitz, Fuel Capital, SV Angel, and Data Collective kicked in funds this time around and in the $10.5 million Series A funding round back in June when the company formally launched. Twitter and Airbnb have also kicked in additional funding in the early days to get Mesos off the ground.






