



How FPGAs Accelerate Financial Services Workloads

source: Shutterstock
Editor’s note: While FSI companies are unlikely, for competitive reasons, to disclose their FPGA strategies, James Reinders offers insights into the case for FPGAs as accelerators for FSI by discussing performance, power, size, latency, jitter and inline processing.
Even before the recent global financial crisis (2007-2008) led to a rapid growth in demand for risk analytics, the computational demands of the financial services industry (FSI) were substantial. FSI computing needs are driven by all forms of trading including High-Frequency Trading (HFT) and algorithmic trading, risk analytics (fraud detection/prevention including real-time fraud detection, and regulatory compliance), and data security and handling (including encrypt/decrypt, compress/decompress). There is a large spectrum of the workloads within FSI because their needs encompass the same growing needs of any enterprise as well as their demanding FSI specific workloads.
FPGAs became a part of HFT years ago because of their combination of reprogrammability, performance, low latency and low jitter. If not for the crisis, FPGAs might primarily live in the world of HFT. But with the crisis, that changed. The art of consuming and making sense out of a new deluge of data may have been pioneered by high-frequency traders, but has been taken to new heights by risk analytics workloads.
The Killer App: Risk Analytics
Pre-crisis, risk analytics workloads were mostly run offline between trading hours in order to prepare for the next trading day. Those days are long gone; risk analytics workloads now run continuously and include work required for regulatory compliance, such as Fundamental Review of the Trading Book (FRTB) and Comprehensive Capital Analysis and Review (CCAR). These workloads are fed hundreds of millions of pieces of information per second in their quest to track risk factors. This input data is highly unstructured, very high volume and has a wide variation of veracity (how much can we trust such data?). To obtain more data to inject, written publications, video, and voice data have been added into the streams of real time input. Other than available compute power, there is little to prevent attempting to feed these workloads anything and everything that might assist in generating better risk calculations. These new workloads do not necessarily result in frequent output, as would be the case with high-frequency trading, but driving real time tracking and response can be similarly high-stakes in terms of monetary value.
FPGAs as Accelerators
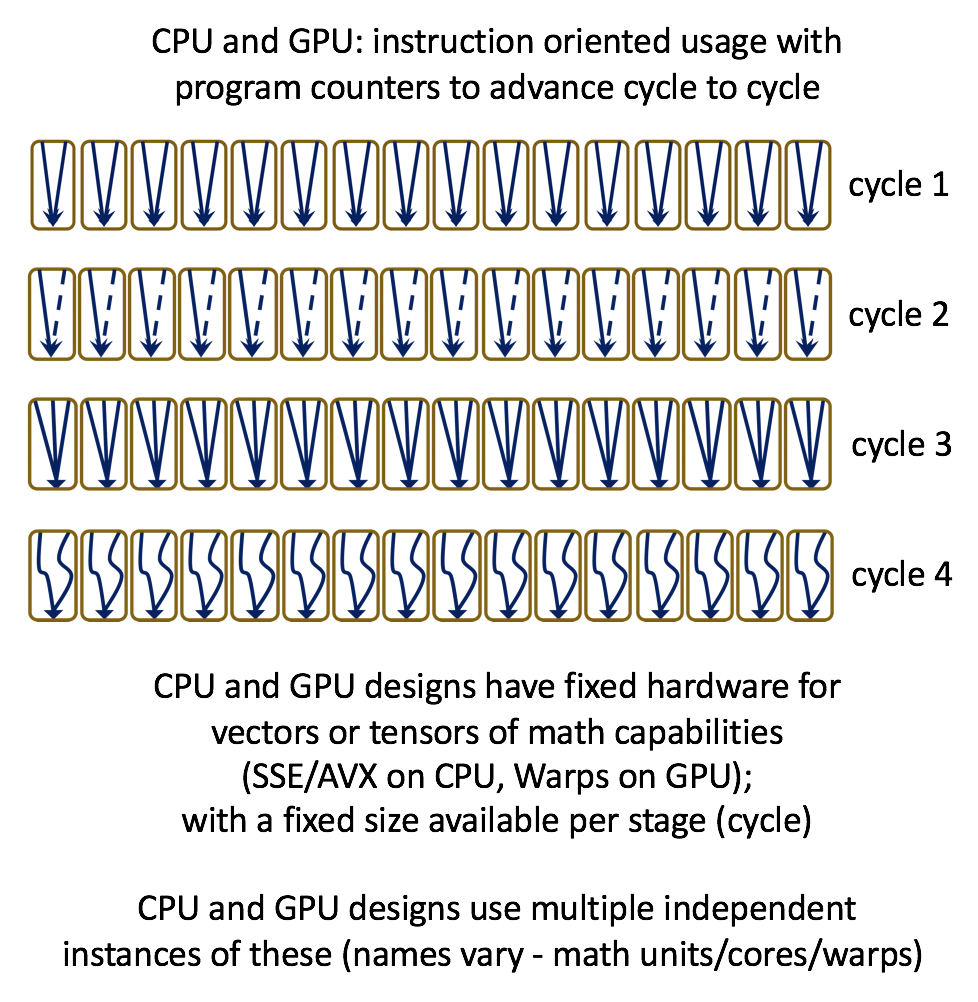
It has been said that FPGAs compute spatially not temporally and that this helps speed things along. They combine parallelism and concurrency in hardware, and their versatility, reconfigurability, parallelism, determinism, high performance and low latency have resulted in FPGAs being called the “Swiss army knife of semiconductors.” These advantages are very similar to the case for using ASIC designs, such as the Google TPU, but with the significant additional capability of reconfigurability. A simplistic view is that CPU and GPU designs are instruction oriented and have fixed amounts of hardware arranged in fixed ways and repeated (cores), whereas FPGAs lack the same notion of fixed instructions and have fixed amounts of hardware without fixed arrangement. The implications for flexibility and power efficiency are enormous, and can be difficult to grasp the first time one hears about it. This is illustrated in the conceptual drawings below.

Traditional concerns about FPGAs have been around programmability, in no small part because FPGAs previously catered only to hardware designers with hardware description languages, such as VHDL. Today’s newer tools, built around OpenCL, are more mature than you might expect given how recently they have appeared for FPGAs. The reason is that they are more like “OpenCL to VHDL” translators than they are stand-alone new compilers. Since VHDL to FPGA synthesis is very mature and robust after decades of refinement, the OpenCL compilers are actually quite effective. The result is that OpenCL can offer great performance with FPGAs.
One such example out of Boston university, showed OpenCL results beating hard coded IP-blocks for an FPGA, while beating GPUs 1.7X to 11X and CPUs 13X to 63X. Their most recent results were published as a paper titled “FPGA HPC using OpenCL: Case Study in 3D FFT” and presented in June at HEART 2018 (International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies). Results showing that FPGAs can be faster, with lower power and more consistent, helps explain why FSI companies show strong interest in FPGAs.
A startup in Portland, OR, Megh Computing, is focused on supporting real time analytics using FPGA-as-a-Service in the cloud. This approach delivers impressive performance and lower latencies by using both inline and offload processing with FPGA accelerators. P.K.Gupta, founder and CEO of Megh Computing, said, “We know there is enormous opportunity for cloud services providers to use FPGAs to offer solutions to customers for real time insights with new capabilities, including FSI as well as retail, comms, and other segments. Whether using an in-house cloud, or a public-cloud, FPGAs are already proving essential to FSI computational workloads.”
CUDA vs. OpenCL for Accelerators – It Doesn’t Matter Much
When one thinks of programming accelerators, there are two camps: CUDA for Nvidia and OpenCL for everything else. In the end, it matters little to the likes of FSI developers. That is because real deployment success happens through solutions, such as libraries, that accelerate key algorithms. Having a good answer to “how do I do a Monte Carlo (or other target FSI workload algorithm)?” is key, not the choice of programming language to implement the method.
Power – and Size – May Matter
The historical locations of FSI companies tends to make their data centers especially sensitive to space and power. The concept of using additional hardware in addition to CPUs to get the job done has become widely accepted, but the choice of accelerator is hotly contested. Comparing the latest Nvidia GPU accelerator with the latest Intel FPGA accelerator can be challenging and what matters is delivered performance for specific applications. Here are numbers drawn from Nvidia and Intel websites that compare an Nvidia Tesla V100 PCIe accelerator card (equipped with an Nvidia Volta GPU) with an Intel Programmable Acceleration Card (PAC) (equipped with Intel Arria 10 GX FPGA):
- Nvidia PCIe card 300 watts, 15.7 TFLOP/s SP, 7.8 TFLOP/s DP
- Intel PCIe card 66 watts, 1.52 TFLOP/s SP, 1.37 TFLOP/s DP
While the performance per watt may look similar, the Intel card only pulls power from the 12V line of the PCIe bus and within the PCIe specification of 5A maximum. There is not supplemental power brought into the card via other power connections. The card is also ½ height and ½ length (full length with optional air ducting) whereas the Tesla V100 is full height and full length. For FSI, this is often more of a factor for adoption than for many supercomputer centers.

½ height vs. full size PCIe cards
FSI companies with racks and racks of 1U servers may feel they are in a better position to add ½ height 66W PCIe accelerator cards than they are for reconfiguring a rack to accommodate 300W full height cards. Of course, the Nvidia GPU cards claim over 5X the DP performance and 10X the SP performance per card. Integer performance of the two solutions is harder to compare, partly because the FPGA is much more flexible about data sizes. As always, when it comes to comparing and validating different platforms, there’s no substitute for running your own workloads.
An example of how vendors are positioning the smaller form factor as a benefit to aid in the adoption of FPGAs by FSI was offered by Levyx at the Red Hat summit in May 2018. Levyx highlighted scaling with one or three FPGAs in a single server running on an Intel-built Rack-Scale Design (RSD).
Race to Zero Latency – Jitter Matters
Competition in HFT has been fierce, with market players investing in more powerful solutions that can trade in nanoseconds, hence the emergence of the “race to zero latency.” FPGA cards have been called “the final significant step in the evolution of low latency trading technology” and are in virtually every HFT solution.
Much like any supercomputer center, all major exchanges are boosting the performance of their network connections. Rapid delivery of the deluge of data is not enough, processing it quickly and on-time all the time is essential. Dramatic performance improvement for trading means controlling not only latency, but also jitter. FPGAs can offer deterministic latency, which means no jitter and predictable reaction times, even during heavy trading when timing may matter most and placing trades in a timely manner reduces risk exposure.
FPGAs have a deterministic nature because they are, ultimately, just circuits synthesized from a description via VHDL, OpenCL or using an FPGA library. There is no preemption from an operating system, print daemon, checkpointing software, keyboard interrupt, virus checker, etc. There is no branching in the software, or anything inherent in an FPGA that leads to non-determinism. Even though we program in OpenCL or HDL, FPGA applications become circuit designs when we compile (synthesize) our code. Circuits don’t jitter like programs do on CPU and GPU based systems, which has many benefits – including that it is common that the peak performance of a given design is the performance. In a not-so-subtle way, this gives FPGAs a performance advantage in real world applications.
Low jitter has high value for traders, which in turn makes it important for real time risk assessments, particularly those designed to place or prevent a trade.
Networking – “Inline Processing”
Microsoft Azure has been deploying FPGAs in all of its servers over the last several years using the Catapult architecture to do accelerated networking. This creates a configurable cloud that provides more efficient execution for many scenarios without the inflexibility of fixed-function ASICs at scale. Microsoft says its FPGA-based accelerated networking reduces inter-virtual machine latency by up to 10x while freeing processors for other tasks. Microsoft also uses FPGAs for Bing search ranking, deep neural network evaluation, and software defined networking acceleration. Mark Russinovich, CTO of Microsoft Azure, describes the company’s cloud FPGA architecture, application performance and possible uses in his talk “Inside Microsoft’s FPGA-Based Configurable Cloud.”
When networking is so tightly connected to compute capabilities, as is the case with Microsoft’s FPGA usages, it enables what I call “inline processing.” Think “dataflow” or “systolic computing” done at today’s speeds, protocols, and bandwidths with low latency, and you’ll understand the excitement around FPGAs.
FSI as an Enterprise
The financial services industry has all the same challenges as any enterprise, in addition to their FSI specific workloads. ETL (Extract, Transform and Load), data warehousing acceleration, and real time relational databases are all important in dealing with large amounts of high-velocity data. Solutions using FPGAs to tackle such data challenges are appearing from companies such as Swarm64 and Bigstream. The enterprise search capabilities highlighted by FPGA usage with Microsoft Bing can help FSI enterprises as well. Real time inferencing with FPGAs can fill roles for FSI-specific needs such as fraud detection and market surveillance, as well as enterprise level security such as cyber security. As the enterprise extends its embrace of accelerators such as FPGAs, FSI – facing a very real computational arms race – will not be left out of this trend.
James Reinders is an HPC enthusiast and author of eight books with more than 30 years of industry experience, including 27 years at Intel Corporation (retired June 2016).






