



Cray CS-Storm Packs A Serious GPU Punch

GPU accelerators for technical workloads are apparently like potato chips. You can’t have just one, or even two. That is why Cray has forged a new rack-based variant of its Cluster Solution line, called Storm, that can pack as many as eight Tesla coprocessors from Nvidia into a rack-based server node sporting Xeon E5 processors.
“There is a perfect storm of technologies and innovations that now allow for more applications to use this,” Barry Bolding, vice president of marketing and business development at Cray, tells EnterpriseTech. “We really do think there is a market for this. The Nvidia K40 is a very powerful compute device, and the business needs have also evolved. Not only are there now hundreds of accelerated applications, there are also many businesses that have accelerated their codes to run on one or two GPUs per server and they now are stepping up to want four or eight GPUs per server.”
The expanded use of GPU accelerators is happening in a number of commercial segments, says Bolding, including the energy industry with seismic analysis and reservoir modeling, in financial services with high frequency trading, and in machine learning, which is spanning industries and finding uses all through the software stack.
Nvidia’s partners have tweaked 272 applications to run in the CUDA environment so the Tesla cards can accelerate their workloads by crunching the heavy floating point computations that would otherwise be done on the CPUs in the system. But it is more than that. CUDA itself has matured, and there are a slew of acceleration libraries available to help those who write their own code boost their performance as well. OpenACC, a programing standard created by Nvidia, Cray, CAPS, and PGI (now part of Nvidia), is also coming along and makes C, C++, and Fortran applications more portable across various kinds of accelerators.
Cray has brought its engineering to bear with the CS-Storm chassis, and it is moving away from the Green Blade blade server design used in some of the existing CS-300 systems and with a rack-mounted chassis form factor. Bolding tells EnterpriseTech that in addition to cramming up to eight GPU coprocessors into a chassis alongside of a two-socket X86 node, the packaging and cooling are such that the Tesla coprocessors can run at their full rated 300 watts instead of being stepped down to 225 watts or 250 watts as happens in competitive systems that also put four or eight Teslas into a single node. Moreover, the enclosure can handle the top-bin “Ivy Bridge” Xeon E5-2600 v2 processors that run at 135 watts, so customers don’t have to sacrifice CPU performance, either.
“This is not your cheapest, generic motherboard with some GPUs slapped into it,” says Bolding. “There are a few other vendors trying to put four or eight GPUs into a system, and we think we have really brought it to its pinnacle.”

The server node used in the CS-Storm cluster also has sixteen DDR3 memory slots, which has twice the memory capacity of some of the dense CPU-GPU server nodes available on the market today. (Others have sixteen slots as well.) The memory can scale up to 1.87 GHz speeds and deliver 118 GB/sec of memory bandwidth for the Xeon compute part of the node. The 2U chassis has two banks of Tesla coprocessors, one on each side of the system, which each hold four Tesla K40 cards. Four cards are allocated to each socket. Tucked into the front of the system are six SATA disk drives for local storage on the node; Bolding says that flash storage is not particularly useful for the technical workloads that are running on CPU-GPU hybrids.
The way that the GPUs are linked to the CPUs is important, explains Bolding. Rather than try to put eight PCI-Express 3.0 slots onto the system board or a single big PCI-Express 3.0 switch to link all of the GPUs in the node to the two CPUs, Cray is actually putting four PCI-Express switches into the enclosure to hook the two kinds of compute resources to each other, in this manner:
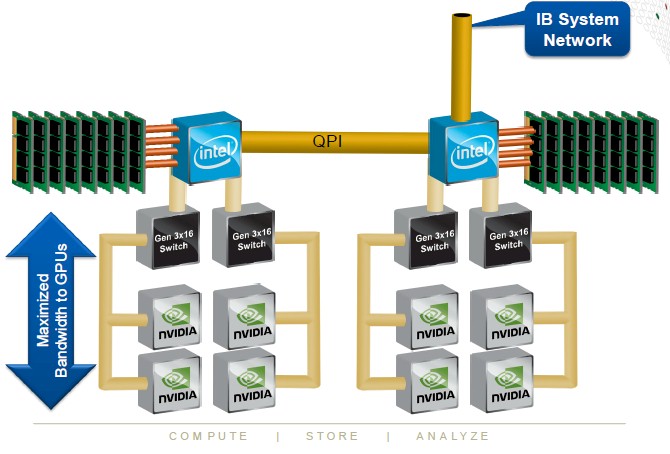
By having each pair of Tesla K40s feed into different ports on each Xeon E5 processor, Cray can make sure that it gets all of the bandwidth possible between the CPUs and the GPUs while still driving up the compute density. Cray is not naming who is supplying the PCI-Express switch chips used in the CS-Storm system, but an obvious guess is PLX Technology, which was just acquired by Avago Technologies two months ago.
The CS-Storm line does not make use of the “Aries” XC interconnect employed by the company’s XC30 high-end massively parallel supercomputers, but is rather using 56 Gb/sec adapters and switches from Mellanox Technologies to glue nodes together.
Using this PCI-Express setup, most of the applications that have been coded to offload work to Tesla GPUs are scaling up by a factor of 7.6 to 7.8 within a single node; how far the applications scale across nodes in a cluster depends in large part on how hard they hit that InfiniBand port on the node and the nature of the code.
The CS-Storm delivers about 11.4 teraflops in that 2U enclosure, and you can put up to 22 enclosures in a 48U rack for around 250 teraflops per rack. This CS-Storm rack is about 6U taller than a standard server rack and delivers about 4.7 times the performance per rack that you could get out of just using Xeon E5 processors alone in a standard rack. The CS-Storm is about 4.4 times more power efficient, too, by Cray’s calculations than a standard rack of X86 iron. If you do the math, the CS-Storm delivers about 4.1 teraflops per kilowatt and 24.7 teraflops per square foot.
The Cray software stack has also been ported to the CS-Storm line, including the Cray Advanced Cluster Engine, which includes server, cluster, network, and storage management as well as cluster partitioning, job scheduling, revision and rollback, and network and server auto-discovery and configuration. The Cray Compiling Environment, including the company’s C, C++, and Fortran compilers for its XC30 line of machines, have been ported to the CS-Storm clusters, and the major differences have to do with tweaking the Message Passing Interface (MPI) protocol to speak InfiniBand instead of Aries. Cray’s scientific and math libraries have also been ported over from the XC30, and so have its performance and analysis tools.
The CS-Storm is in limited availability now and will be generally available in the fourth quarter of this year. Cray says that a fully loaded rack will cost about $1 million.
The CS-Storm is not going to be limited to just the Tesla K40 coprocessors, and Bolding says that the design is “next-gen accelerator ready” without naming any names. But clearly the idea is to be able to snap in Nvidia’s “Maxwell” line of GPU coprocessors when they become available and quite possibly the “Knights Landing” Xeon Phi parallel X86 coprocessors when they come out next year, too. But the Knights Landing chips are also going to be available as true processors in their own sockets with their own on-chip interconnect etched onto the die, so Cray might instead offer a dense CS-Storm machine that just puts in all Xeon Phis. The point is, Cray is not telling yet but it has options and will do the thing that makes sense for customers and their workloads.






