



Nvidia Still Dominates Latest MLPerf Results, but Competitors Are Making Some Noise

MLCommons today released its fifth round of MLPerf training benchmark results and Nvidia GPUs again dominated the rankings, but competitors were not taking those results sitting down.
One of the other AI accelerator companies that participated, Graphcore, stood its ground by holding a separate media and analyst briefing to tout its own MLPerf performance, contending that its IPU-based systems were faster and offer a better bang-for-the-buck than similarly-sized Nvidia A100-based systems. Also, noteworthy, Microsoft Azure made its debut in the MLPerf training exercise with Nvidia-accelerated instances and impressive performances.
Making sense of the MLPerf results has never been easy because of the many varying system configurations of the submissions. Comparing the performance of an Azure deployment using up to 2,000 A100s to a Dell server running two CPUs and four GPUs, for example, isn’t especially informative by itself. Both setups may be excellent for the required tasks. The idea is to review specific results and configurations over the eight training workloads to find answers based on your needs. The time-to-train to a predetermined quality is one of the critical answers that the benchmarks can help provide.
The latest benchmark round received submissions from 14 organizations and released over 185 peer-reviewed results for machine learning systems spanning from edge devices to data center servers, according to MLCommons. That’s roughly unchanged from the 13 organizations that participated in June (training v1.0) and a considerable drop from the 650 results submitted at that time. Submitters for this round included: Azure, Baidu, Dell, Fujitsu, GIGABYTE, Google, Graphcore, Habana Labs, HPE, Inspur, Lenovo, Nvidia, Samsung and Supermicro.

Broadly, MLPerf seems to be steadying its position as a looked-for benchmark for machine learning (training, inferencing, and HPC workloads). Consider this statement of support from Habana Labs (owned by Intel) in today’s blog:
“The MLPerf community aims to design fair and useful benchmarks that provide “consistent measurements of accuracy, speed, and efficiency” for machine learning solutions. To that end AI leaders from academia, research labs, and industry decided on a set of benchmarks and a defined set of strict rules that ensure fair comparisons among all vendors. As machine learning evolves, MLPerf evolves and thus continually expands and updates its benchmark scope, as well as sharpens submission rules. At Habana we find that MLPerf benchmark is the only reliable benchmark for the AI industry due to its explicit set of rules, which enables fair comparison on end-to-end tasks. Additionally, MLPerf submissions go through a month-long peer review process, which further validates the reported results.”
Also important is MLPerf’s slow expansion beyond being been mostly a showcase for Nvidia accelerators – the jousting between Nvidia and Graphcore is a case in point. For the moment, and depending how one slices the numbers, Nvidia remains king.
Relying mostly on large systems – Nvidia supercomputer Selene, sixth on the Top500, and large deployments of Microsoft Azure ND A100 v4 series instances – Nvidia took top honors. Nvidia GPU performance has been unarguably impressive in all of the MLPerf exercises (click on charts shown below to enlarge them). Also, as pointed out by Nvidia’s Paresh Kharya, senior director of product management, datacenter computing, Nvidia was again the only submitter to run all eight workloads in the closed – apples to- apples – division. He pointedly noted Google (TPU) did not submit in the closed division and that Habana (Intel) only submitted on two workloads (BERT and ResNet 50).
MLPerf has two divisions: “The Closed division is intended to compare hardware platforms or software frameworks ‘apples-to-apples’ and requires using the same model and optimizer as the reference implementation. The Open division is intended to foster faster models and optimizers and allows any ML approach that can reach the target quality.” – MLCommons.
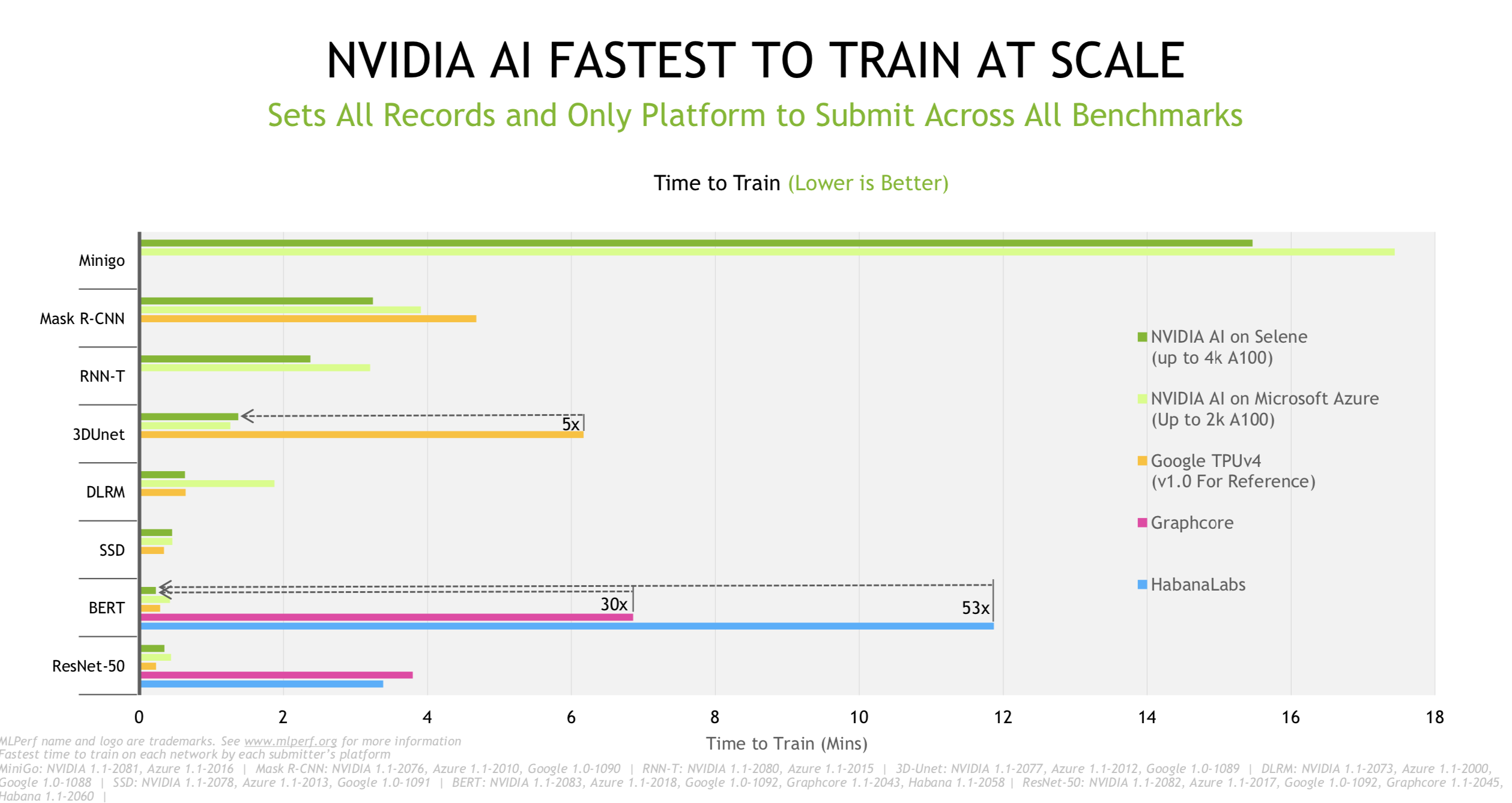
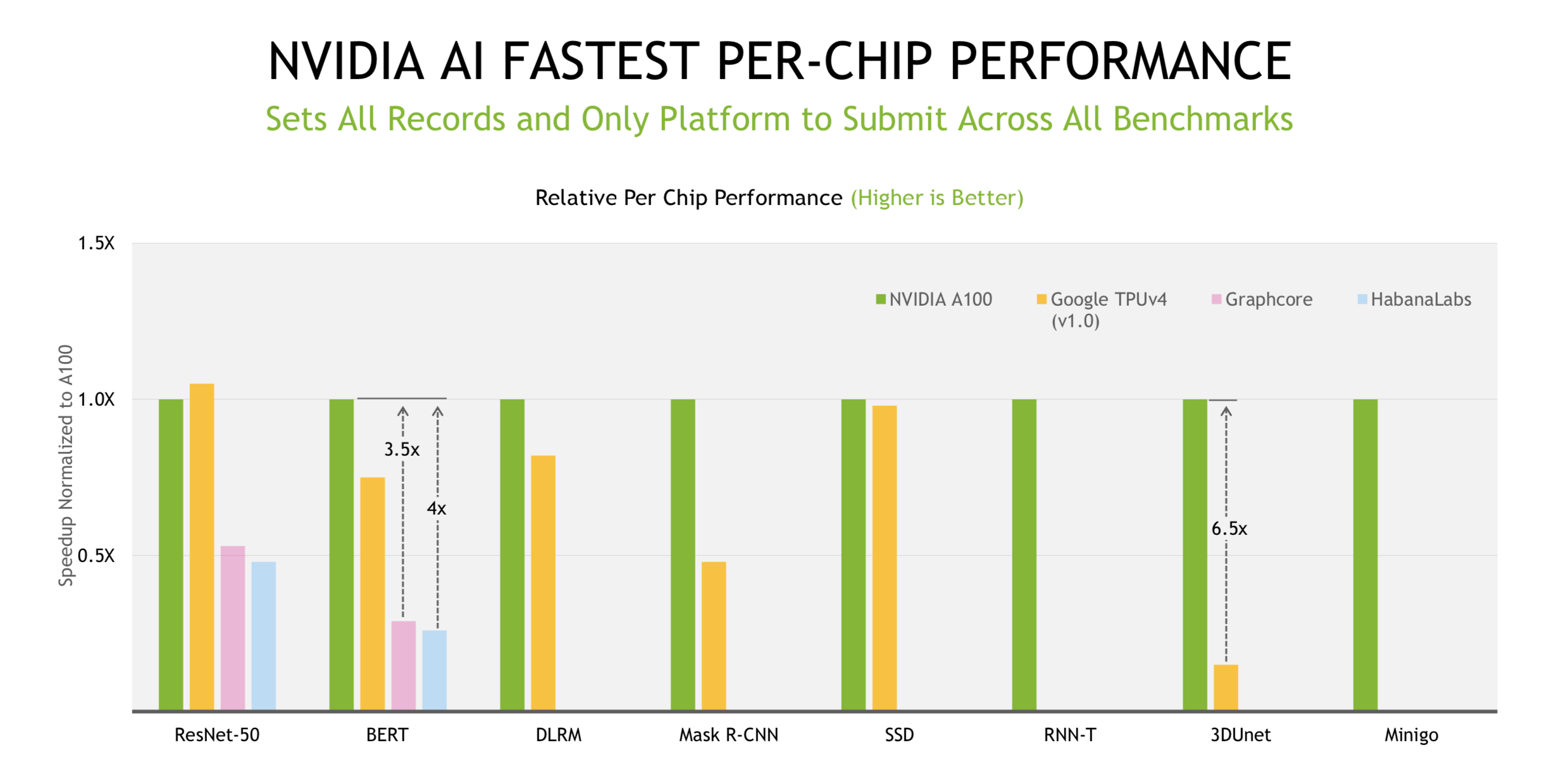
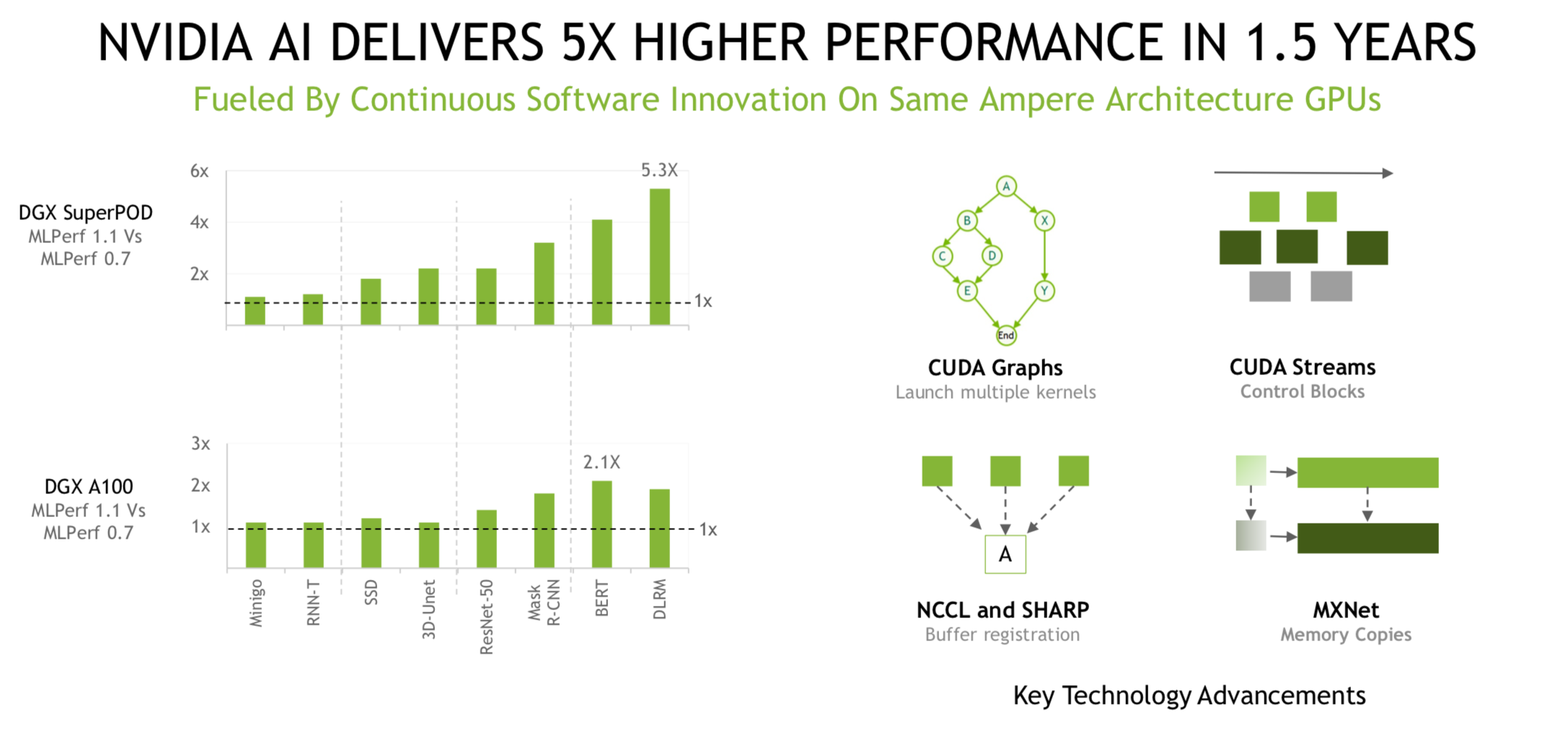
An interesting pattern has emerged in releasing MLPerf results – at least for training and inferencing. MLCommons conducts a general briefing with representatives of most of the participants present. It’s a friendly affair with polite comment. Individual submitters may then – in this case Nvidia and Graphcore – hold more a directly competitive briefing, touting their wares relative to competitors.
The competitive juices were flowing in Nvidia’s briefing as Kharya declared “Nvidia AI (broadly) is five times faster than [Google’s] TPU (from the earlier v1.0 run), 30x faster than Graphcore, and 50x faster than Habana.”
Graphcore, no surprise, has a different view. In the latest round, Graphcore submitted results from four systems, all leveraging its IPU (intelligence processing unit) which the company touts as the ‘most complex processor’ ever made (59.4 billion transistors and 900MB of high-speed SRAM).

During its separate pre-briefing, Graphcore sought to highlight its MLPerf performance and also broadly present Graphcore’s progress. David Lacey, chief software architect, cited software advances as the most significant driver of Graphcore’s improving performance.
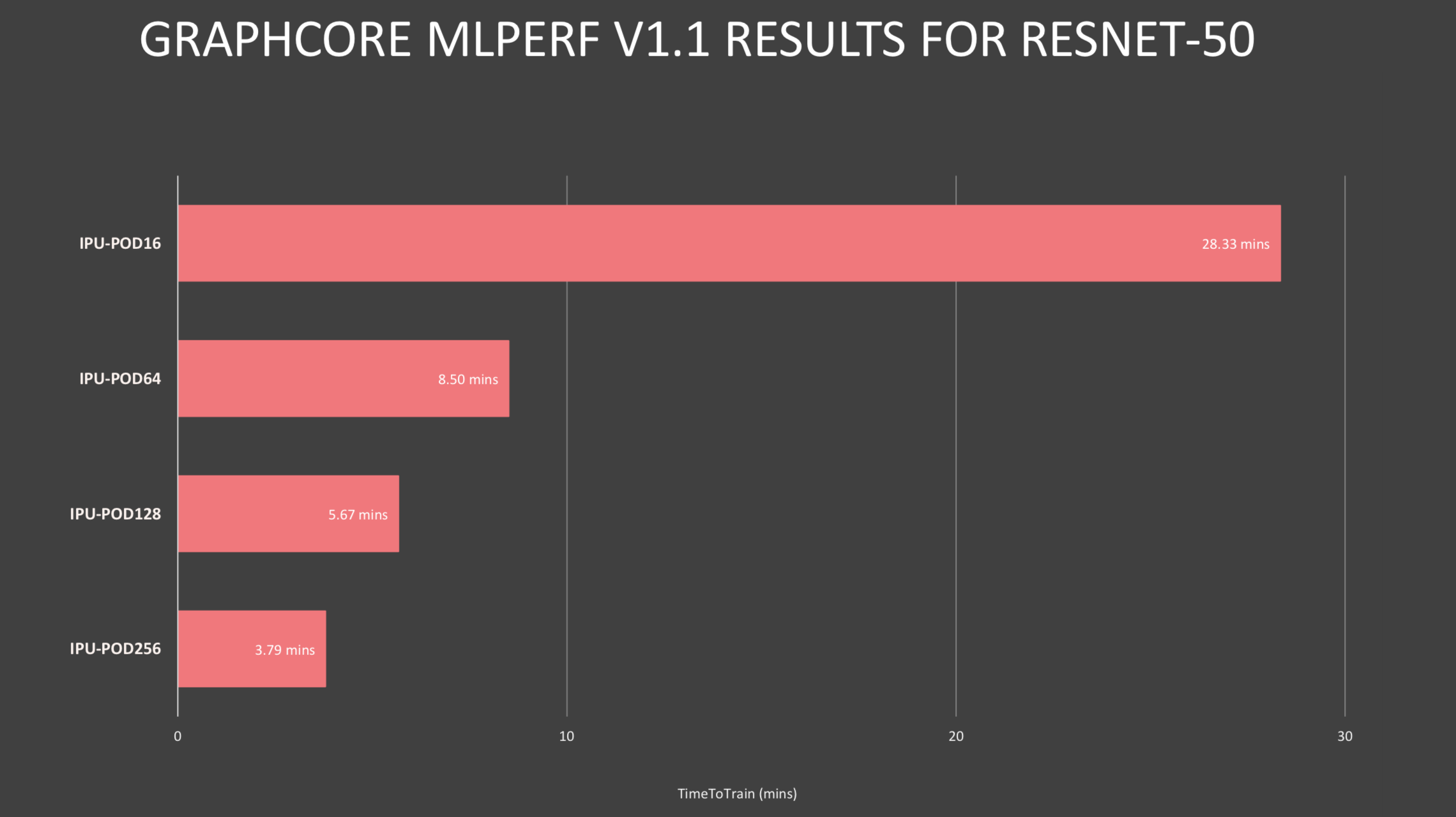
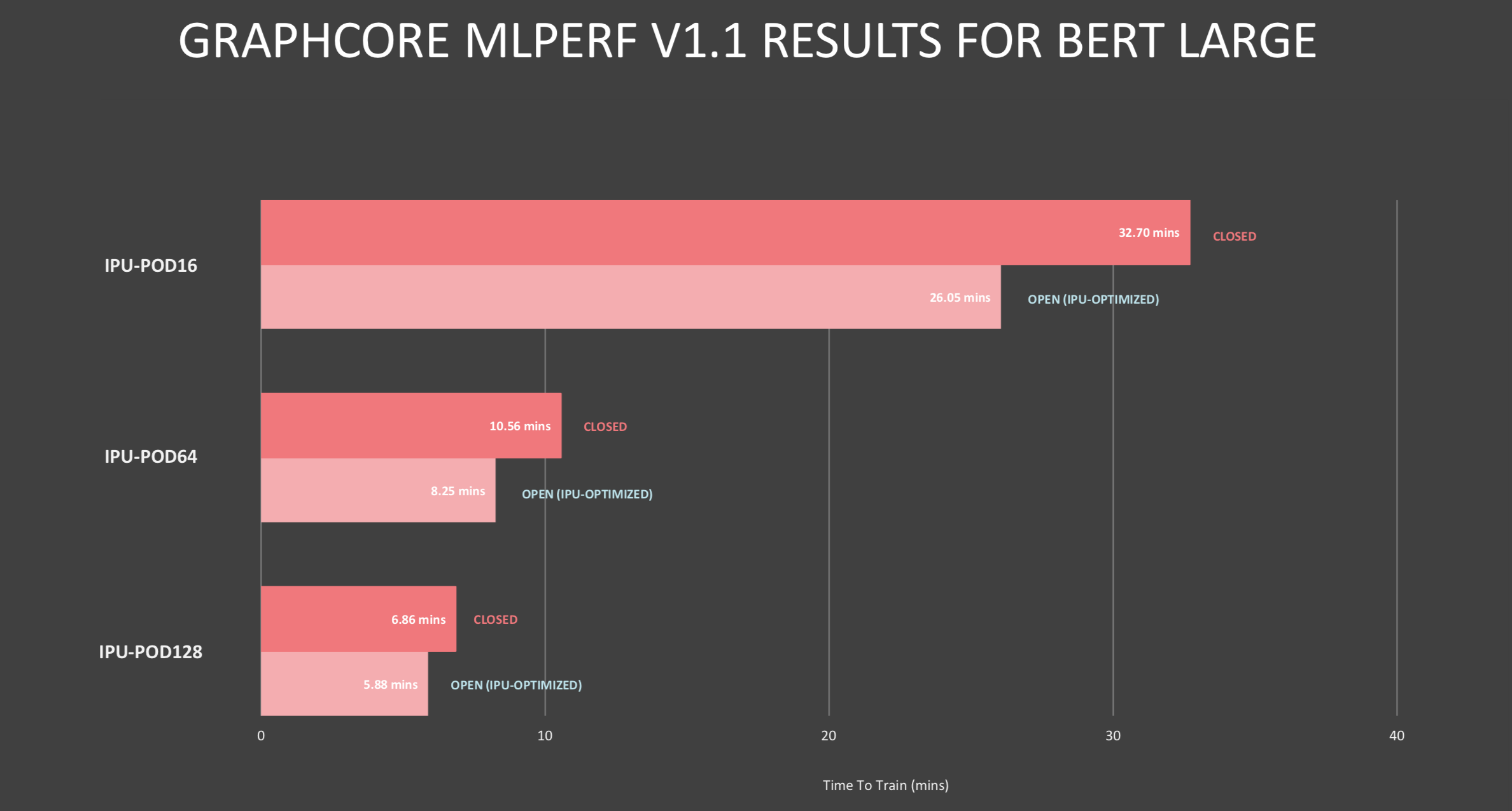
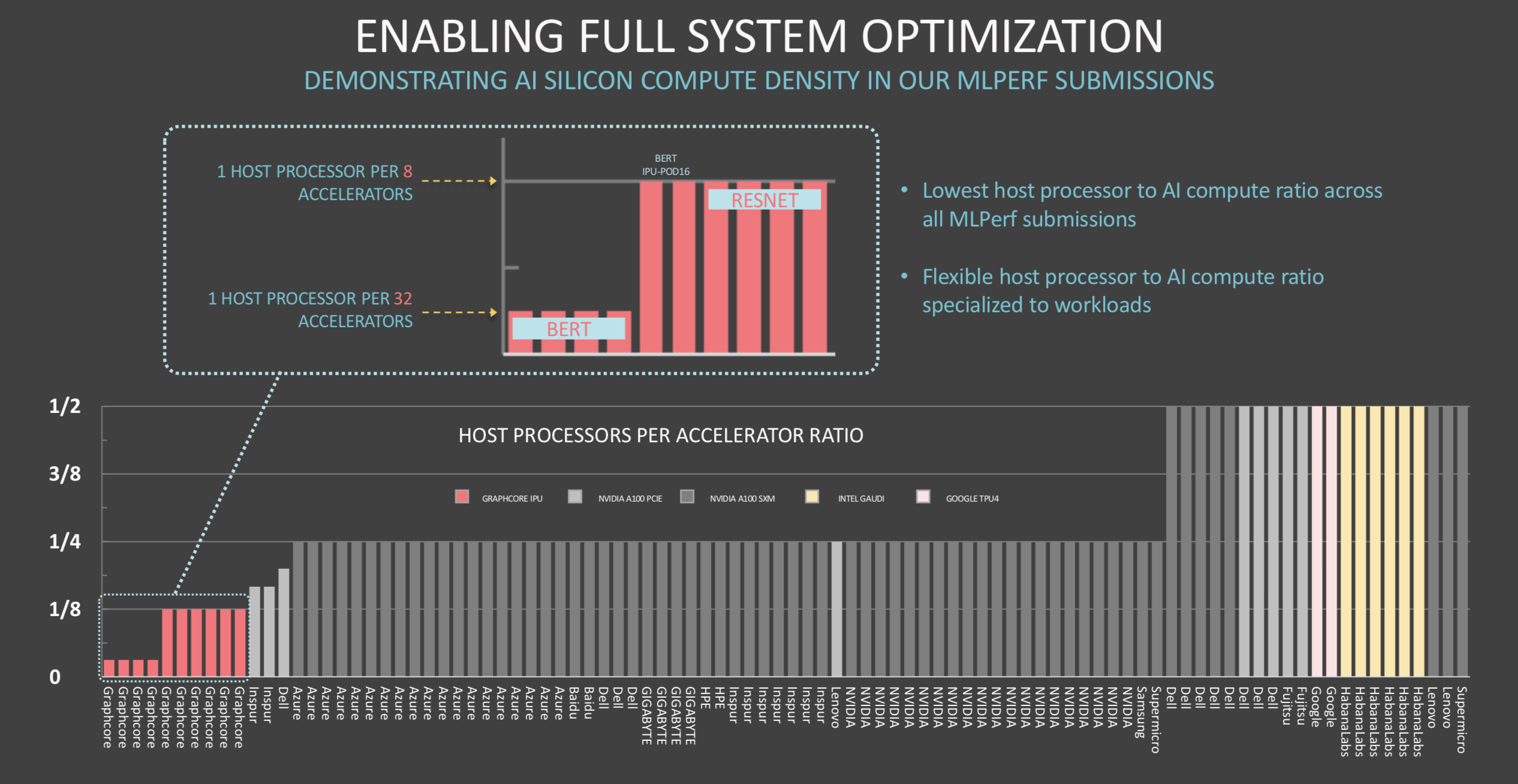
Lacey took aim at Nvidia, arguing that Graphcore outperformed similarly-sized A100-based systems, offering a superior CPU-to-accelerator ratio in its system that not only improved scalability but also cut system costs. The architecture, he said, is also flexible, allowing the user to choose appropriate CPU-accelerator ratios.
“You can see in BERT, we have one host processor for 32 accelerators, and on ResNet we have one [CPU] for eight accelerators. The reason you need more host CPUs in ResNet than BERT is because ResNet is dealing with images and the CPU does some of the image decompression. Either way, the ratios are smaller. I think even more importantly, there’s an efficiency there and we have a disaggregated system where we have flexibility to change that ratio,” said Lacey.
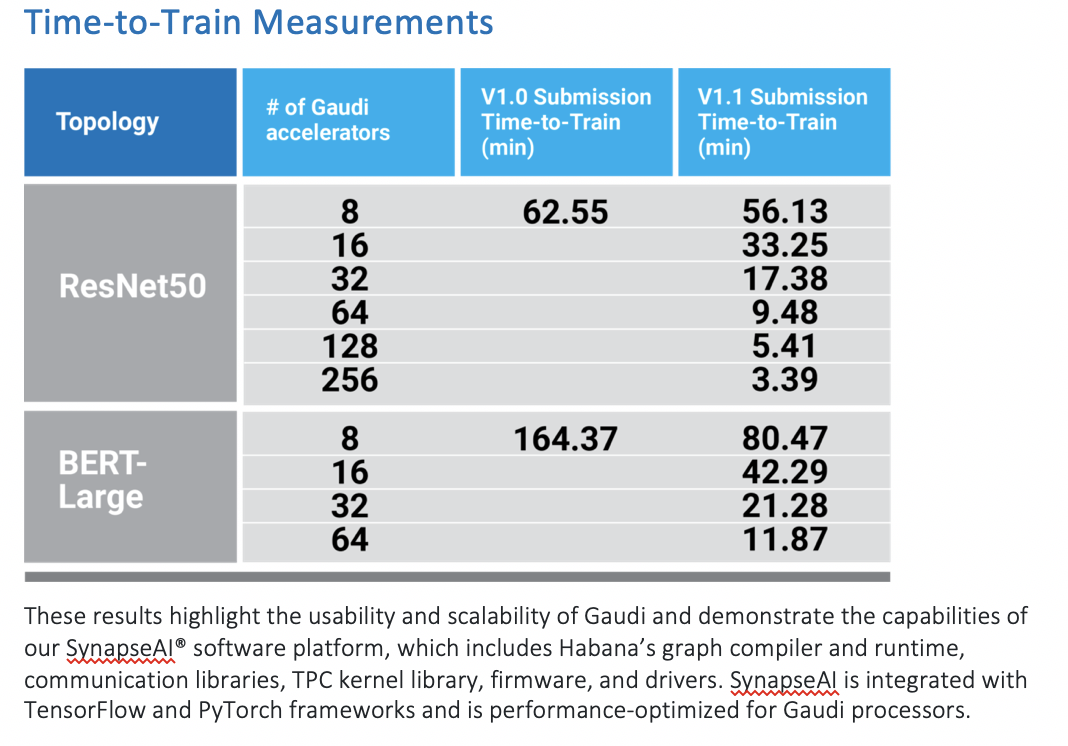
Habana also touted its performance in a press release and was offering private briefings. “Habana submitted results for language (BERT) and vision (ResNet-50) benchmarks on Gaudi-based clusters and demonstrated near-linear scalability of the Gaudi processors resulting in more than a 2x improvement in BERT time-to-train using the same Gaudi processors compared to our last round results. In addition, Gaudi time-to-train on ResNet-50 improved by 10 percent,” reported Habana.
 Putting aside the technical merits of the arguments, the fact that different AI chip and systems makers are using MLPerf exercises to showcase their wares and take on Nvidia is probably a good sign for MLPerf generally, suggesting it is evolving towards a truer multi-AI technology showcase for comparing performance.
Putting aside the technical merits of the arguments, the fact that different AI chip and systems makers are using MLPerf exercises to showcase their wares and take on Nvidia is probably a good sign for MLPerf generally, suggesting it is evolving towards a truer multi-AI technology showcase for comparing performance.
Analyst Steve Conway, Hyperion Research, noted, “MLPerf is one of the few benchmarks available in the early AI era and is popular, although new adoption has leveled off after a strong initial surge. Nvidia rules the roost today for AI acceleration but it’s no surprise that this high-growth market has now attracted formidable competitors in AMD and Intel, along with innovative emerging firms such as Graphcore, Cerebras and others. Users wanting to bypass hyperbolic claims and untrustworthy comparisons would be well advised to supplement standard benchmark results by directly asking other users about their experiences.”
The MLPerf results are best explored directly keeping in mind your particular requirements.
This article first appeared on sister website HPCwire.






