



Scaling the Cloud and High Availability: Two Perspectives, One Approach

source: Shutterstock
System administrators and database administrators have different perspectives on high availability (HA). The differences can cause problems ranging from consternation and conflict to wasted investments and excessive downtime.
While the differences are reconcilable, they are not trivial. For example, using Raw Device Mapping technology in VMware’s vSphere to create a high availability cluster makes it difficult or impossible to utilize features like vMotion and VM cloning that are popular with sys admins. SQL Server also has its own carrier-class HA provisions, but these usually require using the much more expensive Enterprise Edition that DB Admins find difficult to cost-justify for many applications.
This article explores how the different perspectives sys admins and DB admins have regarding high availability can find common ground in a single approach that spans private, public and hybrid cloud configurations.
Two Perspectives
At a high level, high availability seems simple. The HA provisions offered in the cloud should be configured by the sys admins to deliver minimal or no downtime to mission-critical database applications. To give DB admins adequate assurances, the uptime should be guaranteed in a service level agreement that specifies consequences (normally a discount) for unplanned downtime beyond a specified level of uptime, such as 99.99 percent.
But as with so many aspects of IT, the HA devil in is in the HA details where the competing objectives become apparent. Because sys admins are under pressure to keep costs under control, they might choose to not utilize all available HA provisions for all applications. By contrast, DB admins are under great pressure to keep their applications up and running 24x7 (even while data is backed up and software is updated) with imperceptible adverse impact on performance. Such highly-available high performance can consume considerable active and standby, physical and/or virtual server, storage and networking resources.
In addition to the technical and licensing issues involving VMware and SQL Server mentioned above, the three major cloud service providers—Google, Microsoft and Amazon—all have at least some HA-related limitations. Examples include failovers normally triggered by patching or zone outages and not many other common failures, master instances only being able to create a single failover replica, and the use of event logs to replicate data, which create a “replication lag” that results in temporary outages during a failover. Of course, none of these limitations is insurmountable — with a sufficiently large budget. The challenge, therefore, is to find one approach capable of working cost-effectively across public, private and hybrid clouds.
One Approach
Common ground is to be found in failover clustering software, a type of overlay network solution purpose-built to provide high-availability in hybrid clouds. Being implemented entirely in software, failover clustering solutions are normally versatile and extensible, offering a single HA solution for all applications. And that also enables them to satisfy both the sys admin’s need for a capable yet cost-saving solution, as well as the DB admin’s need for high availability with high performance.
Although most failover clustering software can use storage area networks, SANless configurations are generally preferred for their ability to eliminate potential single points of failure. As the designation implies, SANless failover clustering creates a shared-nothing cluster of servers and storage with automatic failover across the LAN and/or WAN to assure HA at the application level.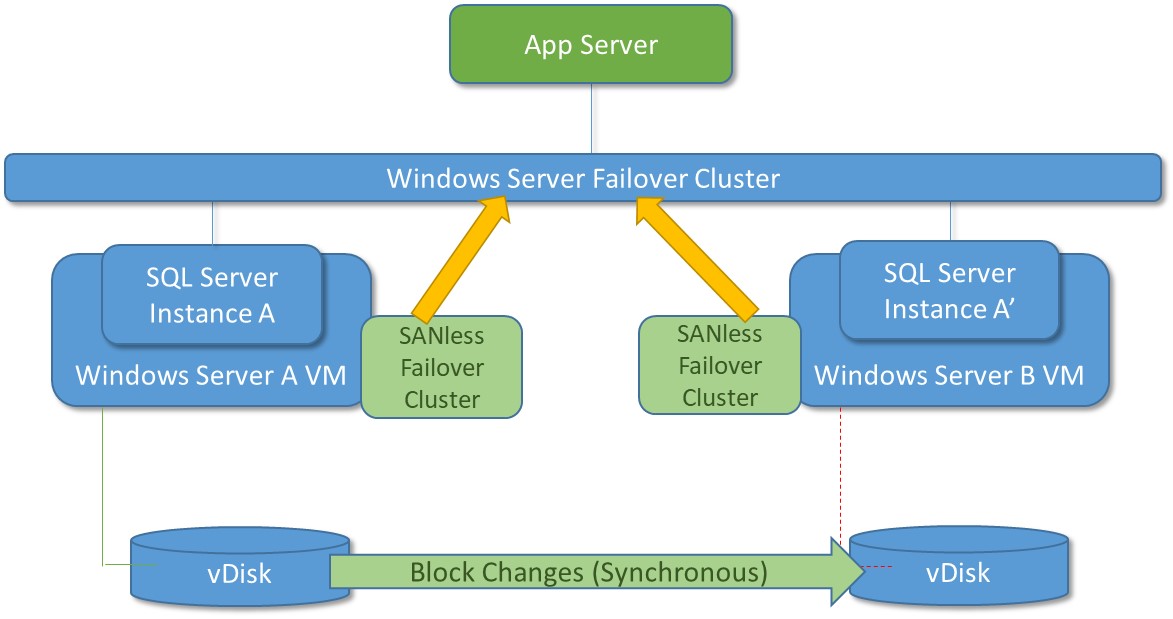 The configuration for a basic two-node SANless failover cluster showing data from SQL Server Instance A (on Windows Server A) being replicated synchronously to Windows Server B.
The configuration for a basic two-node SANless failover cluster showing data from SQL Server Instance A (on Windows Server A) being replicated synchronously to Windows Server B.
Most failover clustering software provides a HA solution that includes real-time block-level data replication, continuous application monitoring and configurable failover/failback recovery policies to protect business-critical applications.
More sophisticated failover clustering solutions also offer advanced capabilities, such as ease of configuration and operation, WAN optimization to maximize performance, support for planned maintenance with manual switchover of primary and secondary server assignments, a choice of synchronous or asynchronous replication, and the ability to perform regular backups without disruption to the application.
For database applications, support of the Always On Failover Cluster Instances (FCIs) available in the less expensive Standard Edition of SQL Server is often an important consideration. In a Windows environment, most failover clustering software supports FCIs by leveraging the Windows Server Failover Clustering capability built into the operating system, which makes the implementation quite straightforward for both DB and sys admins.
In a Linux environment, by contrast, sys admins are often reluctant to take on the task of implementing and maintaining HA provisions using open source software, such as Pacemaker and Corosync. The reason is: getting the full software stack to work as desired requires creating (and testing) custom scripts for each application, and then regularly retesting and sometimes updating these scripts after making even minor changes to the software or hardware used. With Linux becoming increasingly popular for SQL Server and many other enterprise applications, some failover clusters now make implementing HA for Linux just as easy as it is for Windows Server.
Zero Impediments
Security was initially the primary concern that made organizations reluctant to migrate applications from private to public clouds. Over time, public clouds have become more secure as private clouds became more efficient, making cost the primary impediment to migration today, particularly for mission-critical database applications. With failover clustering technology spanning both public and private clouds, there are no longer any major barriers to migrating and scaling all applications in whatever hybrid cloud arrangement affords the most capable and cost-effective solution.
Dave Bermingham is Microsoft Cloud and datacenter management MVP at SIOS Technology; David Klee is founder and chief architect at Heraflux Technologies.






