



Nvidia, Google Tie in Second MLPerf Training ‘At-Scale’ Round

Results for the second round of the AI benchmarking suite known as MLPerf were published today with Google Cloud and Nvidia each picking up three wins in the at-scale division. Google for ResNet-50, Transformer and SSD; Nvidia for GNMT, Reinforcement Learning and Mask R-CNN.
In total, Nvidia claimed eight new performance records, three in the at-scale category, with its V100-based clusters, and Google achieved three top at-scale results for its TPU v3 Pods. Like the inaugural MLPerf training round, announced last December, the second round is primarily a two-horse race. Google, Nvidia and Intel are the only companies who submitted to the closed division and Intel only submitted to one out of the six categories.
Given all the emerging AI silicon startups with heady performance claims, why haven't any shown up on the MLPerf results?
"Today there really isn't a production-ready silicon chip that can compete in this space for training," Karl Freund, consulting lead for HPC and deep learning at industry analyst group Moor Insights & Strategy, told HPCwire. "If you want to do your training in the cloud, you’re going to use Google; if you want to do training on site, you’re going to have to use Nvidia.
"Even by the end of the year, when some companies may have a production ready chip, going from there to having a thousand-chip farm tuned and running at scale to run these benchmarks, it's going to be another year. And running these benchmarks is really expensive."

MLPerf Training v0.6 benchmark suite (Source: MLPerf)
Minute Training
Both Nvidia with its DGX-2 SuperPod V100-powered nodes and Google with its TPU Pods achieved "at scale" training times on four of the six benchmarks of about a minute or two.
"There's a class of models that can now be trained in around a minute," said Paresh Kharya, director of product management for accelerated computing at Nvidia, in a pre-briefing held for media, citing image classification with ResNet-50, Transformer, GNMT and SSD. "However, there are still some harder problems that take many minutes to train even with the latest state-of-the-art infrastructure. One of the problems is reinforcement learning. We could train the MiniGo model in just under 14 minutes – that was the only submission that Intel had and there was no submission from Google on that model."
Nvidia said it achieved 20-80 percent more throughput in this testing round on the same DGX-2 hardware used seven months ago, due to software innovations, including to its CUDA-X AI software stack. And since launch in 2017, the same DGX-1 server trains the ResNet-50 model 4 times faster, according to Nvidia.
Detailing Google's results in a blog post, Zak Stone, senior product manager for Cloud TPUs with the Google Brain Team, stated, "Google Cloud is the first public cloud provider to outperform on-premise systems when running large-scale, industry-standard ML training workloads of Transformer, SSD, and ResNet-50. In the Transformer and SSD categories, Cloud TPU v3 Pods trained models over 84 percent faster than the fastest on-premise systems in the MLPerf Closed Division."
Google added that compared to the initial alpha results last December, it submitted results on a wider range of tests and employed a full Cloud TPU v3 Pod for the first time. "This additional scale and software optimizations improved our results by up to 62x," said Google.
Intel reported a measurement of 14.43 minutes to train MiniGo on 32 nodes of a 2-socket Xeon Platinum 8260L processor cluster system. On a single node of a 2-socket Xeon Platinum 9280 system, Intel completed training of the MiniGo model in 77.95 minutes. "These results demonstrate that 2nd generation Intel Xeon Scalable Processors can deliver comparable reinforcement learning (MiniGO) training time as the best accelerator performance in today’s MLPerf 0.6 result publication," the company said in a statement.
Nvidia was the only company that submitted across all six categories of the industry benchmark suite (which encompasses image classification, object detection, translation, and reinforcement learning). After abstaining from the reinforcement learning category in the previous iteration, Nvidia participated this time, noting that the benchmark had been "refactored by MLPerf to allow for parallelism and meaningful acceleration."
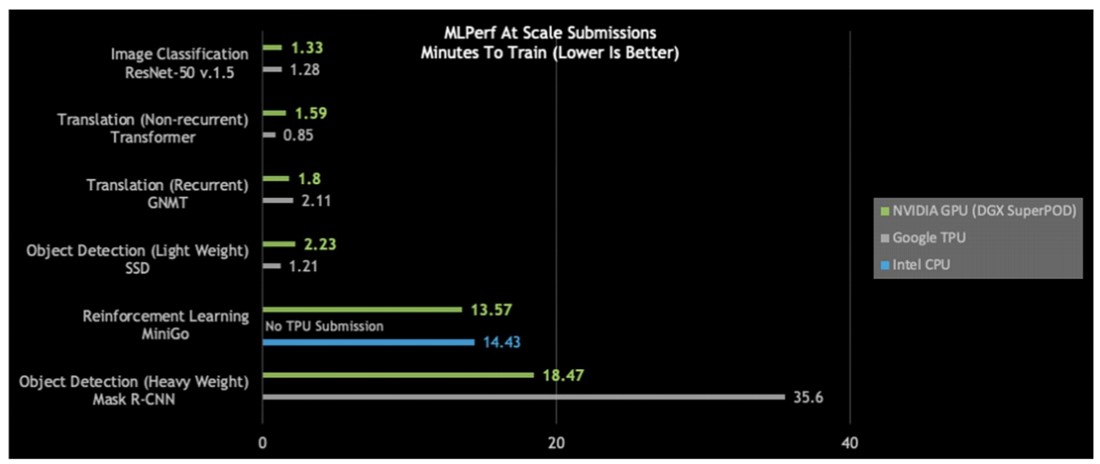
MLPerf 0.6 Performance at Max Scale. Top to bottom, omitting the "reinforcement learning/MiniGo" category, the Nvidia DGX-2H test machines use 1,536, 480, 256, 240 and 192 V100 GPUs, respectively. The Cloud TPU Pod submissions used 1,024, 1,024, 512, 1,024, and 128 TPU v3.0 chips, respectively. The Intel (MiniGo) submission was conducted on 64 Xeon Platinum 8260L CPUs, going up against three Nvidia DGX-1s (24 V100s). Graphic courtesy Nvidia.
On a “per accelerator” basis, Nvidia swept five out of six categories (see chart below right). Testing was done on one DGX-2H node, comprised of 16 V100s connected via Nvidia's NVLink switch; except for MiniGo, which was done on one Nvidia DGX-1 (8 V100s). On the ImageNet test, Google's TPUv3.32 system outperformed Nvidia's DGX-2H machine; the math works out to 11.25 hours to train the model on one TPUv3 chip versus 14.06 hours on one Nvidia V100.
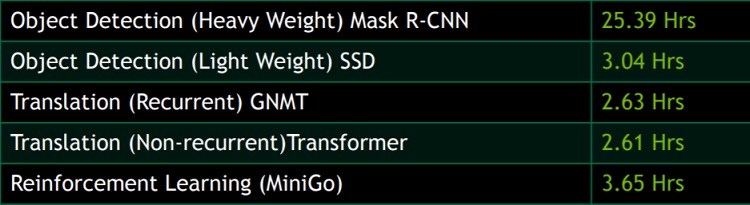
Nvidia's Per-Accelerator results - hours to train normalized to one V100 GPU
While competing on a per-accelerator basis might be a lower barrier to entry for newcomers, Google and Nvidia would probably argue that at-scale is mostly what companies care about. "For training, they are not going to wait half a day or more to get their results back," noted Freund. "They are going to spend the money to get the training done, so they need to see what the results are at scale.

Nvidia's DGX-2 SuperPod
"Running these benchmarks is very expensive and only the large companies need apply," added Freund. "Right now, the industry really only has two alternatives for training. Inference will be a different story. There will be close to a score of inference benchmarks published in the next 12 months because it's a lot easier to do and it's a wide open market. There's not an 800lb gorilla sitting on top of it, called Nvidia. There are going to be a lot of startups competing for that space. For training: there's only two companies now; there will be three when Intel launches Nervana. But it's going to [continue to] be a very small number."

MLPerf supporting companies (as of July 09, 2019) – click-to-enlarge
MLPerf is an AI benchmarking suite “for measuring the speed of machine learning software and hardware.” Started by a small group from academia and industry–including Google, Baidu, Intel, AMD, Harvard and Stanford–the project has grown considerably since launching in May 2018. At last count (July 9, 2019), the website lists more than 40 supporting companies: the aforementioned Google, Intel, AMD and Baidu as well as ARM, Nvidia, Cray, Cisco, Microsoft and others (notably, not IBM or Amazon).
According to the consortium, the training benchmark is defined by a dataset and quality target and also provides a reference implementation for each benchmark that uses a specific model. Time to train a model at a specified quality target is the main performance metric. There are six "active" benchmarks in version v0.6 of the suite. (The recommendation benchmark that was part of the v0.5 suite is currently being reviewed.)
MLPerf recently announced the launch of an inference-focused benchmark (see our coverage here); the consortium's website indicates results for the 0.5 version are due Sept. 6.
This article originally appeared in sister publication HPCwire.






