



IBM Techies Pit Docker, KVM Against Linux Bare Metal

IBM has only recently caught the KVM bug, and has even gone so far as to create a variant of the KVM hypervisor that runs atop its Power8 systems when they run Linux. But if new performance statistics coming out of IBM Research are any guide, it looks like Big Blue will be porting the new Docker container technology to Power-based systems sometime soon.
A bunch of techies working in IBM's systems lab in Austin, Texas ginned up a bunch of benchmark tests to show how both KVM and Docker stacked up against bare metal iron running Linux. The tests were done on Xeon E5 processors from Intel, across a variety of different kinds of workloads that stressed the processors, memory hierarchy, and I/O subsystems of a server. The lessons presumably can be applied, in a very general way, to Power-based machines when and if they ever support Docker and get a more tuned up version of PowerKVM at some point. (Our assumption is that with the first release of PowerKVM, IBM still has some tuning to do to minimize the virtualization overhead.) The results of IBM's tests are absolutely useful for anyone examining the performance issues relating to Linux workloads running inside containers or virtual machines on X86 systems as compared to running them on bare metal.
Proprietary systems like IBM's z/OS (formerly known as MVS and OS/390) or IBM i (which used to be called OS/400) as well as OpenVMS from Hewlett-Packard (formerly Compaq and Digital Equipment before that) had very sophisticated operating system kernels workload managers that allowed them to isolate programs from each other on a shared system and to allocate specific resources to those programs. But in many cases, for security reasons or to run multiple operating systems on a single machine, workloads have to be more isolated than is possible with this subsystems approach. So virtual machine and logical partition hypervisors were created for these proprietary platforms as well. The point is, the IT industry has been wrestling with how to have a machine run multiple workloads concurrently to drive up utilization for a very long time, and there are always trade-offs.
IBM wanted to quantify the penalties, and in some cases, researchers found that there really were not many. In other cases, the performance overhead of KVM in particular was quite high. The tests that IBM has done illustrate that it is important to understand the architecture of the system and the software that is running on it to squeeze the most performance out of a machine. The upshot of all the tests is that Docker containers can sometimes deliver performance that is close to that of bare metal, and in many cases it offers significantly less overhead than KVM when used to isolate workloads. This is expected, given that Docker is a container (sometimes called a type 2 hypervisor) that shares a Linux kernel and sometimes a file system across all of the containers in the machine, which is distinct from a full-on, bare metal hypervisor (often called a type 1 hypervisor) that abstracts all of the underlying iron and runs multiple full copies of operating systems inside of virtual machines.

IThe test machine that IBM used in the lab was a System x3650 M4 server equipped with two eight-core Xeon E5-2665 v1 processors (these are of the "Sandy Bridge" family from early 2012) running at 2.4 GHz and 256 GB of main memory. With HyperThreading turned on, the machine presents 16 threads per socket to the operating system, and the two sockets are hooked together in a NUMA configuration through two QuickPath Interconnect (QPI) links. This is by no means a shiny new server, but it is akin to the vintage and type of machine installed in enterprise datacenters and cloud service providers these days. IBM loaded up Canonical's Ubuntu Server 13.10 (sporting the Linux 3.11.0 kernel) on the machines. The researchers sometimes ran tests on one socket and then both sockets to show the effect that NUMA clustering did – or did not – have on accelerating the performance of a particular workload.
On the STREAM memory bandwidth test, for instance, the difference between native bare-metal performance when Linux had control of one or both processors or running the test atop either Docker or KVM was negligible. The error bars are very tight for the STREAM test, in fact, On the Triad test, all three ways of running the test delivered about 25 GB/sec on one socket and about 45 GB/sec across two sockets. The STREAM test running in Docker was a tiny bit slower, and KVM a tiny bit slower still but certainly not enough to make anyone worry about the difference. The STREAM test has a very regular access pattern and therefore makes good use of the cache in the system, but IBM also used the RandomAccess test, which loads a dataset into the main memory that is much larger than the caches in the chips can hold and then hammers on it in a random fashion, to see how the three different ways of running the software would map:
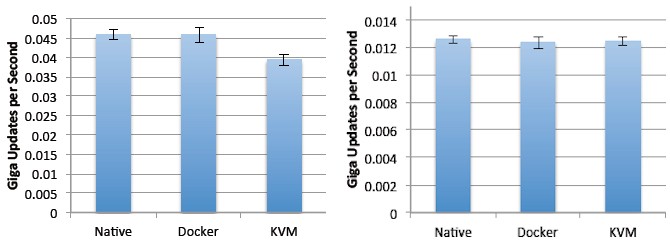
The set of data on the left in the chart above is when RandomAccess is restricted to running on one socket in the system, expressed in billions of updates per second, or GUPS. Again, Docker and bare metal seem to be on par, with KVM lagging a bit. When the dataset is allowed to span the second processor, the performance on RandomAccess does way, way down – even for the bare metal run of the test, and that is because half of the time any data that the benchmark wants is purposefully set up so it is going to be on the remote processor. The performance rate drops by more than a factor of three, and the differences between bare metal, Docker, and KVM are not huge.
On a block I/O storage test that grabbed data from an IBM FlashSystem 840, which is based on solid state disks, over 8 Gb/sec Fibre Channel links. On sequential reads and writes using 1 MB file sizes, once again the difference between bare metal, Docker, and KVM are negligible. On sequential reads, the system can sustain about 800 MB/sec and on sequential writes it is about 750 MB/sec with KVM being as little bit lower than Docker. However, running an I/O test with a random reads or writes really shows that KVM is imposing some penalties.
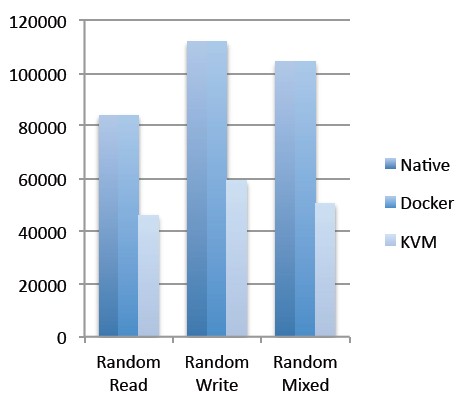
The Docker container rides atop the ext4 file system just like the native test did, and talks directly to the host bus adapter and then to the SSD, and therefore imposes no penalty at all on random read and write performance, as you can see in the chart above. But KVM has to have the virtio driver in the guest operating system and the QEMU hardware emulator underneath that, and this software radically cuts down on the I/O operations per second (IOPS) that can be served. (The random mixed bars shown above are 70 percent read, 30 percent write.) IBM also points out that with the hardware it was using, it should have been able to drive 1.5 GB/sec in sequential I/O and 350,000 IOPS in random I/O, showing that all three scenarios are not doing great in terms of extracting the performance out of that FlashSystem.
IBM also ran the Redis NoSQL data store and MySQL database through the benchmark paces on top of bare Linux, Docker, and KVM. Redis is a single-threaded workload that is sensitive to network latencies, and with the Linux host networking stack running with Docker, its throughput and latency are virtually the same as the bare-metal Linux. But if you use Docker with Network Address Translation (NAT) enabled, this network layer adds significant latencies and consumes CPU resources, which combine to cut down on Redis throughput. The IBM team says that running inside of KVM partitions, Redis is network bound and takes performance hits as data enters and exits the VM.
For the MySQL test, IBM chose the SysBench OLTP benchmark and used the InnoDB database engine. The configurations tested are varied, but the upshot is that the Docker penalty is around 2 percent with a high number of threads pushing the database, while KVM has an overhead that is 40 to 50 percent of CPU.
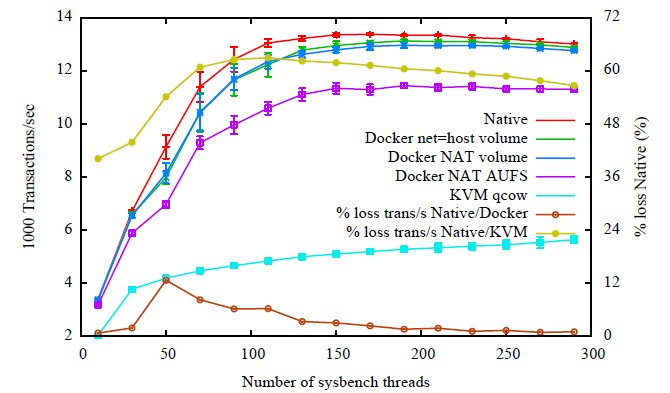
The KVM setup also imposed big penalties running the Linpack Fortran floating point math test, which solves a set of linear equations and largely multiples a scalar by a vector and adding the result to another vector to solve those equations. The native and Docker performance running Linpack, using Intel's Math Kernel Library and optimized for NUMA sharing between the two sockets, was able to deliver around 290 gigaflops, but the Linpack test running inside of a KVM partition could only hack 180 gigaflops. According to IBM, the NUMA memory access and physical topology of the server is actually not apparent to the KVM hypervisor, which sees it as a 32-way system with a single core per socket and it is the lack of knowledge about NUMA that hinders KVM performance. This, of course, can be fixed. And probably will be.






