



Nvidia Aims to Make AI a No-brainer with New Toolkit

Nvidia believes it has the antidote to the headaches of putting AI to work without the need to hire data scientists.
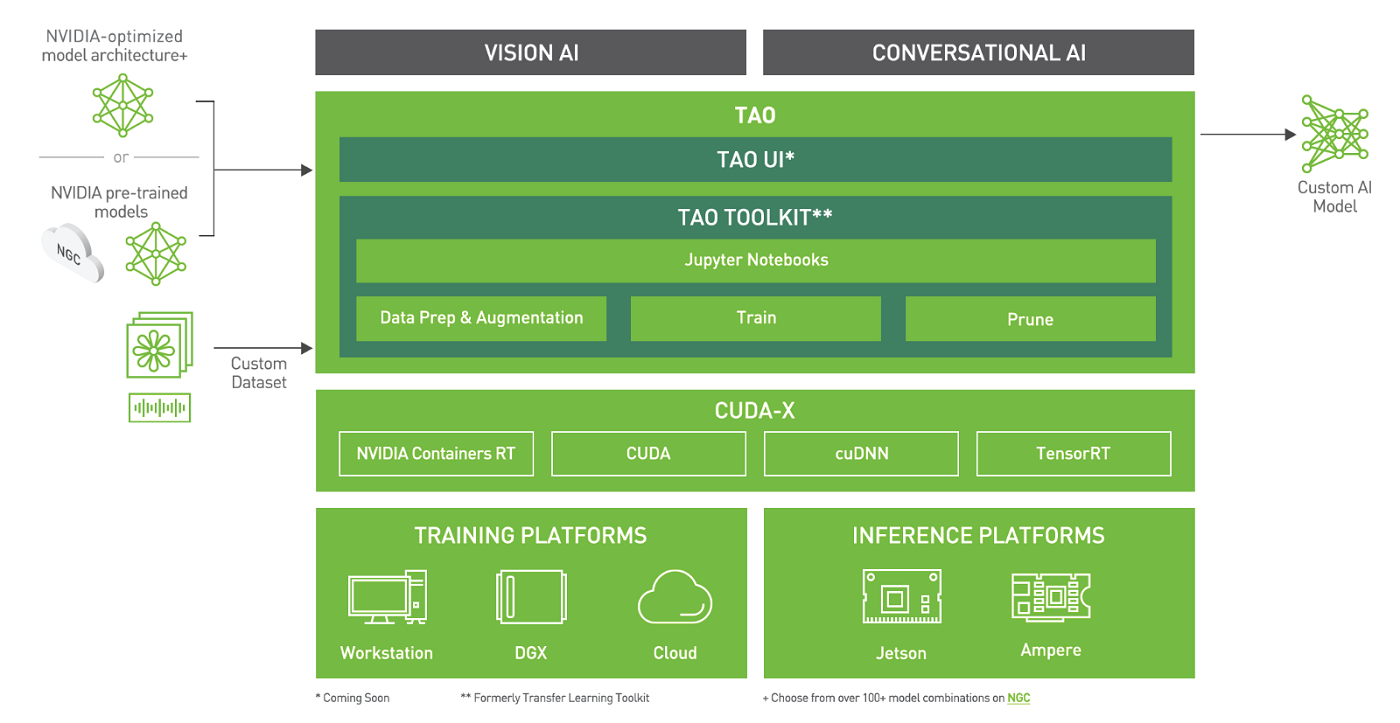
The TAO starter kit -- which stands for Train, Adapt and Optimize -- speeds up the process of creating AI models for speech and vision recognition.
"You don't really need the AI expertise. You don't even need to know all the different frameworks. And you can leverage ... pre-trained models which are highly accurate and are high performance," said Chintan Shah, product manager at Nvidia, during a press briefing.
The TAO framework is mostly designed for inferencing and some applications that apply to TAO include language translation and object detection in robots and cars.
"The assumption is the user has the annotated data," Shah said. "You train it with your own data and what TAO provides to you is it abstracts away the complexity of TensorFlow or PyTorch. You actually don't even need to know any of the deep learning frameworks," Shah said.
On the computer-vision side, the framework has task-specific models such as people-detection, vehicle detection and pose estimation. It also supports general-purpose applications like object detection model implementations such as YOLO v4 and EfficientNet.
On the speech side, the TAO framework has 20 to 25 models for applications such as speech recognition, text-to-speech and natural language processing. The TAO-based models can be deployed with Nvidia framework SDKs like DeepStream for video analytics or Riva for conversational AI.
Technically, there’s no limit to the model size as it supports tiny models like MobileNet, but can scale to larger models that have billions of parameters.
“It's just the limit is basically what the model supports. If you're trying to run a big language model on a small GPU, you probably will run out of memory and the compute resources very quickly. But we do have the ability to run to scale it to multi-GPU and multi-node as well," Shah said.
But TAO has a task-specific focus, mostly on speech recognition and computer vision. Larger and complex AI models broken up over large network of GPUs require better understanding of data as more information is fed into the system. At some point, these learning models require manual intervention based on what the output is.
"It's not something that TAO addresses, but we do recognize that as a bigger challenge, and we are actively working with our ecosystem partners who provide similar services," Shah said.
The TAO starter kit solves one of the biggest challenges of how to make AI easy to use in a time-efficient manner, said Jim McGregor, principal analyst at Tirias Research.
"Not everyone can hire data scientists, and there are not enough to hire. We're still trying to develop tools and techniques to help machines train and learn. Each bit that gets added to that pie is going to help," McGregor said.
The TAO toolkit may not be the optimal solution for all applications, but it is a good tool to prune out inefficiencies in AI models, which is an important step to ensure data flows through available hardware efficiently, McGregor said.
TAO uses low-code techniques to create AI models and train data. Developers can start off with a Jupyter notebook with a command line interface to bring in real and synthetic datasets for training.
A user can apply augmentation tools to improve or generalize the data, with one example being the transformation of images with spatial augmentation, rotation, or color transformation to change images from RGB to grayscale. This step also involves detection, segmentation and classification of data.
"This can really add variation in your dataset. This can help you generalize your model much better," Shah said.
Users can bring in the pre-trained models, and then jump to the next step of pruning and optimizing the model.
"You can trim down the model, compress the size of the model. This can make it run a lot faster," Shah said.
The optimization step also provides the ability to quantize the model to specific 32-bit or 16-bit floating point operations to extract the most out of hardware.
"You can get up to 4x improvement in inference performance," Shah said.
The toolkit is available as a free download from Nvidia's website. Nvidia's Shah also said the company is looking at making Nvidia's GPU resources through its cloud-based service called Launchpad, where customers can experiment with various products that include Tao.






