



Hammerspace Unveils New Hyperscale NAS Architecture for Training Enterprise AI Models at Scale
SAN MATEO, Calif., Feb. 22, 2024 -- Hammerspace today unveiled the high-performance NAS architecture needed to address the requirements of broad-based enterprise AI, machine learning and deep learning (AI/ML/DL) initiatives and the widespread rise of GPU computing both on-premises and in the cloud.
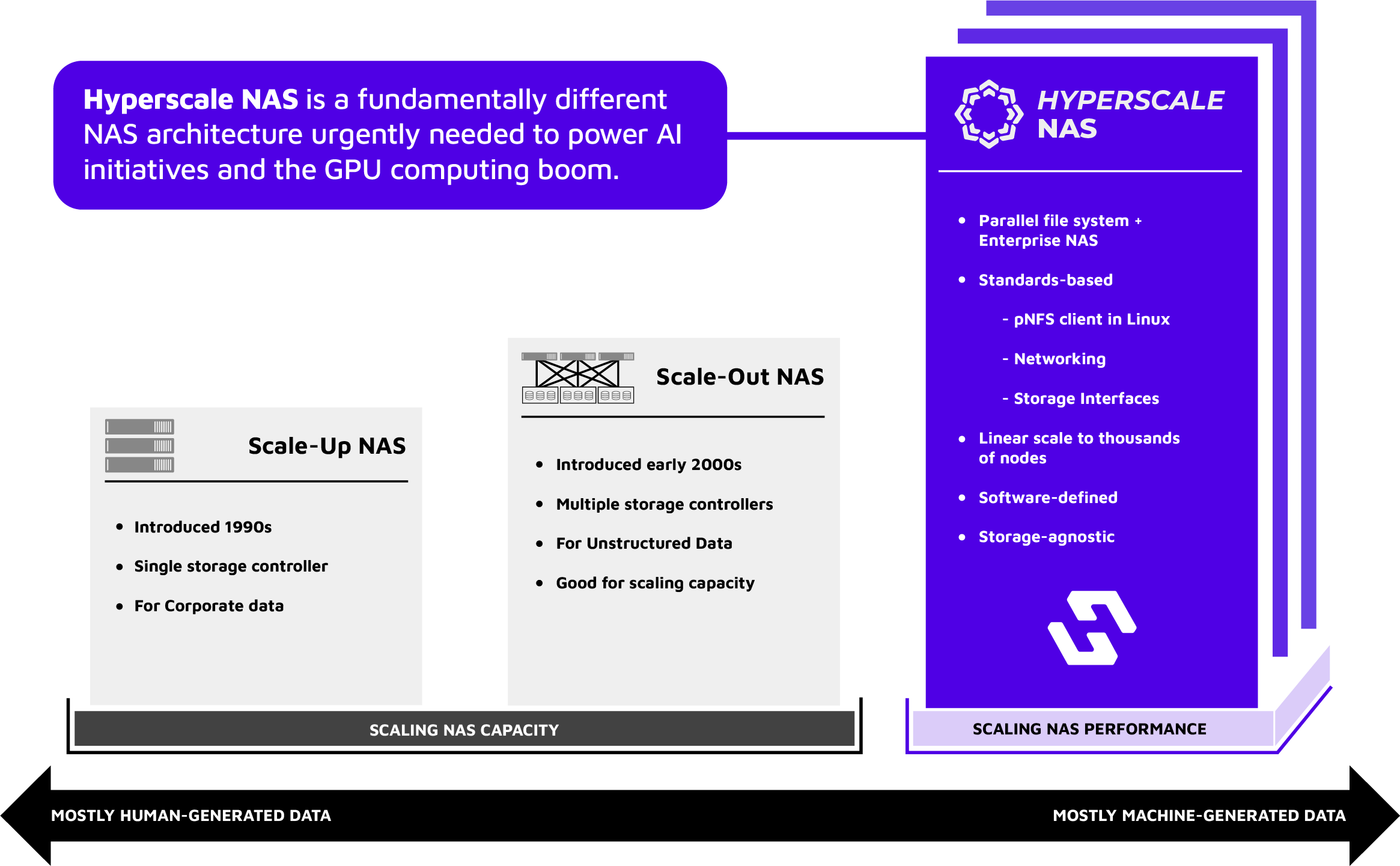
![]() This new category of storage architecture – Hyperscale NAS – is built on the tenants required for large language model (LLM) training and provides the speed to efficiently power GPU clusters of any size for GenAI, rendering and enterprise high-performance computing.
This new category of storage architecture – Hyperscale NAS – is built on the tenants required for large language model (LLM) training and provides the speed to efficiently power GPU clusters of any size for GenAI, rendering and enterprise high-performance computing.
“Most computing sites are faced with broad workload characteristics needing a storage solution with enterprise features, distance/edge, classical HPC, interactive, and AI/ML/data analytics capabilities all at large scale. There is a rapidly growing need for a distributed and parallel data storage architecture that covers this broad space so that sites don’t face the inefficiencies of supporting many different solutions,” said Gary Grider, High Performance Computing Division Leader at Los Alamos National Laboratory. “With the recent and near-future developments to the NFS standard, the open source implementation and acceptance into Linux, NFS has the features that enable a storage architecture to service this growing variety and scale of workloads well. We at LANL are pleased to see an industry partner contribute to Linux/Internet standards that address broad needs and scales.”
Legacy NAS Architectures Will Never Meet the Demands of AI Training at Scale
Building and training effective AI models require massive performance to feed the GPU clusters that process the data. The performance requirements are varied, requiring a mix of streaming large files, read-intensive applications and random read-write workloads for checkpointing and scratch space. Traditional scale-out NAS architectures – even all-flash systems – can’t meet these applications’ performance or scale requirements. Delivering consistent performance at this scale has previously only been possible with HPC parallel file systems, which are complex to deploy and manage and don’t meet enterprise requirements.
A Hyperscale NAS architecture provides the best architecture for training effective models, speeding time-to-market and time-to-insight, and ultimately deriving business value from data.
“Enterprises pursuing AI initiatives will encounter challenges with their existing IT infrastructure in terms of the tradeoffs between speed, scale, security and simplicity,” said David Flynn, Hammerspace Founder and CEO. “These organizations require the performance and cost-effective scale of HPC parallel file systems and must meet enterprise requirements for ease of use and data security. Hyperscale NAS is a fundamentally different NAS architecture that allows organizations to use the best of HPC technology without compromising enterprise standards.”
Hyperscale NAS is Proven as the Fastest File System for AI Model Training at Scale
The Hyperscale NAS architecture has now been proven to be the fastest file system in the world for enterprise and web-scale AI training. It is in production with systems built on approximately 1,000 storage nodes, feeding up to 30,000 GPUs at an aggregate performance of 80 Terabits/sec over standard ethernet and TCP/IP.
Hyperscale NAS is Needed for Enterprise GPU Computing at Any Scale
Hyperscale NAS is adapting big tech strategies for business use. Just like Amazon Web Services (AWS) developed S3 for large-scale, efficient storage, becoming a model for object storage in companies, Hyperscale NAS is doing the same. It's the system used for training large language models (LLMs) and is now being used in businesses for computing with GPUs and training generative AI models. This approach is spreading, bringing advanced tech company methods to companies of all sizes.
The Hammerspace Hyperscale NAS architecture is ideal for both hyperscalers and enterprises as it does not require proprietary client software, efficiently scales to meet the demands of any number of GPUs during training and inference, uses existing Ethernet or InfiniBand networks, existing commodity or third-party storage infrastructure, and has a complete set of data services to meet compliance, security and data governance requirements.
Hammerspace Hyperscale NAS is Certified as NVIDIA GPUDirect Storage
The Hammerspace Hyperscale NAS architecture has completed the GPUDirect Storage Support validation process from NVIDIA. This certification allows organizations to leverage Hammerspace software to unify unstructured data and accelerate data pipelines with NVIDIA’s GPUDirect family of technologies. By deploying Hammerspace in front of existing storage systems, any storage system can now be presented as GPUDirect Storage via Hammerspace to provide high throughput and low latency performance to keep NVIDIA GPUs fully utilized.
Hammerspace at NVIDIA GTC 2024
Hammerspace will participate in the NVIDIA GTC AI conference on March 18-21, 2024, in San Jose, California. We will be at stand 1718 and meetings can be booked with our executive team: Book a Meeting.
About Hammerspace
Hammerspace is the data orchestration system that unlocks innovation and opportunity within unstructured data. It orchestrates the data to build new products, uncover new insights, and accelerate time to revenue across industries like AI, scientific discovery, machine learning, extended reality, autonomy, corporate video and more. Hammerspace delivers the world’s first and only solution to connect global users with their data and applications on any vendor’s data center storage or public cloud services, including AWS, Google Cloud, Microsoft Azure and Seagate Lyve Cloud.
Source: Hammerspace






