



Machine Learning Speeds Up and Reduces Errors in Cloud Migrations

There are three fundamental questions organizations must ask when considering a migration of applications residing in their on-premises data center to a public cloud:
- Will my applications perform as needed in the cloud?
- How much will it cost to run my applications in a public cloud?
- Which public cloud provider is the best choice for my applications?
These answers should all be determined before migrating any applications to the cloud to ensure that the move is efficient, and that once in the cloud, applications can be managed effectively for cost, performance, and availability.
The complicating factor is that most organizations have hundreds or even thousands of applications running in their data centers—far too many to determine the requirements of each one individually. As an analogy, if I gave you hundreds or thousands of pieces of sheet music, you could read the notes of each one individually, but it would be impossible for you to categorize the sheet music into genres: classical, jazz, country, and so on. However, if you listened to several pieces of music, you’d be able to identify their genres right away.
The sheer number of applications most organizations have and the diversity of their resource requirements makes getting a true picture of performance and cost before moving applications to the cloud a huge task. The best way to simplify and accelerate the analysis is to use machine learning.
Using Automated Pattern Recognition
Through automated pattern recognition, machine learning can reduce the actual number of workloads to representative synthetic workloads based on their usage of CPU, memory, network, and storage resources (See Figure 1).
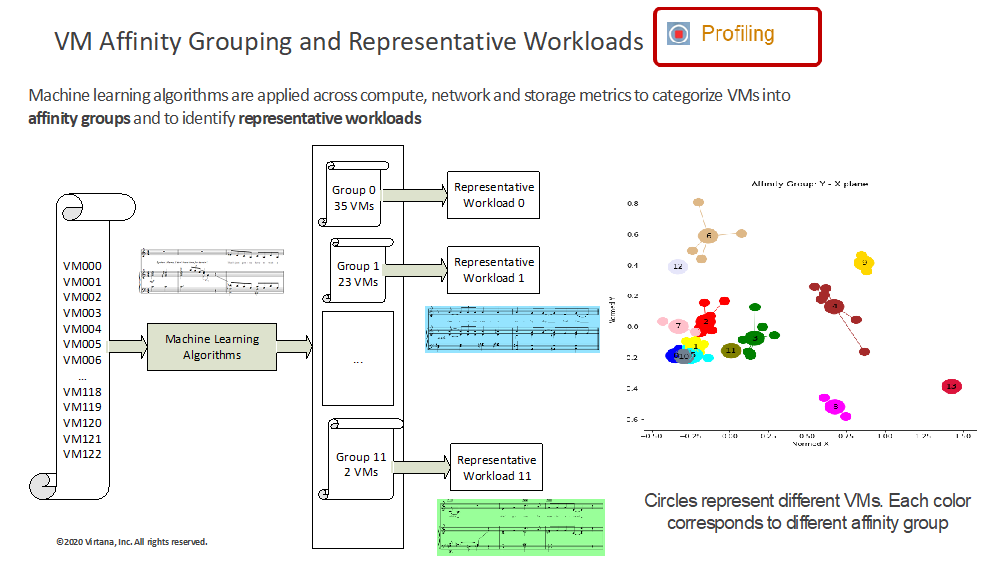 The groups represent sets of application workloads that are similar to each other in terms of their resource requirements and can therefore be tested and moved together. Using this methodology, hundreds or thousands of workloads can be distilled into a small set of synthetic workloads—often 15 or less. (See Figure 2)
The groups represent sets of application workloads that are similar to each other in terms of their resource requirements and can therefore be tested and moved together. Using this methodology, hundreds or thousands of workloads can be distilled into a small set of synthetic workloads—often 15 or less. (See Figure 2)
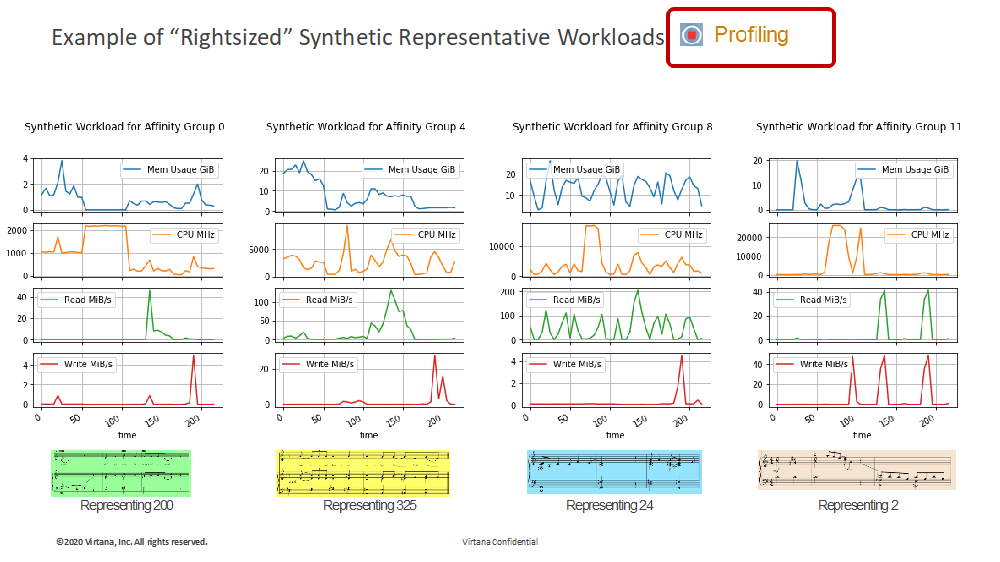
Once the representative synthetic workloads are determined, cloud configurations available from various public cloud providers can be compared, fine-tuned for performance, and costs can be estimated. To verify performance and cost, the workloads should be replayed in the various cloud configurations before any decisions are made about where they should be moved.
The ability to categorize workloads by CPU utilization is pretty common, and while it’s necessary, it’s not sufficient. To get the most accurate performance and cost estimates, workloads must be categorized based on all important cloud resources, including CPU, memory, disk I/O and throughput, storage used, and network utilization before cloud configurations are selected and workloads replayed.
The Importance of Profiling
Unless all cloud resources are included in the simulations using machine learning, a company is still flying blind. Profiling provides a detailed flight plan.
In the past six months, the need for automated profiling was exacerbated when a large majority of companies stepped up the pace of their public cloud migrations due to the pandemic. When the pandemic hit, companies had little choice but to move applications to the cloud, almost overnight. Their data centers were not built for the instant tsunami-sized jolt of increased load created by employees now working from home. Procurement of new on-premises hardware in the timeframe necessary wasn’t practical or in their long-term plans. However, while their desire was always to move more applications to the cloud. This forced “rush to the cloud” resulted in less thoughtful and less efficient migration plans, which increased the cost of both migrating and managing their applications in the cloud.
The cost implications of simply lifting and shifting applications “as is” to the cloud has been substantiated by Gartner. The firm found that organizations that have done this overspent on cloud services by up to 70%.
This level of overspend might strain credibility. But unlike traditional technology purchases, which are fixed assets with known prices, the cloud is an on-demand, pay-as-you-go service typically procured by a project engineer. He or she is armed with a credit card often outside a company’s established finance and procurement processes. The reality of moving to the cloud is that unpredictable variations in costs month to month are commonplace and create unintended havoc. The issues are usually the result of poor planning, difficulty in forecasting demand, and a business model that favors cloud providers, not customers.
By leveraging machine learning multi-cloud migration readiness technologies, Global 2000 companies are able to map their existing infrastructure topology, simulate, and validate optimum performance and cost management prior to lifting and shifting any applications.
About the Author
 Scott Leatherman is the chief transformation officer of Virtana, a cloud migration and optimization platform provider. He previously worked as the chief marketing officer for product analytics vendor, Interana, and for SAP, where he served in a variety of roles, including global vice president of marketing. He also was the senior director solution marketing and ecosystem development for the former compliance software maker, Virsa Systems, which was acquired by SAP. Leatherman earned a bachelor’s degree in advertising from San Jose State University.
Scott Leatherman is the chief transformation officer of Virtana, a cloud migration and optimization platform provider. He previously worked as the chief marketing officer for product analytics vendor, Interana, and for SAP, where he served in a variety of roles, including global vice president of marketing. He also was the senior director solution marketing and ecosystem development for the former compliance software maker, Virsa Systems, which was acquired by SAP. Leatherman earned a bachelor’s degree in advertising from San Jose State University.






