



Groq Shows Promising Results in New LLM Benchmark, Surpassing Industry Averages
MOUNTAIN VIEW, Calif., Feb. 13, 2024 -- Groq, a generative AI solutions company, is the winner in the latest large language model (LLM) benchmark by ArtificialAnalysis.ai, besting eight top cloud providers in key performance indicators including Latency vs. Throughput, Throughput over Time, Total Response Time, and Throughput Variance.
![]() The Groq LPU Inference Engine performed so well with a leading open-source LLM from Meta AI, Llama 2 70b, that axes had to be extended to plot Groq on the Latency vs. Throughput chart. Groq participated in its first public LLM benchmark in January 2024 with competition-crushing results.
The Groq LPU Inference Engine performed so well with a leading open-source LLM from Meta AI, Llama 2 70b, that axes had to be extended to plot Groq on the Latency vs. Throughput chart. Groq participated in its first public LLM benchmark in January 2024 with competition-crushing results.
"ArtificialAnalysis.ai has independently benchmarked Groq and its Llama 2 Chat (70B) API as achieving throughput of 241 tokens per second, more than double the speed of other hosting providers," said ArtificialAnalysis.ai Co-creator Micah Hill-Smith. "Groq represents a step change in available speed, enabling new use cases for large language models."
Groq has run several internal benchmarks, reaching 300 tokens per second consistently, setting a new speed standard for AI solutions that has yet to be achieved by legacy solutions and incumbent providers. ArtificialAnalysis.ai benchmarks confirm Groq superiority over other providers, especially regarding throughput at 241 tokens per second and total time to receive 100 output tokens at 0.8 seconds according to the benchmark techniques of input prompt size and output prompt size. For more benchmark details please visit https://groq.link/aabenchmark.
"Groq exists to eliminate the 'haves and have-nots' and to help everyone in the AI community thrive," said Groq CEO and founder Jonathan Ross. "Inference is critical to achieving that goal because speed is what turns developers' ideas into business solutions and life-changing applications. It is incredibly rewarding to have a third party validate that the LPU Inference Engine is the fastest option for running Large Language Models and we are grateful to the folks at ArtificialAnalysis.ai for recognizing Groq as a real contender among AI accelerators."
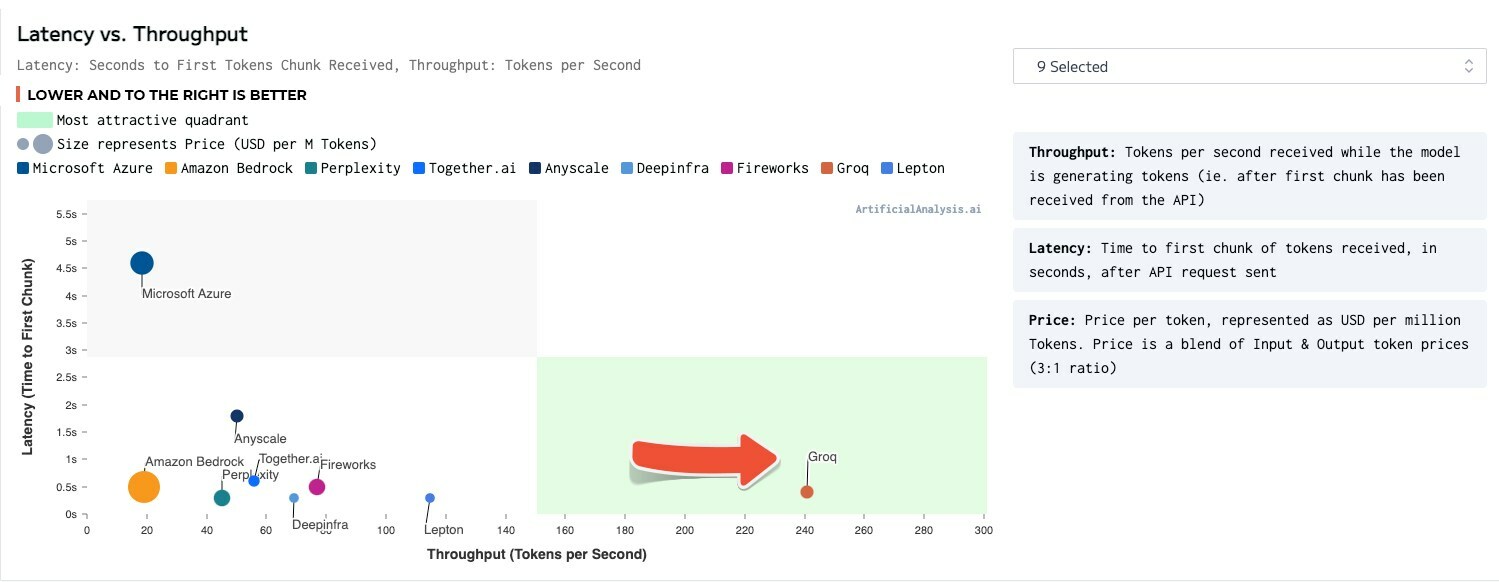
ArtificialAnalysis.ai has independently benchmarked Groq and its Llama 2 Chat (70B) API as achieving throughput of 241 tokens per second, more than double the speed of other hosting providers.
ArtificialAnalysis.ai benchmarks are conducted independently and are 'live' in that they are updated every three hours (eight times per day). Prompts are unique, around 100 tokens in length, and generate ~200 output tokens. This is designed to reflect real-world usage and measures changes to throughput (tokens per second) and latency (time to first token) over time. Benchmarks are also present on ArtificialAnalyis.ai with longer prompts to reflect retrieval augmented generation (RAG) use cases.
The LPU Inference Engine is available through the Groq API. For access, please complete the request form at https://groq.link/contact.
About Groq
Groq is a generative AI solutions company and the creator of the LPU Inference Engine, the fastest language processing accelerator on the market. It is architected from the ground up to achieve low latency, energy-efficient, and repeatable inference performance at scale. Customers rely on the LPU Inference Engine as an end-to-end solution for running Large Language Models (LLMs) and other generative AI applications at 10x the speed. The LPU Inference Engine is available via the GroqCloud, an API that enables customers to purchase Tokens-as-a-Service for experimentation and production-ready applications. Jonathan Ross, inventor of the Google Tensor Processing Unit (TPU), founded Groq to preserve human agency while building the AI economy. Experience Groq speed for yourself at https://groq.com.
Source: Groq






