



Nvidia Doubles Up Tesla GPU Accelerators

Those who have an insatiable appetite for floating point performance – and who doesn’t, really? – prepare for a new crunchy course of Tesla iron from Nvidia. As the SC14 supercomputer conference is opening in New Orleans, and Nvidia and partner IBM have just captured a deal to build two massive hybrid CPU-GPU supercomputers mixing Power and Tesla computing engines in 2017, Nvidia is rolling out a new twin GPU Tesla card called the K80 that crams more flops into the tight spaces of servers and, importantly, is available now and for all customers who create hybrid applications.
The Tesla K80 accelerator card is based on the “Kepler” family of GPUs that Nvidia has been shipping for nearly two years now. The earlier K series high-end Tesla cards were based on the GK110 GPU chip, the K40 was based on a variant called the GK110B, but the K80 is based on a pair of GK210 chips. This GPU is different from the GK110B GPU used in the Tesla K40 coprocessor in a few ways, including a doubling of the shared GDDR5 memory and registers in the chip. The GK210 also sports an improved GPU Boost overclocking mechanism that allows for the two GPU chips on the card to squeeze out the maximum performance given the thermal envelope of the systems in which they are tucked and the nature of the workload as it is running.
“It is an architectural tweak that improves the throughput of the GPU,” Sumit Gupta, general manager of the Tesla Accelerated Computing unit at Nvidia, tells EnterpriseTech. Each GPU on the doubled-up Tesla K80 card has 2,496 CUDA cores and a 12 GB block of GDDR5 memory for those cores to share as they chew on data. That gives a total of 4,992 CUDA cores, 24 GB of memory, and 480 GB/sec of memory bandwidth through a single accelerator card.

This is not Nvidia’s first dual-GPU card. The Tesla K10 card, aimed at workloads that predominantly do single-precision floating point math (think life sciences, seismic analysis, and signal processing) put two of the lower-end Kepler GK104 GPU processors on a single card. That GK104 GPU has hardly any double precision performance and does not support Dynamic Parallelism or Hyper-Q, two advanced features that dramatically boost the performance of certain parallel workloads. The Tesla K80, on the other hand, supports Dynamic Parallelism, which allows GPU threads to spawn their own threads as they work rather than having to ask permission from CPUs and which thus lowers the overhead on both the CPU and the GPU, and Hyper-Q, which allows the individual cores on the CPU to simultaneously dispatch work to the CUDA cores.
The new and improved GPU Boost is the secret sauce that allows for those two heftier GK210 GPU chips to be put on a single card, however.
“The K80 is rated to be a 300 watt board, but most applications running on the GPU are running at much lower power, and so the accelerator dynamically increases the clock speeds of the GPU and tries to give the maximum performance based on the application profile,” explains Gupta. “When the K80 first loads up, it actually is rated at 1.87 teraflops double precision, but its maximum GPU Boost performance is 2.9 teraflops.”
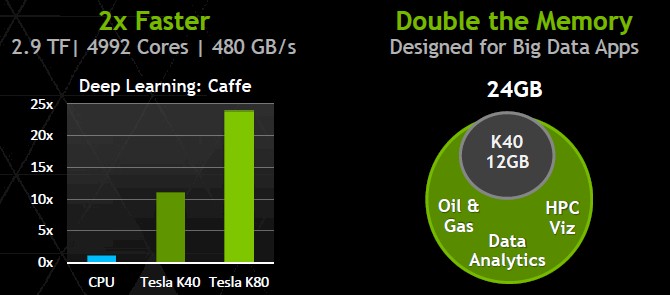
Incidentally, the Tesla K80 card is no slouch on single-precision floating point processing, either, coming in at 8.74 teraflops. The Tesla K40 card is rated at 1.43 teraflops double precision and 4.29 teraflops single precision, and the K10 with two GPUs is rated at 4.58 teraflops single precision. The Tesla K80 is the new winner for both double precision and single precision workloads in terms of raw performance, and importantly offers high performance on both kinds of floating point math in the same device.
The question, of course, is does the Tesla K80 offer the best performance per dollar and the best performance per watt per flops? Nvidia does not give out prices on its Tesla accelerators, leaving this to its OEM partners who bundle them into their systems. It is hard to guess. To one way of thinking, twice the flops should cost a little less than twice as much because the world likes a discount on volume, but to another way of thinking, if you can cram twice as much oomph into the same physical space in a datacenter, then you can charge a premium for that packaging. Moreover, having one device that can do SP and DP well should also command a premium.
What Nvidia is happy to talk about is the growing gap in floating point performance and memory bandwidth between CPUs and Tesla cards, which is illustrated below:
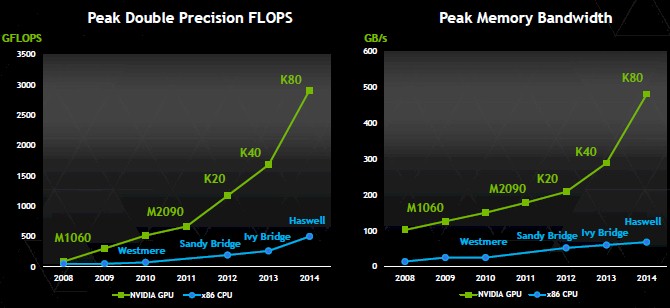
“This chart is one of the key things that our customers look at and realize that they need to be on the GPU bandwagon,” says Gupta. “They are just not getting enough of a performance boost, generation over generation, with CPUs. If you look at the GPU performance, we have continuously improved performance and, in fact, the gap is growing with every generation.”
Thus far over 280 applications in modeling, simulation, data analytics, machine learning, and other workloads have been ported to the CUDA environment so Tesla cards can accelerate them, and there are no doubt other internal applications that have been either ported to CUDA or created from scratch that Nvidia does not know about. To that end, Gupta showed off this chart, which has a slew of applications that are accelerated by a factor of 5X to 10X, and sometimes more, against twelve-core CPU.”

Specifically, the comparison above pits a single twelve-core E5-2697 v2 processor (that’s last year’s “Ivy Bridge” model) running at 2.7 GHz. This particular single-socket machine is configured with 64 GB of main memory and runs the CentOS 6.2 clone of Red Hat Enterprise Linux; then the K80 is slapped in it to run the tests again to show the acceleration. Again, to make a fair comparison, we need the pricing of configured systems and their power draw as they run these workloads.
By the way, a similar disparity exists between Power and Tesla compute and the gap is even wider between impending ARM chips and Tesla. And that is precisely the reason most of the industry believes that hybrid computing, with a mix of fast serial compute and energy-efficient parallel compute, is the future of the datacenter.
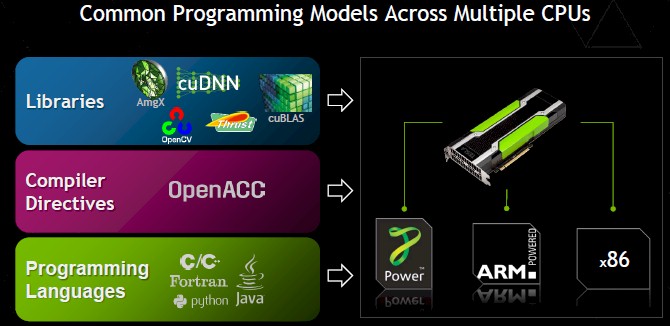
“The ecosystem around Tesla has really developed and it has become a platform and other people are building on top of our platform,” Gupta says. “There are libraries, applications, and software tools being built on top of Tesla. We build something like GPU Direct, and Mellanox Technologies goes and builds it into its InfiniBand. And so we see all of this activity and so Tesla has really become an accelerated computing platform with a whole range of hardware and software built around it.”
The important thing as far as Nvidia is concerned is that it has covered its processor bases, and will be leveraging its high-speed NVLink interconnect with Power and perhaps ARM processors soon. (You can read more about NVLink here, and we will be providing you an update on this technology later this week.)
“This is critical because the face of HPC is changing,” says Gupta. “A lot of our customers are looking at ARM64, and obviously IBM has come on strong with Power. The good news here is that our customers can use a single programming model across any of these CPUs.”
The other interesting thing that is happening as GPU acceleration moves from experimentation to production use in the supercomputing and hyperscale deployments, and to a certain extent among early adopters in the enterprise, is that a lot of customers want hardware and software that can support a higher mix of GPUs to relative to the CPUs in the systems. Early on, says Gupta, customers put one or two Tesla accelerators in a system, but now it is not uncommon for customers to want four or even eight GPU accelerators per system.

“The best indicator of this are the systems that OEMs design. All of the mainstream suppliers have a system that has four or eight GPUs per server.”
While the Tesla K80 card packs a wallop, the fact is we are not talking about the launch of the first Tesla cards based on the next-generation “Maxwell” GPUs, which were expected sometime around now.
“Today we have no new announcements around Maxwell,” Gupta tells EnterpriseTech. “Right now we are focused on Kepler with Tesla, and we are seeing growth with high performance computing, but we are seeing a huge growth with data analytics. We are seeing a lot of uptake for GPUs at the consumer Web companies and mobile service providers, and the Tesla K80 is a terrific upgrade for all of them.”
You might assume that, all things being equal, Nvidia would like to have the Maxwell GPUs in the field by now for Tesla cards. But perhaps not. Intel is not shipping its “Knights Landing” X86 accelerators until the second half of 2015, as we report elsewhere this week. Intel will no doubt put a lot of pressure on Nvidia in the fight for customer flops, but getting a dual-GPU Tesla K80 card into the field while Nvidia works the kinks out of the Maxwell GPUs and stays on course for its future “Pascal” and “Volta” GPUs is probably more important right now. Nvidia and IBM have sufficiently robust roadmaps to convince the US Department of Energy to spend $325 million on two systems, called Sierra and Summit, that could grow to more than 400 petaflops in the aggregate later in the decade, mixing Power and Tesla compute engines. About 90 percent of the floating point oomph in those systems is coming from Nvidia Tesla cards.






