



Cerebras Touts Linear Scaling up to 192 CS-2 Systems with Wafer Scale to ‘Brain-Scale’ Approach

Wafer-scale computing company Cerebras Systems has unveiled more details about its “brain-scale” approach for running the largest models in the world across up to 192 CS-2 systems. To enable this technology, Cerebras has introduced its weight streaming technology, which flips the way that models are usually run, at the Hot Chips conference on August 24 (Tuesday). Cerebras also launched two other new products -- MemoryX and SwarmX -- at the conference, which is being held as a virtual event due to the continuing COVID-19 pandemic.
Cerebras introduced the CS-2 system earlier this year, doubling the performance of the original CS-1, which debuted at SC19. The CS-2 system, now shipping, houses the second-generation Cerebras Wafer Scale Engine (WSE-2), which contains 850,000 cores and 40 GB of memory.

Inspired by the human brain’s harnessing of 100 trillion synapses, the brain-scale approach is Cerebras’ answer to running the very largest AI models, which are seeing exponential hikes in the number of parameters. In 2018, Google’s BERT debuted with 340 million parameters, taking about nine petaflops days to train. In 2019, T5 upped the scale to 11 billion parameters and took 900 petaflops days to train. In 2020, Microsoft announced MSFT-1T – a one trillion parameter model – that took about 25-30,000 petaflops days to train, according to Cerebras Founder and CEO Andrew Feldman.

Exponential growth of neural networks (source: Cerebras)
Referencing the chart (above), Feldman told HPCwire, “It is rare you have an exponential log graph on both the x and y axis and you can see it increasing an extraordinary amount on both. Over a two-and-a-half year period, model sizes grew 1,000 times and the amount of compute necessary to work on them increased by over 1,000X as well.”
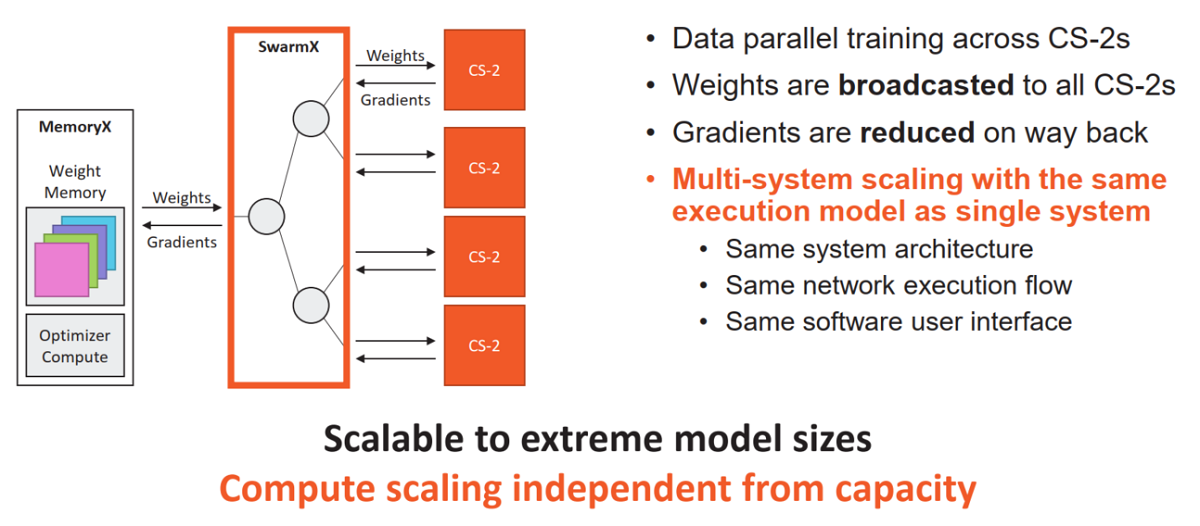
Cerebras is announcing that it can now support 120 trillion parameter models on a single CS-2, using a new custom memory extension technology called Cerebras MemoryX, which provides the second-generation WSE-2 with up to 2.4 petabytes of memory, allowing parameters to be stored off-system. And further, with the integration of new interconnect technology Cerebras SwarmX, the company can build clusters with up to 192 CS-2 systems, comprising an aggregate 163 million cores.
It is possible to configure these clusters with “a push of a button,” said Feldman, due to all the systems (nodes) using an identical initial configuration. The company has also implemented algorithmic techniques said to further increase the capabilities of the system to use less flops and power.
The technologies being introduced today enable the separation of model memory, compute and training data, such that each dimension can scale independently. “So the user can right-size the solution to their problem,” said Sean Lie, chief architect and co-founder, in his Hot Chips talk.
The heart of the innovation is a new execution mode called weight streaming. In the traditional execution mode, weights are held on the wafer and activations are streamed in. For models of extraordinary size, Cerebras reversed this, such that the weights are streamed in and the activations are held on chip. Cerebras’ MemoryX appliance uses a mix of DRAM and flash storage and scales from four terabytes to 2.4 petabytes in capacity, equivalent to between 200 billion and 120 trillion weights. Associated internal compute handles weight updates and provides other optimizer functionality.
The weight streaming approach only makes sense if you have a model big enough to fill up an entire wafer-scale chip (and beyond) and that era has definitely arrived, said Feldman.
The largest layers of the largest models fit comfortably within a single CS-2, according to Cerebras’ benchmarking. This is the reverse approach of the GPU which breaks up elements into pieces and distributes them across many compute units.

For training models across a cluster of CS-2s, each CS-2 starts with an identical configuration, and holds identical information. They differ only by the data coming in, which modifies the gradients, which are then broadcast across the SwarmX fabric. The data are reduced on the way out and enter the MemoryX technology. The process repeats until the all the layers are updated and the model is trained.
Because the systems are all identical, they can be configured in a single keystroke, Feldman emphasized.

Cerebras CS-2 machine
Linking units together is what supercomputing expertise is based on, he continued. “Our strategy at Cerebras was first: take as many of those little nodes as we can and put them on one wafer, and that’s our CS-2. Our new weight streaming technology allows us to map work to multiple CS-2s the exact same way we do it for one. You don’t have to partition, you don’t have to run model parallel. You basically compile to one CS-2 and you copy that config to n number of CS-2s, that’s it. The only thing you do is shard the data.”
Even the decision to run with the traditional pipeline mode or weight streaming mode is taken care of internally. Models larger than BERT and beyond GPT-2 or GPT-3 will trigger the switch to weight streaming mode, Feldman said, adding, “you write your TensorFlow or PyTorch code, and we take care of everything else.”
Cerebras has also enabled a feature to leverage the efficiencies of sparsity that saves time and energy. “What we can do because of our fine-grained dataflow architecture is that we never multiple by zero,” said Feldman. “It is enabled by technologies in the chip, and foremost massive memory bandwidth,” said Feldman.
“This means if your model has 50 percent sparsity, the Cerebras system can do it twice as fast,” he added.
While envisioning a future where 192 CS-2 machines work together as one system, Feldman believes a realistic near-term goal is to stand up 16 and 32 node clusters. The company has GPT-3 layers running on the CS-2, and they expect to show additional performance “on some of the largest networks” within months.

Linear performance scaling to 192 CS-2s. Projections based on Scaling Laws for Neural Language Models [OpenAI].
The news drew positive comments from market-watchers in the space.
“The wafer-scale approach is unique and clearly better for big models than much smaller GPUs,” said Linley Gwennap, president and principal analyst of The Linley Group. “By coupling the WSE with the new MemoryX and SwarmX technology, Cerebras has created what should be the industry’s best solution for training very large neural networks. Streaming the weights is a unique idea that hasn’t been tried, so it’s unclear exactly how much better this approach will be, but the ability to store even the largest model layers in the WSE gives Cerebras a big leg up on these enormous models.”
The market for models with billions of parameters is small today but should grow quickly, said Gwennap. “For the most part, these models remain experimental and aren’t yet used in production,” he added. “But even a handful of customers buying 16-32 system clusters would be a big revenue boost for Cerebras. The main obstacle to deploying these models is the long time that it takes to train them on GPUs, so the faster Cerebras can train the models, the sooner customers can move these models into production, which will require purchases of many more systems.”
Karl Freund, founder and principal analyst of Cambrian AI Research, said he’s been wondering how Cerebras was going to be able to run huge models and provide the scalability needed. “Models are doubling every 3.5 months,” Freund told HPCwire. “Nvidia has a solution coming: Grace (Arm CPU). Cerebras’ solution provides scads of memory AND data prep processing. I think the company has benefited greatly by the close relationships they have developed with researchers.”
Cerebras’ customer base for its CS systems include multiple DOE labs in the U.S., EPCC in the UK, as well as commercial sites GlaxoSmithKline and AstraZeneca.
MemoryX and SwarmX products will begin shipping in Q4 of this year, Cerebras said. Pricing was not disclosed.
This article first appeared on sister website HPCwire.






