



Nvidia Upgrades NeMo Megatron AI Toolkit

Part of Nvidia's AI platform, the NeMo framework helps users build and train GPU-accelerated deep learning models; NeMo Megatron, part of that framework, focuses on collecting data for and training large language models (LLMs), evaluating those models, and using the models for inference. Now, Nvidia has announced that, amid the ongoing surge in LLMs, it is upgrading NeMo Megatron to the tune of a 30 percent training speedup.
“LLM processing requires massive amounts of compute and memory. Previously, developers had to choose between two simplistic approaches: recompute all activations or save them in memory,” explained Ujval Kapasi, vice president of deep learning software for Nvidia, in an email to EnterpriseAI. “The former provided a lot of memory savings when needed, but at the expense of a lot of extra computations.” To that end, the announcement encompasses several big changes for NeMo Megatron.
First: sequence parallelism. Nvidia explained that some sections of the transformer blocks in LLMs were previously computed on all GPUs; the new release of NeMo Megatron distributes those shared blocks across many GPUs rather than duplicating them.
The second feature: selective activation recomputation, or SAR. SAR provides a somewhat analogous function to sequence parallelism, noticing where memory constraints force the recomputation of some — but not all — of the activations. In these cases, SAR intervenes, checkpointing and recomputing selective elements of each transformer layer to reduce memory impacts without substantial computational expenses. (The alternative: full recomputation.) “Selective activation recomputation is a pure software optimization and doesn't change the math used to train the LLM at all,” Kapasi wrote. “So it can be applied to any kind of learning scenario.”
Finally: a new hyperparameter tool. The tool, Nvidia says, identifies the optimal training and inference configurations using heuristics and empirical grid search across distinct parameters. It judges the potential configurations based on data parallelism, tensor parallelism, pipeline parallelism, sequence parallelism, micro batch size and number of activation checkpointing layers.
Nvidia reports that these tools have substantial individual and combination effects on the speed of NeMo Megatron. Sequence parallelism and SAR produced activation memory savings of around 5× and reduced recomputation overhead from 36 percent to 2 percent for the largest models.
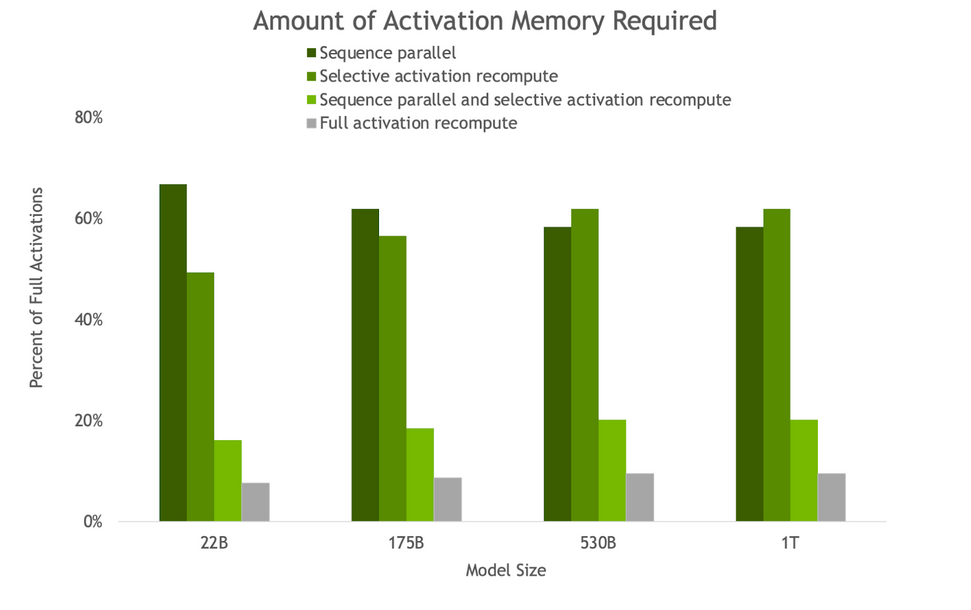
Image courtesy of Nvidia.
The new hyperparameter tool sped up training for a 175 billion-parameter GPT-3 model by 20 to 30 percent compared to a common configuration. Adding sequence parallelism and SAR to the new hyperparameter tool resulted in a further 10 to 20 percent throughput speedup (at least when applied to models in excess of 20 billion parameters).
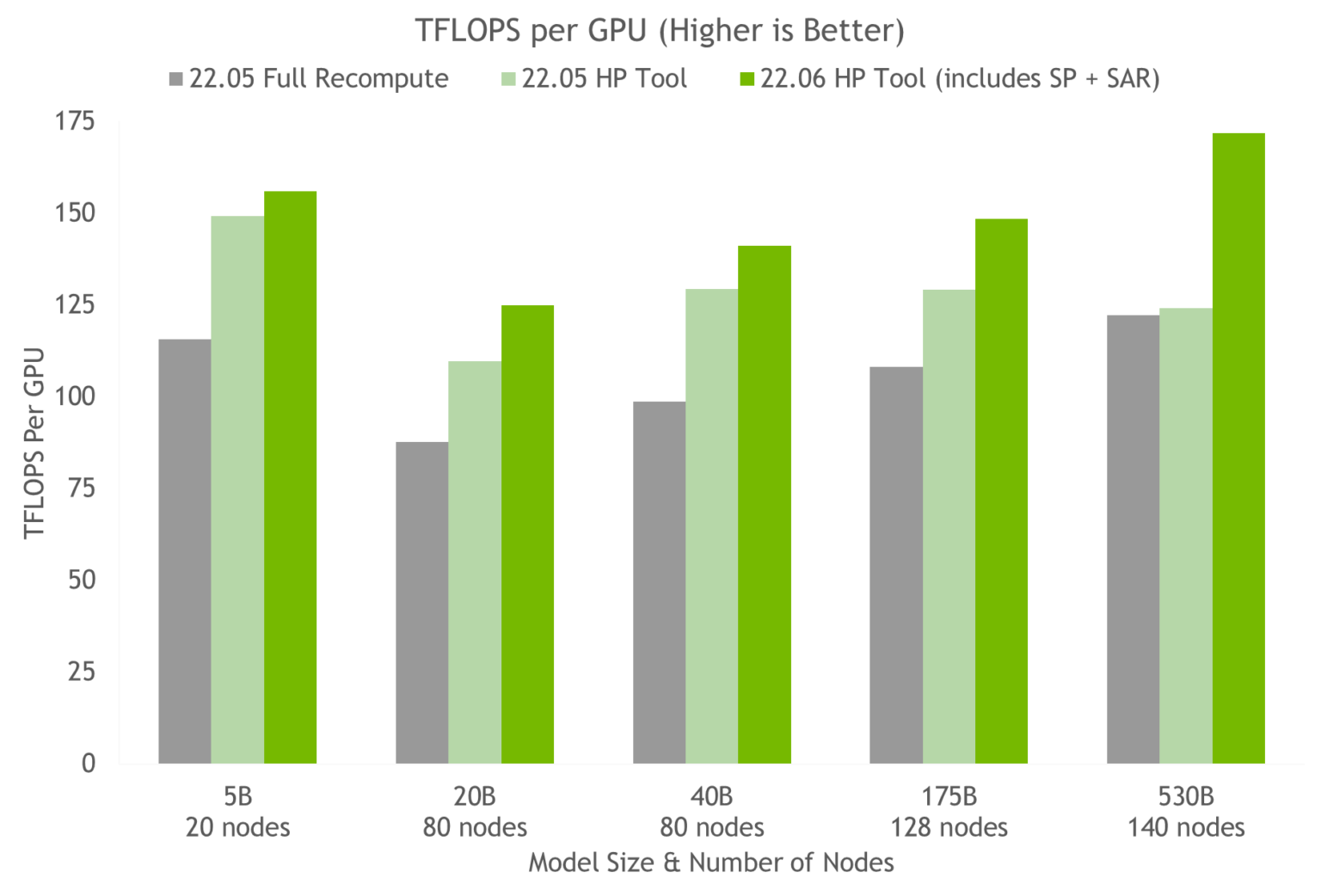
Image courtesy of Nvidia.
Zooming out, Nvidia says that the new version of NeMo Megatron is around 30 percent faster than its preceding version for those larger models, and that a 175 billion-parameter GPT-3 model can now be trained on 1,024 A100 GPUs in 24 days.
“The speedup arises from a combination of factors,” Kapasi underlined. “(a) the [hyperparameter] tool finds which combination of hyperparameters provide the best throughput for a given model size and given number of GPUs; (b) selective activation recomputation avoids recomputing all the activations within a transformer block; and (c) sequence parallelism avoids redundant computation of certain layers on every GPU.”
![]() Nvidia contextualized the NeMo Megatron news with one of the recent headliner LLMs: at 176 billion parameters, BLOOM just recently became the world’s largest open-access multilingual LLM — and it was trained using the Nvidia AI platform. Nvidia called LLMs like these “one of today’s most important advanced technologies” with an “expensive, time-consuming” development process. The AI community, the company said, continues to leverage Nvidia’s AI platform to advance LLMs and overcome these obstacles.
Nvidia contextualized the NeMo Megatron news with one of the recent headliner LLMs: at 176 billion parameters, BLOOM just recently became the world’s largest open-access multilingual LLM — and it was trained using the Nvidia AI platform. Nvidia called LLMs like these “one of today’s most important advanced technologies” with an “expensive, time-consuming” development process. The AI community, the company said, continues to leverage Nvidia’s AI platform to advance LLMs and overcome these obstacles.
LLMs, of course, have captured attention far beyond the AI community due to their often-uncanny ability to convincingly illustrate ideas, answer questions, mimic human writing and more. These capabilities have made them a frequent target of concern by AI researchers and the general public, with many proposing or implementing various frameworks for the ethical use of LLMs.
Agam Shah contributed to this reporting.






