



Looking at AI/ML Edge-Core-Cloud Workflows

Edge computing is emerging as the killer app for AI and ML, with staggering growth predictions. Projections indicate there will be more than 50 billion internet-connected objects and devices by 2020, representing an $11 trillion market opportunity, across all major verticals combined. The global autonomous vehicle market alone is expected to surpass $50 billion this year, and $550 billion by 2026.
Edge devices feed data to AI, machine, and deep learning applications continuously, ingesting, training, inferencing, monitoring, and archiving. The accuracy and predictability of these data pipelines is only as good as the data sets they train on, and effectiveness is only as good as non-blocking, continuous access to these data sets.
While most of these processes occur at the core (on-premises data center), increasingly data pipelines must span edge to core to cloud or multi-cloud, and even edge to cloud to core. In this three-tiered architecture, storage services are designed, deployed and consumed somewhat differently. The edge drives the need for massive concurrency. The storage layer lies mostly on premises, in the core data center, to drive throughput. The compute layer drives the latency and can be on-prem or burst to cloud.
 For example when GPUs are busy, or when it’s more efficient to perform a compute task in the cloud, AWS or GCP needs to access data on the edge, in the core, or another cloud. Or, in the case of a highly classified project, it’s likely confidential data needs to be stored on premises, but used by frameworks like AWS Sagemaker and Kubeflow in the cloud.
For example when GPUs are busy, or when it’s more efficient to perform a compute task in the cloud, AWS or GCP needs to access data on the edge, in the core, or another cloud. Or, in the case of a highly classified project, it’s likely confidential data needs to be stored on premises, but used by frameworks like AWS Sagemaker and Kubeflow in the cloud.
The I/O Problem
Let’s look at the storage requirements of an edge-to-core-to-cloud pipeline, particularly now that GPUs have utterly transformed compute, and microservices and containers are the preferred deployment mechanisms thanks to their portability, elasticity and efficiency. Storage services need to:
- Match the I/O of the compute layer for throughput and concurrency at petabyte scale. For example, NVIDIA GPU supercomputers provide a massively parallel compute layer, with 1 PFLOPs (petaflops, or floating-point operations per second) of computing power per DGX-1. The storage layer needs to keep up.
- Organize and contextualize the data, for example metadata tagging, automated placement on the proper storage or geographic location, etc.
- Provide a global namespace capable of spanning multiple regions and clouds, scalable to many petabytes to accommodate large training sets.
- Offer native S3 API integration for in-place data analytics with frameworks like TensorFlow, and workflow engines like Nivida GPU Cloud and Kubeflow.
- Provide persistent storage for containerized applications with Kubernetes CSI plug-ins.
- Allow access to data using file and/or object protocols.
- Assure compatibility with a growing ecosystem of vendors of specialty AI/ML tools that must integrate and interact with data.
Traditional direct-attached or SAN architectures fall short on these demands, one reason being they create a siloed infrastructure where data access is constrained by specialty protocols, platforms, or operating systems. An edge-to-core-to-cloud workflow requires universal data access, so data can flow between, and be used at, any point in the pipeline.
The Stages Problem
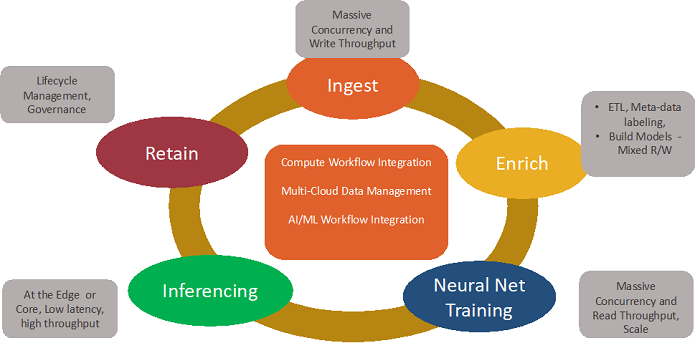
Another big storage challenge is that each stage of the AI/ML workflow has fundamentally different I/O needs, such as bandwidth, latency, or mixed read/write handling for small and large files. Let’s look at what each stage needs.
Ingest
The storage infrastructure should be able to ingest at least 100 GB per second, with massive concurrency and parallelism to match the GPU compute layer. Many organizations are not getting the full value of their high-end GPU servers because the storage is too sluggish to deliver data.
Data ingest should be possible with NFS and/or CIFS, as well as cloud-native applications with S3 or SWIFT.
Enrich
Enriching the data includes middleware for labeling/tagging, version control, ETL processes that make data usable by another application, metadata management, all of which help in contextualizing, searching, supervised learning, modeling, and other, later workflow stages. The better the storage services are at enriching the data, the better the end results.
Train
The storage needs to enable in-place neural net training with native S3 support for Tensorflow-like frameworks, while again providing massive read concurrency. Training data sets reach enormous sizes, so this is the stage where scale-out storage is essential. With data sets in multi-petabyte ranges comes the need for a single namespace, so the data set, no matter how large, can be accessed by the best or most cost-efficient on-prem or cloud resources.
Infer
Storage services must support inferencing at the edge or the core. Delivering ultra-low latency, as opposed to ultra-high speed, is often the challenge at this stage. Inferencing is particularly challenging with autonomous vehicle hardware-in-the-loop (HIL) simulation systems, which need access to those large data sets, and hardware running on the vehicle itself, because the capabilities of these systems are limited compared to data center processors.
Retain
The benefits of public cloud storage, with its economy of scale and elasticity, are by now well understood, but concerns about data locality security, and fear of losing control prevent some businesses from using public cloud resources. Whether on-premises, cloud, multi-cloud, hybrid/both/all of the above, globally distributed storage services provide durability and availability, and maintain performance and stability even during expansion, updates or maintenance.
The sad reality is too many data scientists are bogged down in insufficient infrastructure for the requirements of the data pipeline, and thus unable to focus on the AI/ML strategy. Edge-to-core-to-cloud data flow is transformational, but it’s impossible on yesterday’s traditional storage infrastructures. A cloud-native, open-source data storage and management architecture allows for these workflows and frameworks, and scales to petabytes of storage and hundreds of gigabytes of bandwidth, to handle challenging AI/ML operations at each stage of the workflow.
Shailesh Manjrekar is head of product and AI/ML solutions at SwiftStack.






