



ISC 2020: Hoefler’s Virtual Tour of ML Trends in 9 Slides

The ISC20 experience this year via livestreaming and pre-recordings is interesting and perhaps a bit odd. That said presenters’ efforts to condense their comments makes for economic use of your time. Torsten Hoefler’s whirlwind 12-minute tour of ML is a great example. Hoefler, leader of the planned ISC20 Machine Learning Day, does a nice job scanning a few recent industry highlights and whetting one’s appetite for next year by summarizing the ML sessions that had been planned.
Presented here are a few of his lightly-edited comments and slides. (Link to video)
MICROSOFT BUILDS MAMMOUTH AI SYSTEM

Torsten Hoefler, ETH Zurich
“Let me start a little bit about the interesting industry developments. Here we have the long-term player, Google Cloud. The news is that you can actually rent a TPU pod with about 100 petaflops brain float performance (Brain Floating Point Format, Bfloat16), which is just quite amazing. Even though it is a reduced precision format, so only eight exponent bits and seven mantissa bits – so maybe not suitable for scientific computing but perfectly suitable for machine learning. [Other] news and this was nearly a year ago is you can also buy a mini TPU in Raspberry Pi format, which unfortunately only support six bit floating point but it supports four teraflops per second at only two watts. Quite amazing,” said Hoefler.
“Up next is another very big company. Microsoft pledged $1 billion for OpenAI to support the holy grail of artificial intelligence, general intelligence. Basically developing models that go way beyond what we are used to today where we have to fine tune them to tasks. I will talk about this in a couple of minutes. Microsoft recently announced that they built an AI supercomputer, which is quite a respectable machine. They assess that it would be in the top five of the Top500 list. It has about 285,000 CPU cores, 10,000 GPUs and 400 gigabit per second network connectivity. You can read more in the Microsoft block (slide). Kevin Scott, the CTO of Microsoft, has given a wonderful talk about that machine as well.”
 Talking about Nvidia’s latest A100 GPU, Hoefler said, “This is a true engineering marvel. So getting to the maximum size of the reticle that you can build today, so 820 something square millimeters out of the maximum 850. [It has] 54 billion transistors and very impressive datasheet as we can see here. So number of [FP64 and FP32 CUDA cores] is going up. The number of tensor cores is slightly going down as is the frequency however the overall performance is just incredibly impressive.
Talking about Nvidia’s latest A100 GPU, Hoefler said, “This is a true engineering marvel. So getting to the maximum size of the reticle that you can build today, so 820 something square millimeters out of the maximum 850. [It has] 54 billion transistors and very impressive datasheet as we can see here. So number of [FP64 and FP32 CUDA cores] is going up. The number of tensor cores is slightly going down as is the frequency however the overall performance is just incredibly impressive.
“[Here’s another] interesting news item. If you thought as a scientific computing person, you could get away without using tensor cores, unfortunately if you want to achieve peak performance on that architecture, with FP64, even, you have to use tensor cores. It also has quite impressive memory bandwidth. I don’t want to go through all of this. One interesting feature with these tensor cores is now that there’s a new format, a TF32, even though I would have called it for fairness, TF19, because actually, it only has 19 significant bits that are used for the computation, but it’s backwards compatible to 32-bit calculations, which makes it quite interesting for legacy codes. I’m not so sure if this is very useful for newly tuned codes, because at the end, what’s going to happen with this format is you’re going to use the full memory bandwidth of an FP32 or 32 bits for every single calculation and you’re only performing that calculation in 16-bit accuracy, of course, with a 32-bit accumulator. So that’s a wonderful backwards compatibility feature,” the said.
 TRAINING A MODEL WITH 175 BILLION PARAMETERS
TRAINING A MODEL WITH 175 BILLION PARAMETERS
“We had very interesting [work] in the recent weeks where a new application is showing quite massive [improvement]. I mean OpenAI’s GPT-3 models. So OpenAI has this history of these GPT (generative pretrained transformer) models, where they train very large transformers in a generative setting. GPT3 is the largest one of those and probably the largest machine learning model ever trained. It has 175 billion parameters. So if you store this with two bytes per parameter, so just 16 bits for each parameter, that’s going to be [a] 350-gigabyte model size. That’s just a model size. Imagine you want to run inference on this; even inference is quite expensive, but training is even more expensive,” said Hoefler adding it would cost “$12 million to train that model in just in GPU credits.’
“There’s a wonderful paper out of OpenAI (June 2020) that explains what you can do with this model. And it’s quite astonishing. So this model is actually a so-called few-shot learner. The idea is you have a large trained model that is trained on a very large corpus that was basically grabbed off the internet. But you don’t fine tune it to the specific tasks. You tune it to specify the task during inference time. So there’s the so-called few-shot setting and the zero-shot setting. So the zero-shot setting is easiest to explain, it basically behaves like a human. I ask the model, please translate cat from English to French, and it will [respond with] that prospective French word. That is a very interesting feature of this network, but it can actually do it, and it achieves state-of-the-art and better results [using] these zero-shot training settings.
“A few-shots basically means that I present a couple of examples to the model. So I provide a series of translations, so cat, and then [a few more] French terms, usually on the order of 10 to 50. This model outperforms pretty much all the state of the art. So you can read the paper, if you want to learn about all the wonderful results that OpenAI has achieved with this. They have not done fine tuning, by the way, probably it is too expensive. I would be very, very curious to see what would happen if you fine-tuned that massive model. But it’s so expensive that they couldn’t even retrain it after they found a bug in their data cleaning procedure. So they had to work around the bug and there are some, some interesting notes in the paper.
“From an HPC perspective, this table (slide below) from that paper is one of the most important tables. You can see here the number of parameters is quite massive and has been growing over time and you can also see the total flops required to train so we are essentially at 314 zetaflops. I’ve made a little analysis to see what this means, so 314 zettaflop, of course mixed-precision FP16 and FP32 most likely. [This would require] 155 years on a V100 if we assume very high performance, like the record performance that has been published. Or that is 400 megawatt hours of that same GPU or for that single training run nearly $4 million, assuming zero communication overhead and perfect use of these GPUs,” said Hoefler.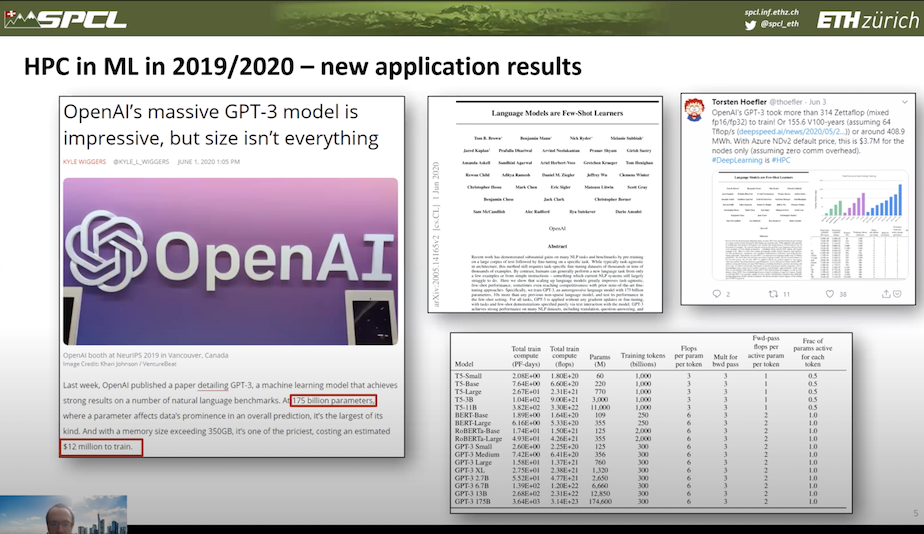
THE 2020 ML DAY LINEUP…MAYBE NEXT YEAR
“Let me now get a little bit more into the ML day program we had planned for this year and now have planned for next year. The first planned session was on machine learning for climate and weather to be hosted by Peter Dueben, who fortunately sent me some slides that summarize what is going on there.
“The idea here is that we have the earth of course that we are simulating, [and it] is really large and the solution is very, very limited, because we cannot represent every single air particle essentially in a computer. We have to have a very limited resolution at the kilometer scale., but unfortunately, the system itself that we are simulating has very chaotic dynamics; it has all kinds of so called sub-grid effects that are very, very hard to capture in scientific simulations. These processes are simply not resolved and that is one of the bigger problems, especially in earth system component models that are connected in non-trivial ways.”
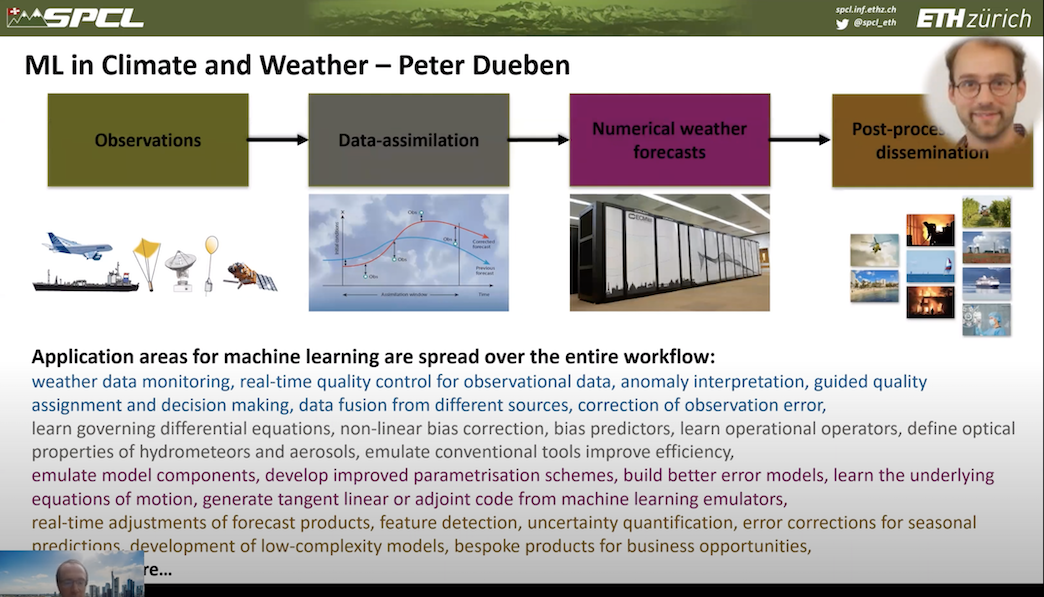
“However, what we have is very large number of observations. So satellite data, we have plane data – well, we had plane data when the planes were still flying. We have a lot of data that we could train machine learning models on. The idea now is, why don’t we use these machine learning models for multiple different opportunities. Here’s some of the opportunities that we could we could talk about,” said Hoefler.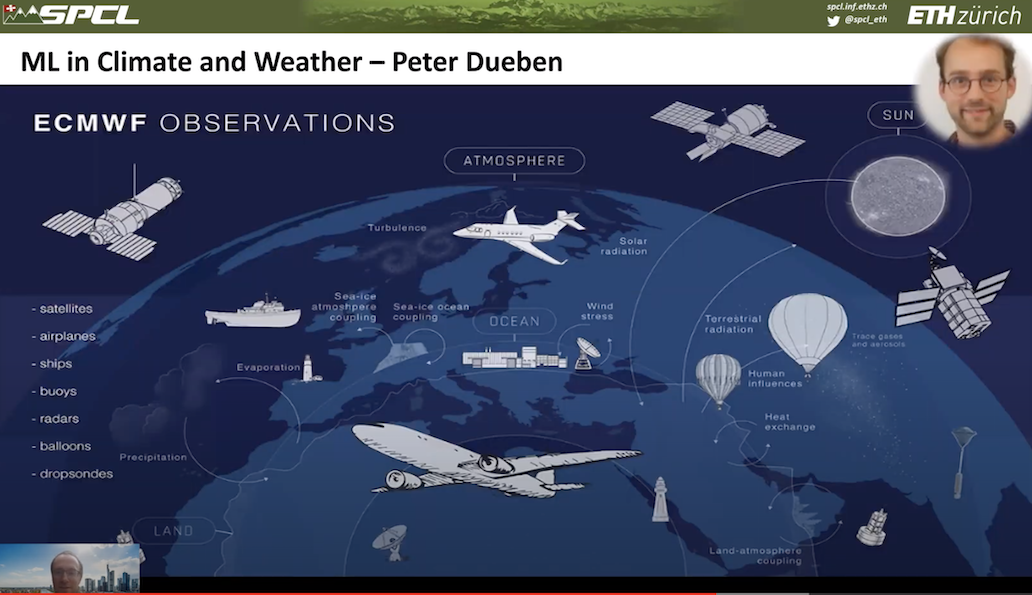
“We could refine the observations [and] this is something that the community is already doing. We could refine the data assimilation process. We could help with numerical weather forecasting itself, so we could accelerate it using machine learning accelerators, for example the TPU or these low precision tensor cores, and then implement post processing and help with post processing and make simulations even less require it or improve the data that comes out of the simulation. So this is actually something that we have done in my lab.”
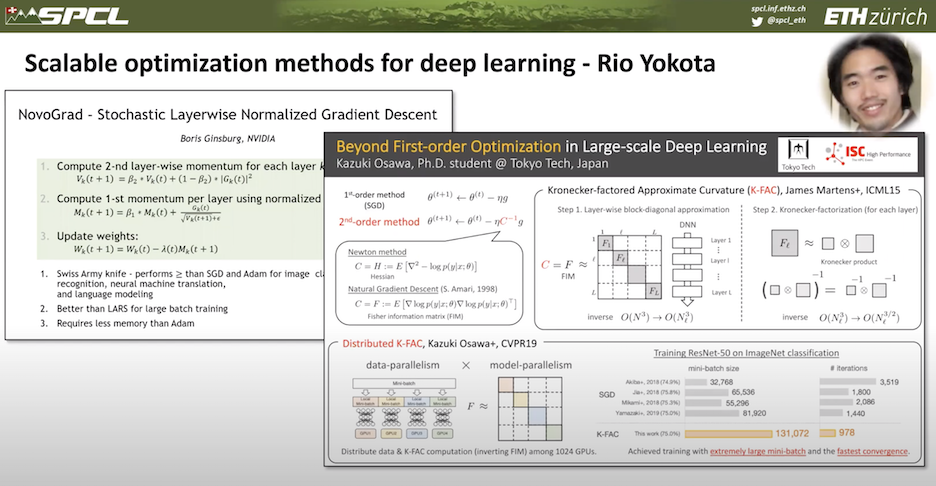
“Then the second session was to be organized by Rio Yokota from Tokyo Tech. And he invited a set of wonderful speakers. So first Boris Ginsburg from Nvidia talking about the latest, greatest developments in stochastic device and the gradient descent methods and how to accelerate this with Nvidia GPUs. [This has been done] with one of his PhD students looking at second order optimization or higher order optimization in general, which can not only lead to more accurate models, but also it can also lead in certain circumstances to higher performance. This is a very, very interesting research direction that we are also embarking in. Then Yang You who just graduated from Berkeley and is now taking an assistant professor position on how to work with very, very, large scale systems. So using the LAMB optimizer that we all know and love.”
“The third session was organized by Maryam Dehnavi and Tal Ben-Nun and they invited Amir Gholami (UC Berkeley) to talk about their integrated approach to deep neural network design. They have a nice set of methods that you can combine into a tool chain to do end-to-end training. And then Ce Zhang from ETH Zurich who was going to talk about various ways to implement distributed training ranging from centralized synchronous to synchronous, asynchronous, and then to various decentralized, synchronous and asynchronous training methods. We hope that we can have all these speakers appear in the forthcoming years, and we can we can listen to what they have to say.”

Link to video, https://2020.isc-program.com/presentation/?id=inv_sp139&sess=sess348
Hoefler Bio
Torsten Hoefler is an Associate Professor of Computer Science at ETH Zürich, Switzerland. Before joining ETH, he led the performance modeling and simulation efforts of parallel petascale applications for the NSF-funded Blue Waters project at NCSA/UIUC. He is also a key member of the Message Passing Interface (MPI) Forum where he chairs the “Collective Operations and Topologies” working group. Torsten won best paper awards at the ACM/IEEE Supercomputing Conference SC10, SC13, SC14, EuroMPI’13,
HPDC’15, HPDC’16, IPDPS’15, and other conferences. He published numerous peer-reviewed scientific conference and journal articles and authored chapters of the MPI-2.2 and MPI-3.0 standards. He received the Latsis prize of ETH Zurich as well as an ERC starting grant in 2015. His research interests revolve around the central topic of “Performance-centric System Design” and include scalable networks, parallel programming techniques, and performance modeling. Additional information about Torsten can be found on his homepage at htor.inf.ethz.ch.






