



Is ChatGPT Getting Dumber?

The capability for machines to learn and get better over time is one of the big selling points for modern artificial intelligence. But new research released last week indicates that ChatGPT may in fact be getting worse at certain tasks as time goes on.
According to the first draft of a paper by Stanford University and UC Berkeley researchers, a considerable amount of drift was detected in the results of GPT-3.5 and GPT-4, the OpenAI large language models (LLMs) that back the popular ChatGPT interface.
The three researchers–which includes Matei Zaharia, who is an assistant professor at Stanford in addition to being a Databricks co-founder and the creator of Apache Spark, and UC Berkely’s Lingjiao Chen and James Zou–tested two different versions of the two LLMs, including GPT-3.5 and GPT-4 as they existed in March 2023 and June 2023.
The researchers ran the four models against a testbed of AI tasks, including math problems, answering sensitive/dangerous questions, answering opinion surveys, answering multi-hop knowledge-intensive questions, generating code, US Medical License exams, and visual reasoning.
The results show quite a bit of variability in the answers given by the LLMs. In particular, the performance of GPT-4 in answering math problems was worse in the June version than in the March version, the researchers found. The accuracy rate in correctly identifying prime numbers using chain-of-thought (COT) prompting showed GPT-4’s accuracy dropping from 84.0% in March to 51.1% in June. At the same time, GPT-3.5’s accuracy on the same test went from 49.6% in March to 76.2% in June.
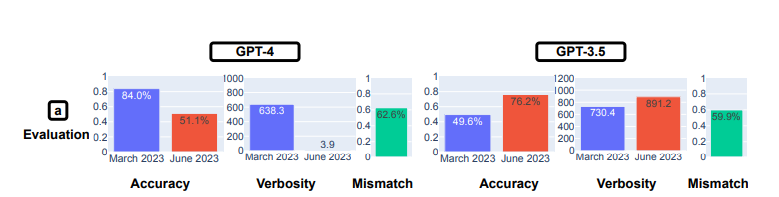
GPT-4’s math performance declined from March to June, while GPT-3.5’s went up, researchers from Stanford and UC Berkeley noted.
The authors pondered why GPT-4’s accuracy had dropped so much, observing that the COT behavior was different. The March version decomposed the task into steps, as the researchers requested with the COT prompt. However, the June version of GPT-4 didn’t give any intermediate steps or explanation, and simply generated the answer (incorrectly) as “No.” (Even if GPT-4 had given the correct answer, it didn’t show its work, and would therefore have gotten the question wrong, the researchers pointed out.)
A similar level of drift was spotted with a second math question: spotting “happy” numbers (“An integer is called happy if replacing it by the sum of the square of its digits repeatedly eventually produces 1, the researchers wrote). The researchers wrote that they “observed significant performance drifts on this task,” the GPT-4’s accuracy dropping from 83.6% in March to 35.2% in June. GPT-3.5’s accuracy went up, from 30.6% to 48.2%. Again, GPT-4 was observed to not be following the COT commands issued by the researchers.
Changes were also observed when researchers asked the LLMs sensitive or dangerous questions. GPT-4’s willingness to answer questions dropped over time, going from a 21.0% response rate in March to a 5.0% rate in June. GPT-3.5, conversely, got more chatty, going from 2.0% to 5.0%. The researchers concluded that “a stronger safety layer” was adopted by OpenAI in GPT-4, while GPT-3.5 grew “less conservative.”
 The opinion survey test revealed that GPT-4 grew significantly less likely to submit an opinion, dropping from a 97.6% response rate in March to a 22.1% response rate in March, while verbosity (or the number of words) increased by nearly 30 percentage points. GPT-3.5’s response rate and verbosity remained nearly unchanged.
The opinion survey test revealed that GPT-4 grew significantly less likely to submit an opinion, dropping from a 97.6% response rate in March to a 22.1% response rate in March, while verbosity (or the number of words) increased by nearly 30 percentage points. GPT-3.5’s response rate and verbosity remained nearly unchanged.
When it comes to answering complex questions that require “multi-hop reasoning,” significant differences in performance were uncovered. The researchers combined LangChain for its prompt engineering capability with the HotpotQA Agent (for answering multi-hop questions) and noted that GPT-4’s accuracy increased from 1.2% to 37.8% in terms of generating an answer that’s an exact match. GPT-3.5’s “exact-match” success rate declined from 22.8% to 14.0%, however.
On the code generation front, the researchers observed that the output from both LLMs decreased in terms of executability. More than 50% of GPT-4’s output was directly executable in March, while only 10% was in June, and GPT-3.5 had a similar decline. The researchers saw that GPT began adding non-code text, such as extra apostrophes, to the Python output. They theorized that the extra non-code text was designed to make the code more easy to render in a browser, but it made it non-executable.
A small decrease in performance was noted for GPT-4 on the US Medical License Exam, from 86.6% to 82.4%, while GPT-3.5 went down less than 1 percentage point, to 54.7%. However, the answers that GPT-4 got wrong changed over time, indicating that as some wrong answers from March were corrected, the LLM went from correct answers to wrong answers in June.
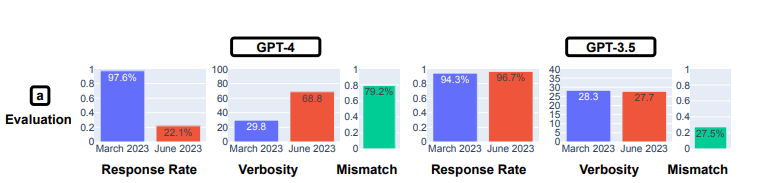
GPT-4’s willingness to engage in opinion surveys declined from March to June, Stanford and UC Berkeley researchers say.
The visual reasoning tests saw small improvements in both models. However, the overall rate of accuracy (27.4% for GPT-4 and 12.2% for GPT-3.5) isn’t great. And once again, the researchers observed the models generated wrong answers to questions that they had correctly answered previously.
The tests show that the performance and behavior of GPT-3.5 and GPT-4 have changed significantly over a short period of time, the researchers wrote.
“This highlights the need to continuously evaluate and assess the behavior of LLM drifts in applications, especially as it is not transparent how LLMs such as ChatGPT are updated over time,” they wrote. “Our study also underscores the challenge of uniformly improving LLMs’ multifaceted abilities. Improving the model’s performance on some tasks, for example with fine-tuning on additional data, can have unexpected side effects on its behavior in other tasks. Consistent with this, both GPT-3.5 and GPT-4 got worse on some tasks but saw improvements in other dimensions. Moreover, the trends for GPT-3.5 and GPT-4 are often divergent.”
You can download a draft of the research paper, titled “How Is ChatGPT’s Behavior Changing over Time?” at this link.
This article first appeared on sister site Datanami.






