



Inside Intel’s 610K Core EDA System
Intel is the world’s largest chip maker and is also the dominant supplier of processors for servers. So it might seem that Intel would have an unlimited supply of cheap processing capacity to design and make its Atom, Core, and Xeon chips. This is not so.
As it turns out, the managers who care and feed the gargantuan clusters that are used to run Intel’s mix of homegrown and third party electronic design automation (EDA) software – which currently have an aggregate of 610,000 Xeon cores – have exactly the same financial and technical constraints as other manufacturers. The same holds true for the systems that automate its chip fabrication, assembly, and test plants. And the systems that run Intel’s enterprise applications are treated no differently, either.
If anything, say executives at Intel, the bar is set higher for the company’s own IT infrastructure because Intel is supposed to set an example for others to follow.
To back up that claim, two key executives who run Intel’s IT operations sat down with EnterpriseTech and gave us a detailed, inside view of the systems that are used to design and manufacture the chips as well as the back office systems that run the company. The first was Shesha Krishnapura, who is senior principal engineer in Intel’s IT engineering group, and that means, among other things, that he runs the EDA systems and related factory automation systems. Krishnapura works closely with David Aires, general manager of Intel’s global IT operations and services, which is responsible for all of the IT systems at the chip giant. Intel is dead serious about setting a good example about how to run their clusters, and to prove it, Krishnapura and Aires brought plenty of data about the IT systems at Intel and how they have been improving over time, providing more capacity and running more efficiently as part of a multi-year datacenter consolidation effort.
This week, we will take a look at Intel’s EDA systems, which represent the bulk of the Intel server fleet, and next week we will give you some insight into what the company calls its Office/Enterprise/Services (OES) systems, which support its front office, back office, and services operations.
Before we dive into the EDA systems, let’s talk about a few things that are common across the Intel server fleet, which is close to 50,000 machines and shrinking as fast as Intel can manage it while radically increasing the compute that fleet delivers. Intel is also in the middle of a datacenter consolidation effort, reducing from 90 datacenters two years ago to 59 by the end of this year.
The first thing a lot of people assume is that Intel makes its own servers. It does not, and for sound economic reasons.
“We buy servers from the outside,” Krishnapura explains. “If we used internal servers, given that we have 59 datacenters, we would have to have worldwide distribution and support for those machines, plus a supply chain. It is much too cumbersome for us, since we would not be a big server vendor. It is not going to be very efficient. Also, if we built our own servers, from a CPU standpoint, we could get a much lower cost point. But if you buy from a server OEM, you are buying at the market price, the OEMs compete so you get a much better value, it helps Intel’s top line, and you get worldwide support.”
Intel has 39,000 servers supporting its EDA applications, plus another 4,500 supporting its manufacturing automation operations and another 4,500 supporting its OES operations. An additional 5,000 are doing infrastructure and data management to support the remaining 39,000 machines in the EDA side of the Intel house.
After doing the math year in and year out, Aires says that the optimum lifespan for a server is four years. “If you look at the purchase price, the warranty coverage, and the maintenance, this is where you get the lowest total cost of ownership,” he says. But that only takes into account the hardware costs. When you weave in the software costs, a case can be made to upgrade servers at a faster clip, depending on how the software is licensed. (More on that in a moment.)
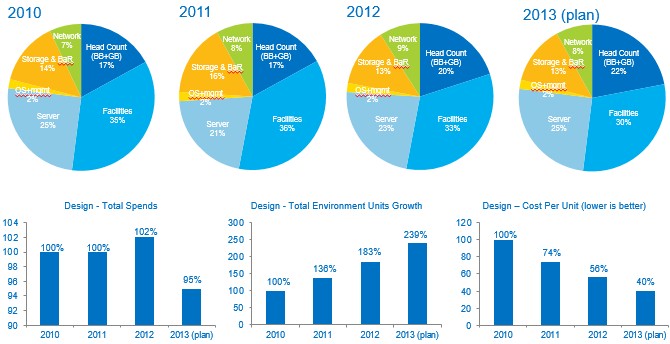
Intel shared the above spending trends with EnterpriseTech. The company is not going to be precise, but has a budget of several hundred millions of dollars per year for chip design and spends several tens of millions a year on servers. The BB+GB in the headcount figure refers to Blue Badge, or full-time, and Green Badge, or part-time, workers. About half of the facilities cost is due to depreciation of the datacenters. The unit of measure in the charts is EDA MIPS, which is a measure of relative performance on Intel’s own chip design software. The MIPS part, short for Meaningful Indicator of Performance per System and a play on the ancient term used to gauge relative performance on mainframes, is equal to the processing power of a “Nocona” Xeon server chip circa 2004. A “Sandy Bridge” Xeon E5 with eight cores running at 2.6 GHz is rated at 25 EDA MIPS. So basically, Intel has kept costs flat with a cut projected for this year while adding EDA processing capacity each year, thus reducing the cost of that unit of EDA processing capacity.
Using Moore’s Law to Drive Moore’s Law
Nobody knows Moore’s Law better than Intel, and if it could, it would upgrade its servers to the latest-greatest processors every time a new one came out so it could pack more punch into each server. But that is not practical. Given the four-year economic cycle – which is actually stretched in a lot of cases to give a nine-month overlap between an old and a new box – it can only upgrade a chunk of its fleet every year.
Right now, says Krishnapura, there is a mix of “Nehalem” Xeon 5500, “Westmere” Xeon 5600, and “Sandy Bridge” Xeon E5 servers supporting the EDA workloads. All but a handful of the machines are two-socket blade servers. (Intel is prohibited by its procurement agreements with the server makers to specifically name which ones, and similarly cannot name the Linux distributions it uses on these machines, either. But you know how to round up all the usual suspects.)
The core count grows pretty fast across the EDA systems. It needs to as the chips Intel is designing get more complex. They have more features as well as many existing ones that need to be tested to ensure backwards compatibility.
Last year, the 39,000 machines in the EDA clusters had 450,000 cores, and this year Intel will have 610,000 cores and that number is still growing in the wake of the launch of the “Ivy Bridge” Xeon E5 processors, which came out in September. Intel is still not sure how many servers it will have at the end of 2013. The reason is that Intel is going to move from two-socket to single-socket machines in this upgrade cycle, and the number of servers will become meaningless for the sake of comparison. The main EDA datacenters in Santa Clara, California, and Beaverton, Oregon, both have more than 10,000 servers each, and the smaller design centers have between 1,000 and 2,000 nodes each. In the United States, these smaller clusters are located in in Chandler, Arizona; Hudson, Massachusetts; and Folsom, California. Intel has several design centers in Israel and India as well, which also have their own clusters.
The machines are not virtualized, and they run a homegrown workload scheduling program called NetBatch that Krishnapura was hired by Intel to help develop back in 1991. NetBatch was originally written in C and has been ported to Java in recent years.
Here’s the neat bit about Intel’s EDA clusters: As the server nodes have decreased in number, the amount of processing capacity on the EDA workloads and cores has scaled at a slight exponential curve:
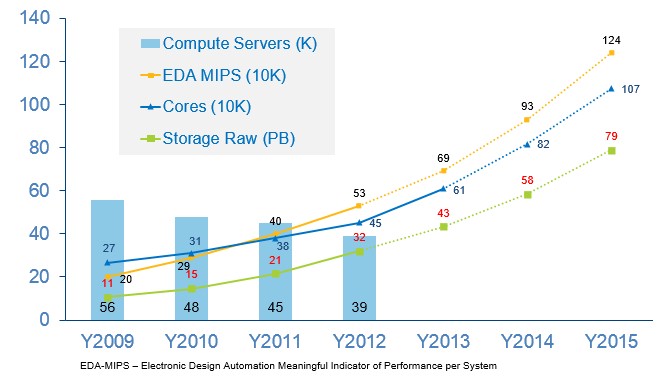
Intel uses Moore’s Law to its own advantage to push Moore’s Law in its chip designs, which in its Xeon server chips have moved from four cores with Nehalem, to six with Westmere, to eight with Sandy Bridge and now to ten and twelve with Ivy Bridge. The server footprint for the EDA systems is down from 56,000 in 2009 to 39,000 in 2012 and is at the moment holding there in 2013, but as you can see in the chart above, the core count has grown from 270,000 to 610,000 over the same term. In the chart, aggregate EDA MIPS was 200,000 in 2009 and is projected to be 690,000 in 2013. The EDA performance has grown faster than the core count as server node count has dropped.
Look at where Intel is going. Krishnapura thinks it will break through 1 million cores in its EDA clusters by 2015, delivering 1.24 million EDA MIPS in aggregate. Krishnapura is not projecting the number of servers this will take, but the trend is clearly down and will be driven by the ever-larger number of cores on the Xeon die. (If Krishnapura did put in the number of servers in these projections, we would be able to do the math and work out how many cores would be on a die in future Xeon chips, perhaps.)
The number will be down, and perhaps because Intel is thinking of accelerating the server replacement cycle for the EDA systems. Given how much it spends on EDA software, Krishnapura says that Intel is thinking that it can accelerate the upgrade cycle from four to three years, taking the money from EDA software license reductions, which are licensed based on server nodes, and pushing it into new blade servers with Ivy Bridge Xeons.
Intel used to make its own EDA software, but over the years it acquired a number of chip making operations and also started using third party software from Synopsys, Cadence Design Systems, and Mentor Graphics. Krishnapura says that roughly speaking, for every dollar Intel spends on servers in the EDA cluster each year, it spends roughly four dollars for software licenses and support in that same year. Software is therefore a big part of the IT budget for chip design.
The problem with the EDA software is that it is not particularly well threaded. Chip design has two aspects: logic design and physical design, and both have interactive and batch components. Logic design uses 70 percent of the total computing in a multi-year chip project, with the remaining 30 percent in the physical design, says Krishnapura.
“If you look at our EDA workloads, 90 percent of them are CPU bound,” says Krishnapura. “Moreover, only a handful of the EDA applications are threaded. Most of them are single-threaded applications. In the logic world, it has been extremely difficult for the big three vendors – Synopsys, Cadence, and Mentor Graphics – to thread their applications because of the way the logic simulation works. Even when they do thread it, at the eight-thread level, the best they are able to see is a 2.3X speedup. It doesn’t scale. It is better to focus on the single-threaded performance. Given that we do hundreds of thousands of logic simulations per day, this is a massive distributed computing job. As long as the CPU cores have enough memory, this is purely a CPU, clock, instruction, and cache play as opposed to a network play.”
Each rack in the EDA clusters that are distributed around the Intel design centers have had 10 Gb/sec Ethernet links running up to the core network, but the blade enclosures in the Nehalem and Westmere server nodes have only 1 Gb/sec Ethernet ports up to the top of rack. With the shift to Sandy Bridge chips in 2012, 10 Gb/sec ports were added to the server nodes, but Intel has not upgraded its top of rack switches to 40 Gb/sec yet because, as Krishnapura points out, the EDA jobs are not network sensitive. What matters is allowing chip designers to submit their logic designs for testing and running them against all of the test cases. In many cases, that means submitting the designs created on local clusters to the big clusters in Santa Clara and Beaverton overnight so they can see the failures when they come back to work in the morning.
What also matters for Intel is boosting the speed and effectiveness of the final and dramatic last step in chip design: tape out. When a design is done and has passed its tests, a giant wonking file that is more than 100 GB is created that describes to the chip plant how to make the masks that distort the 193 nanometer light that is used to etch chip features down as far as 22 nanometers. (Back in the day, this file was put on half inch tape and walked over to the fab – something that both Krishnapura and Aires did in their early days at Intel. The term tape out has stuck, even though there is no tape.)
To create the masks, you basically have to massively distort the image of each layer of the chip to make the light do unnaturally small features. This process is called resolution enhancement and optical proximity correction, and Krishnapura says that it involves running a massive series of fast Fourier transforms that run over the course of days to map out each of the layers in the chip. The Sandy Bridge design has 60 layers, for instance, and 20 of them are very complex and require up to 30,000 cores to do these fast Fourier transforms.
Here is how the tape out process has been improved as the EDA systems have been scaled up over the past several generations of chips:
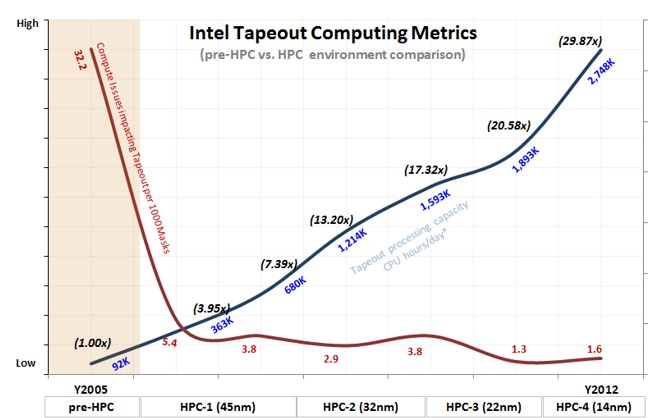
“A 30X performance improvement per day is extremely significant,” says Krishnapura. “And if you look at the reliability levels, they have also significantly improved. This is an HPC system that has been created in lockstep with our manufacturing processes to give us the tick-tock.”
That is a reference to the processor upgrade system that Intel came up with about a decade ago to compete better against AMD. With the tick-tock method, Intel creates a new design in an existing chip etching process and then tweaks that design for microarchitectural improvements as it moves to a new process. This minimizes risk and maximizes performance gains each generation.
The most impressive thing is that in recent years, this massive increase in compute in the EDA clusters has been accomplished while keeping the server budget flat and trying to push it down.






