



A Rare Peek Into The Massive Scale of AWS
The idea behind cloud computing, as pioneer Amazon Web Services believed when it launched its first utility compute and storage products eight years ago, is to abstract away the underlying hardware and provide raw resources to programmers for applications to run on. This hardware is a competitive advantage for AWS, as it has been for its parent online retailer, and that is why AWS very rarely talks about its datacenters and systems. But with Google, Microsoft, and IBM all talking up their investments in cloud and the innovations they have come up with, Amazon has to lift the veil a bit.
The reason is simple. The Amazon online retail business may be a $70 billion behemoth, but it does not throw off a lot of cash. Amazon founder and CEO Jeff Bezos is not interested in profits as much as he is about transforming the world around him, but the cloud computing business is one of the most capital intensive businesses there are in the world. Thanks to its near monopoly in online search, Google can spend tens of billions of dollars on datacenters and not bat an eyelash. Microsoft, thanks to its near monopoly on desktop software and its dominant position in datacenter software, also has very deep pockets and can spend as much.
No one questions the ability of Google or Microsoft to invest, even if we all do wonder how either could come up with a breadth of infrastructure and platform services that rivals Amazon. But people are beginning to question if Amazon can keep pace over the long haul with Google and Microsoft both gunning for it. (Andy Jassy, senior vice president in charge of the cloud unit at Amazon, faced such questions this week at the re:Invent conference.) And so, James Hamilton, vice president and distinguished engineer for AWS, has revealed the size and scope of the AWS cloud just to remind everyone that it has first mover advantage and that Amazon is absolutely committed to building out this business and the infrastructure that supports it.
Scale is perhaps the most important thing, and no one needs to teach an online retailer like Amazon anything about that. With Amazon, there is very little talk of public cloud, and that is because Amazon believes that, by its nature, cloud means it cannot be private. Over the long haul, Amazon believes the massive scale of the public cloud will mean that very few organizations will run their own datacenters.
Period. Full stop. Chew on that.

James Hamilton, AWS distinguished engineer
At the AWS re:Invent conference in Las Vegas this week, Jassy said this time and again, and it is a theme that he and Amazon CTO Werner Vogels have espoused since the cloud unit was created. (Even as they build a special version of the AWS cloud for the US Central Intelligence Agency under a ten-year, $660 million contract, but this is apparently an exception to the cloud means public rule.) The reason why Jassy and Vogels believe this is simple: those with the most cloud capacity in the most regions with the richest features will win the business, and with a few exceptions (such as financial services clouds or massive supercomputing centers with near 100 percent utilization and special needs hardware and software), the resources of the public cloud will not only be good enough, but will be better than what a lot of organizations could build and support themselves.
Amazon Web Services has abstracted the underlying compute, storage, and networking features of a cluster from programmers so they can just focus on creating applications, either on raw infrastructure or on platform services that have another layer of abstraction of top of them to further automate the deployment and management of middleware, databases, and other services that support applications. But that does not mean the underlying infrastructure is not important. In fact, Amazon has paid a fortune to design and build its own datacenters, optimizing everything from the memory chip out to the walls of the datacenter. The infrastructure definitely matters, it is absolutely a competitive advantage.
The Network Is A Bigger Pain Point Than Servers
Like many hyperscale datacenter operators, Amazon started out buying servers from the big tier one server makers, and eventually became the top buyer of machines from Rackable Systems (now part of SGI). But over time, like Google, Facebook, Baidu, and its peers, the company decided to engineer its own systems to tune them precisely for its own workloads and, importantly, to mesh hand-in-glove with its datacenters and their power and cooling systems. The datacenters have evolved over time, and the systems have along with them in lockstep.
In the past, Amazon has wanted to hint at the scale of its infrastructure without being terribly specific, and so they came up with this metric. Every day, AWS installs enough server infrastructure to host the entire Amazon e-tailing business from back in 2004, when Amazon the retailer was one-tenth its current size at $7 billion in annual revenue.
"What has changed in the last year," Hamilton asked rhetorically, and then quipped: "We have done it 365 more times."
That is another way of saying that in the past year AWS has added enough capacity to support a $2.55 trillion online retailing operation, should one ever be allowed to exist.
So how much capacity does AWS have? The answer is more than many have thought, and the architecture of the AWS cloud is something that Amazon perfected back in the late 1990s to give its own operations resiliency.
Here's the server math. Amazon has 11 regions around the globe where it has datacenter capacity. Each of those regions have at least two availability zones, with a total of 28 availability zones across all of the regions. (This includes the new region that was launched in Frankfurt, Germany two weeks ago.) These availability zones provide isolation and redundancy at a local level for workloads, like a kind of fault tolerant system akin to Tandem or Stratus only at a datacenter and services level than by literally lockstepping bits as they move through two systems. Each availability zone has at least one datacenter and some have as many as six datacenters. (In January 2013 at re:Invent, Hamilton said that the US East region had more than ten datacenters all by itself, but in his presentation at re:Invent 2014 he said that no zone had more than six datacenters.) The idea is that customers architect their applications to run across different availability zones for local data protection and then across multiple regions for an even higher level of availability. Amazon scales up the capacity in each availability zone by adding whole new datacenters.
Like enterprise customers add racks, basically. The datacenter is, in effect, the new rack for a company like AWS.
Anyway, here's the fun bit. Hamilton said each AWS region has at least two availability zones and at least one datacenter if not more, and then added that a typical datacenter has at least 50,000 servers and sometimes more than 80,000 servers. He added that the scale of economy for a datacenter ran out at about that upper level and that after a certain point, the incremental cost of that datacenter went up, not down, as more iron was added to it, and more importantly, at a certain number the "blast radius" of a datacenter failure was too great to allow that many workloads to be taken down by a catastrophic failure.
Let's do some math here. Assume that AWS had 28 availability zones with one datacenter each with only 50,000 servers each. That is the minimum capacity that the AWS infrastructure can have. That works out to 1.4 million servers worldwide. If you bracket that and say all of the zones have 80,000 machines (which we know is not true but just to put an error bar on it), that would be 2.24 million machines. To make a better guess at the scale of the AWS infrastructure, you need to reckon what the distribution of datacenter counts is within those availability zones. I happen to think there are a few with one datacenter, a whole bunch with two datacenters, and then it starts tapering off by datacenter count until you hit the maximum of six datacenters per availability zone. I played around with the numbers and came up with 87 datacenters across those 28 availability zones, which averages to just a little over three datacenters per zone. If you assume an average of somewhere around 65,000 servers per datacenter, then you get this immense number: 5.64 million servers. If the average is closer to 50,000 servers per datacenter, that drops to 4.2 million machines worldwide, and if you assume fewer datacenters per availability zone – say an average of two – then you are down to 2.8 million machines. So, the answer is that AWS probably has somewhere between 2.8 million and 5.6 million servers across its infrastructure. I realize those are some pretty big error bars, but this is the data we have to work with.
The point is that the scale is immense. But more than that, Amazon has done the hard work of creating custom networking gear and a private network on which to lash it all together into a humongous global cluster. That is what Hamilton was really excited to talk about anyway because the network is a huge bottleneck for computing.
"Networking is a red alert situation for us right now," explained Hamilton. "The cost of networking is escalating relative to the cost of all other equipment. It is Anti-Moore. All of our gear is going down in cost, and we are dropping prices, and networking is going the wrong way. That is a super-big problem, and I like to look out a few years, and I am seeing that the size of the networking problem is getting worse constantly. At the same time that networking is going Anti-Moore, the ratio of networking to compute is going up."
This, Hamilton said, is driven partly by the fact that there is more compute in every CPU from generation to generation, thanks to Moore's Law, and also that the cost per unit of compute is also falling. Because of this increased bang for the buck, more people are doing more analytics, and analytics workloads are very network intensive, and it pushes the network even harder. (This is because analytics workloads, like supercomputing workloads, have a lot of chatter across nodes, what is known as "east-west traffic" and distinct from the "north-south" traffic where a Web application needs a bit of data and grabs it off a server to display it over the Internet.)
So nearly five years ago, when this problem became apparent, AWS designed its own network routers and went to original design manufacturers to build the hardware, and put together a team to write the networking software stack on top of them. This is a course of action, Hamilton said laughing, where people "would get you a doctor and put you in a nice little room where you were safe and you can't hurt anyone."
The first thing that Amazon learned from its custom network gear is what it learned about servers and storage a long time ago: If you build it yourself with minimalist attitudes and only with the features you need, it is a lot cheaper. "Just the support contract for networking gear was running tens of millions of dollars."
But the surprising thing, even to Hamilton, was that network availability went up, not down. And that is because AWS switches and routers only had features that AWS needed in its network. Commercial network operating systems have to cover all of the possible usage scenarios and protocols with tens of millions of lines of code that is difficult to maintain. "The reason our gear is more reliable is that we didn't take on this harder problem. Any way that wins is a good way to win."
The other thing that Amazon in general and AWS in particular likes to do is test and gather lots of metrics about how something is – and is not – working. And so when it first tested out its homegrown networking, it did so on a 3 megawatt datacenter with 8,000 servers that cost something on the order of $40 million to build. This is not something even the largest network equipment providers can do, but AWS could, and did, literally rent the capacity from itself for a couple of hundred thousand dollars to test at this vast scale for a couple of months. (Yet another example of scale and how to leverage it.) Today all of the AWS network is using this custom network stack. Equally important to owning the stack and testing it thoroughly, Amazon continuously develops the code and puts it into production. "Even if it doesn't start out better, it keeps getting better."
That, in a nutshell, is what separates hyperscale from everyone else. It goes from hack to good enough to wildly better in a steady, evolutionary way with punctuated equilibrium every so often when a new idea is injected into the process.
AWS has eleven regions at the moment, up from nine two years ago, and it will be adding more to get closer to customers and to meet governmental jurisdiction requirements for doing business. (The German region was created precisely because German businesses and governments cannot store data in Ireland.) Here's is where they are located:

The regions are hooked together through private fiber links rather than on capacity bought from a third party, and the reasons for this are simple: This way, you can't get caught short on bandwidth as carriers are squabbling and you know exactly what performance to expect because you own the network. It is also cheaper, as you might expect, on a per-bit basis to own a network once you are at Amazon's scale, and as it turns out also faster because Amazon is not buffering its own traffic as carriers might when they get over-subscribed. "It is a more reliable link, it is a cheaper link, and it is a lower latency link," as Hamilton put it.
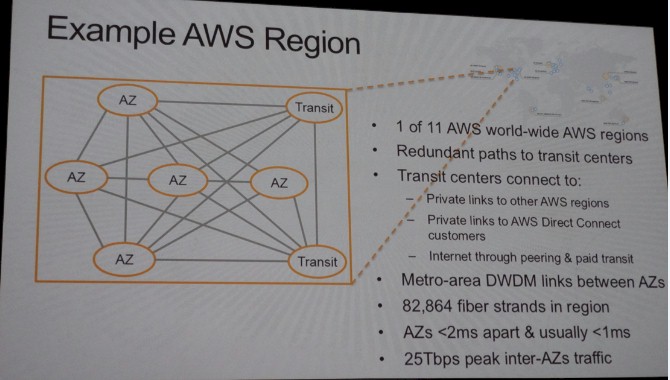
The above shows the US East region in Ashburn, Virginia. It has five availability zones, and these are protected areas that are isolated from each other by a couple of kilometers and linked by high-speed, low-latency networks where synchronous replication is possible but there is enough geographic isolation that the odds of two availability zones (housing multiple copies of your data and applications) are very small. The AZ units are connected by optical fibers that use dense wavelength division multiplexing (DWDM) to transport packets between the AZs in the region, and in the case of US East, there are 82,864 fiber strands. The AZs are usually under 1 millisecond apart in terms of latency and are always less than 2 milliseconds apart; this speed is what allows for synchronous data replication, since committing data to a solid state drive takes – wait for it – between 1 and 2 milliseconds.
If you did normal, geo-scale replication like an enterprise typically does for critical applications, with perhaps a worst-case scenario with a datacenter in New York and another in Los Angeles, the delay would be on the order of 74 milliseconds. You cannot do synchronous replication at that latency, and that means during a failure, you lose the data that was in flight before it could commit at the backup system and then you need to use journals to recover it, and this can take days.
This is why Amazon, the retailer, invented availability zones back in 2000. This approach is more expensive in some ways, but failover is faster – the AZs in the US East region had 25 Tb/sec of bandwidth between them – and easier, so it is worth it so long as you really need apps to be available. When you are an online retailer, you do. Imagine if you drove up to a Wal*Mart and the whole store just flickered out. (OK, that is a much cooler disaster.) If some stupid error happens, like a load balancer fails, one of the AZs just picks up the load and moves on, you re-synch later.
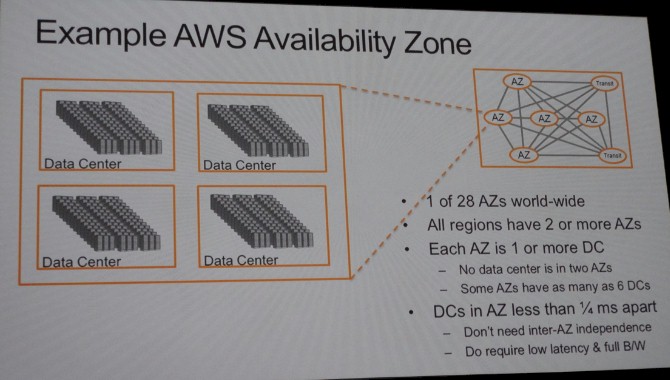
Now, drill down into one availability zone. The datacenters inside the availability zones in US East are about a quarter of a millisecond apart on the network, and no datacenter spans more than one zone. In fact, as noted above, an AZ can have multiple datacenters, and in fact, US East appears to have ten datacenters even though the chart above says some AZs have as many as six DCs. There are redundant transit centers into the availability zones. So Amazon can lose a transit center and multiple AZs and everything keeps working.

Drill down into an AZ and you have a datacenter, which as we already said above, has over 50,000 servers and sometimes over 80,000 machines. An AWS datacenter is rated at 25 megawatts to 30 megawatts, which means at the 87 datacenters I am projecting in total for AWS at the moment, that is somewhere between 2.17 gigawatts and 2.6 gigawatts of total electric capacity. Hamilton says that Amazon could do 60 megawatt datacenters, but the problem is, moving from 2,000 racks to 2,500 racks does not lower the incremental costs that much and at some point the failure zone, what he called the blast radius, was too large. "At some point, the value goes down and the costs go up, and in our view, this is around the right number," Hamilton says of the datacenter size AWS has chosen.
Write that down, competitors.
A single datacenter has up to 102 Tb/sec of bandwidth allocated to come into it – four times the aggregate inter-AZ bandwidth across the US East region, and Hamilton adds that the bandwidth inside the datacenter is "wildly higher" than this 102 Tb/sec.
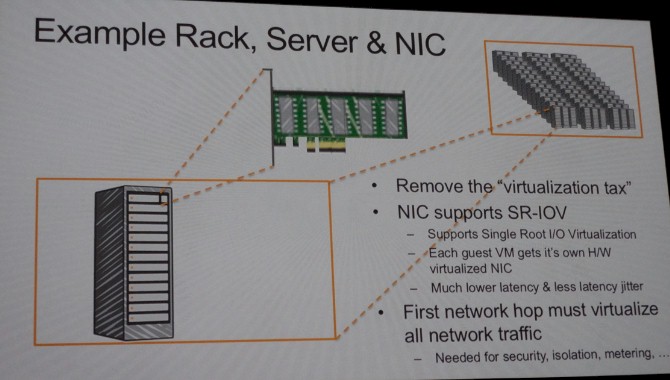
Now, let's dive into a rack and drill down into a server and its virtualized network interface card. The network interface cards support Single Root I/O Virtualization (SR-IOV), which is an extension to the PCI-Express protocol that allows the resources on a physical network device to be virtualized. SR-IOV gets around the normal software stack running in the operating system and its network drivers and the hypervisor layer that they sit on. It takes milliseconds to wade down through this software from the application to the network card. It only takes microseconds to get through the network card itself, and it takes nanoseconds to traverse the light pipes out to another network interface in another server. "This is another way of saying that the only thing that matters is the software latency at either end," explained Hamilton. SR-IOV is much lighter weight and gives each guest partition on a virtual machine its own virtual network interface card, which rides on the physical card.
So what took Amazon so long to get there? It is pretty hard to add security, isolation, metering, capping, and performance metrics to a network stack you have essentially removed, and it took a while to figure out how to do that. The newer instance types at AWS have this SR-IOV functionality, and it will eventually be available on all instance types.
Here is the upshot of the homegrown network that AWS has created:
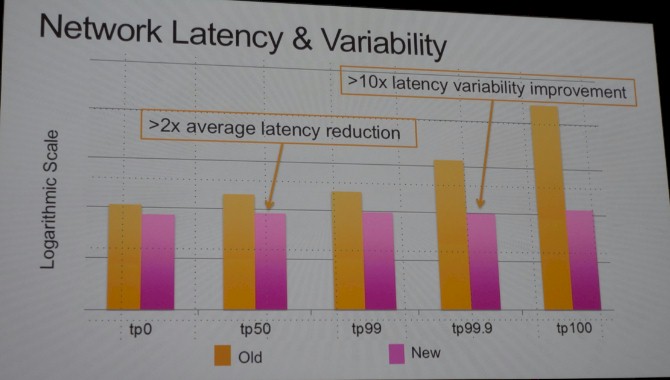
It is on a log scale, so remember that. The new network, after it was virtualized and pumped up, showed about a 2X drop in latency compared to the old network at the 50th percentile for latency on data transmissions, and at the 99.9th percentile the latency dropped by about a factor of 10X. For extreme outliers – and these transactions are the ones that can cause crazy things to happen in applications at the worst possible times – the latency was several orders of magnitude lower and therefore much, much less damaging to applications.
So if you are wondering why your network performance has improved recently on AWS, now you know.






