



MLPerf Inference 3.0 Highlights – Nvidia, Intel, Qualcomm and…ChatGPT

MLCommons today released the latest MLPerf Inferencing (v3.0) results for the datacenter and edge. While Nvidia continues to dominate the results – topping all performance categories – other companies are joining the MLPerf constellation with impressive performances. There were 25 submitting organizations, up from 21 last fall and 19 last spring. Intel showcased early Sapphire Rapids-based systems, and Qualcomm’s Cloud AI 100 was a strong performer, particularly in power metrics. Newcomer participants included CTuning, Quanta Cloud Technology, SiMa and xFusion.
Also noteworthy was the discussion around generative AI – yes, more chatter about ChatGPT writ large – during a press/analyst pre-briefing this week. How should MLPerf venture into the generative AI waters? Is BERT Large a good proxy for LLMs? MLCommons executive director David Kanter said a large language model (LLM) will be added to the MLPerf benchmarking suite soon.
Currently, BERT (bidirectional encoder representations from transformers) is the NLP model used by MLPerf. The expected proliferation of generative AI applications – think targeted versions of ChatGPT and DALL·E 2 – will likely produce a demand spike for inferencing infrastructure. Interestingly, there was some consensus that BERT can serve as an early proxy of larger LLMs even though it’s much smaller in scale (GPT3 has 175 billion parameters, BERT large has on the order of 300 million).
 Intel’s Jordan Plawner, senior director, AI products, echoing others, said, “In our early results of testing these much larger models, much larger than large BERT, [the approach is similar to BERT]. I think the other way to think about it is that these large models like GPT3 and GPT4 are going to float all boats in that they’re going to generate hundreds if not thousands of smaller models that are distilled down from these very large models. I think anyone who’s running BERT Large as a training model, inference model, [can use it] at least as a proxy for running these smaller GPT models as well.”
Intel’s Jordan Plawner, senior director, AI products, echoing others, said, “In our early results of testing these much larger models, much larger than large BERT, [the approach is similar to BERT]. I think the other way to think about it is that these large models like GPT3 and GPT4 are going to float all boats in that they’re going to generate hundreds if not thousands of smaller models that are distilled down from these very large models. I think anyone who’s running BERT Large as a training model, inference model, [can use it] at least as a proxy for running these smaller GPT models as well.”- Karl Freund, founder and principal analyst, Cambrian AI Research, added, “Just to elaborate a little. Talking with Andrew Feldman (founder/CEO Cerebras) a couple of weeks ago, and he said, something that struck in my mind. He said, ‘you know AI has been interesting from a revenue standpoint, it’s primarily been impactful to the hardware vendors. Now, suddenly, there’s a massive pile of money on the table, we’re talking Google and Microsoft, and AWS and everybody else whose business is going to be impacted positively or negatively.’ I think MLCommons can play a strong role here in helping the industry understand which hardware can deliver what economics in providing inference processing for very large language models.”
(More coverage of the LLM discussion is deeper in the article)
All in all, the latest MLPerf showing was impressive, with roughly 6,700 inference performance results and 2,400 power efficiency measurements reported. The submitters include Alibaba, ASUSTeK, Azure, cTuning, Deci.ai, Dell, Gigabyte, H3C, HPE, Inspur, Intel, Krai, Lenovo, Moffett, Nettrix, NEUCHIPS, Neural Magic, Nvidia, Qualcomm Technologies, Inc., Quanta Cloud Technology, Rebellions, SiMa, Supermicro, VMware, and xFusion, with nearly half of the submitters also measuring power efficiency.
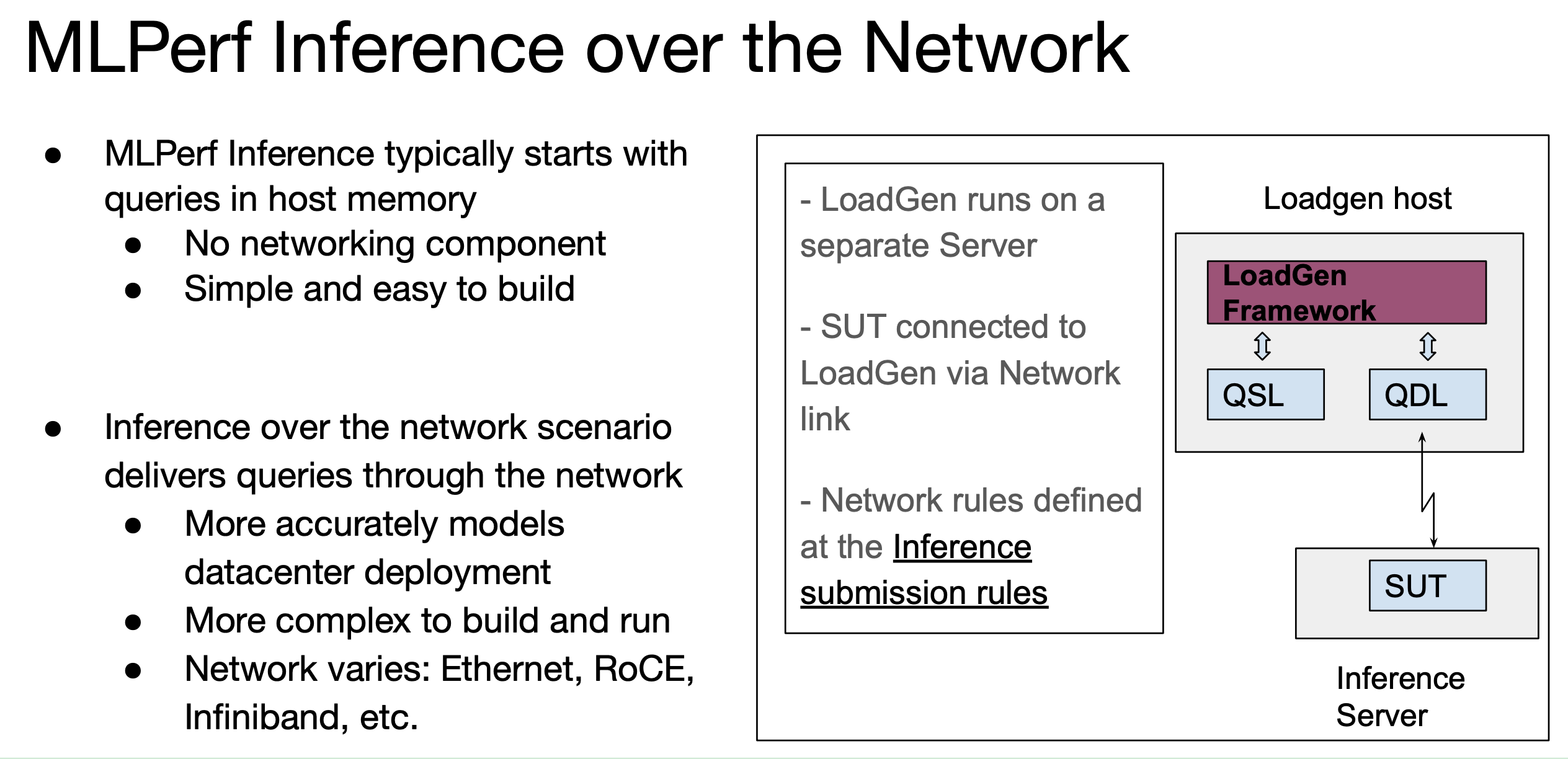
Inferencing, while generally not as computationally intensive as training, is a critical element in AI delivery. There were no changes to the suite of tests in MLPerf Inference 3.0 but a new scenario – networking – was added. See the slides below for a visual summary.
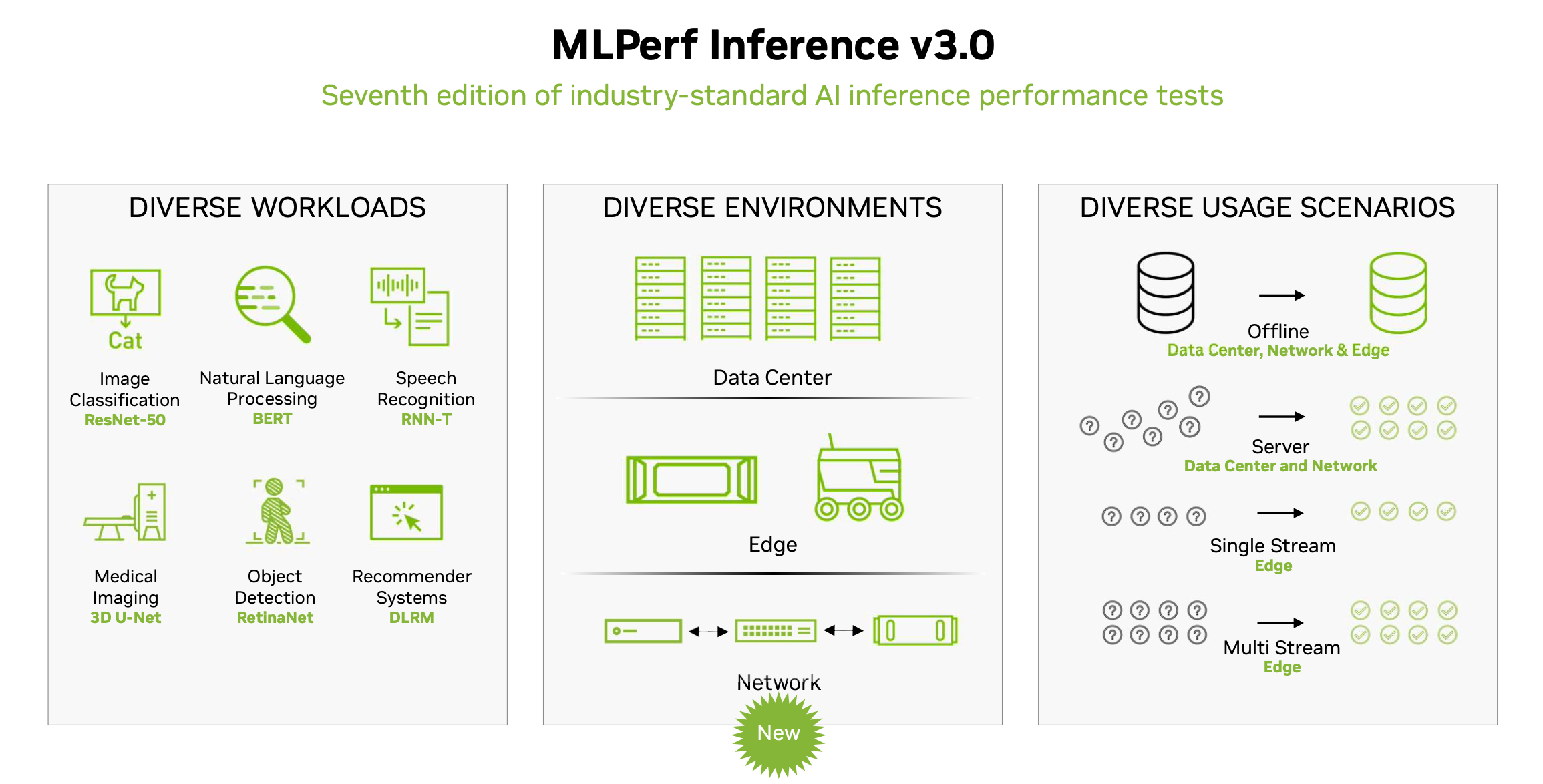

“We want our benchmarks to be used to compare solutions to help people buy as well as make design choices, [to] figure out if a given technique is actually worth pursuing. The reality is the best benchmark is always the workload you run. But you may not be able to share that workload, and it may be specific only to you. And in reality, most folks using ML are using a variety of different workloads. So, the goal of MLPerf, is we want, you know, repeatable, we want it representative, fair and useful,” said Kanter.
As always, making sense of MLPerf results has grown more complicated as the diversity of submitters and system sizes and system configurations has grown. But that’s sort of the goal in the sense that MLPerf’s extensive benchmark suites and divisions (closed, open, etc.) permit more granular comparisons for system evaluators but it takes some effort. Fortunately, MLCommons, parent organization for MLPerf, has made it fairly easy to slice and dice results. MLPerf has been gaining traction as a systems comparison tool, though that’s been coupled with a desire to see more non-Nvidia accelerators participate.
Here are comments from two analysts:
- Peter Rutten, VP infrastructure systems, IDC, said, “[MLPerf 3.0] is especially helpful because of the huge differences between all the systems in terms of performance and power consumption [and] the software that each system deploys to optimize the performance. Having the ability to compare all these systems in an objective way that is supported by most of the AI industry is allowing us to see how vendors compare. We still need to be careful interpreting the results. For example, comparing the performance of a high-end GPU with a CPU can be misleading. Obviously that GPU is going to shine, but the GPU is a co-processor that you add to your system at significant cost from an acquisition, power consumption, and heat dissipation perspective, whereas the CPU is the host processor that is part of the system to start with.”
- Freund, noted, “Once again, Nvidia leads the pack; they keep increasing performance through software. But there were some interesting developments. Deci optimized models to run faster on A100 than H100; quite a feat. They did it by applying AI to optimize AI Models. Qualcomm wins in power efficiency in the Edge Data Center, while newcomer SiMa.ai demonstrated better efficiency than Nvidia Jetson. Not bad for a first timer!”
(Per its usual practice, MLCommons invites participants to submit short statements describing the systems used and their salient AI-enabling features. Those statements are included at the end of this article.)
Nvidia Still Shines Brightly
Nvidia remains dominant in the broad accelerator market and showcased the performances of its new H100 GPU as well the just-launched L4 (the replacement for the T4).
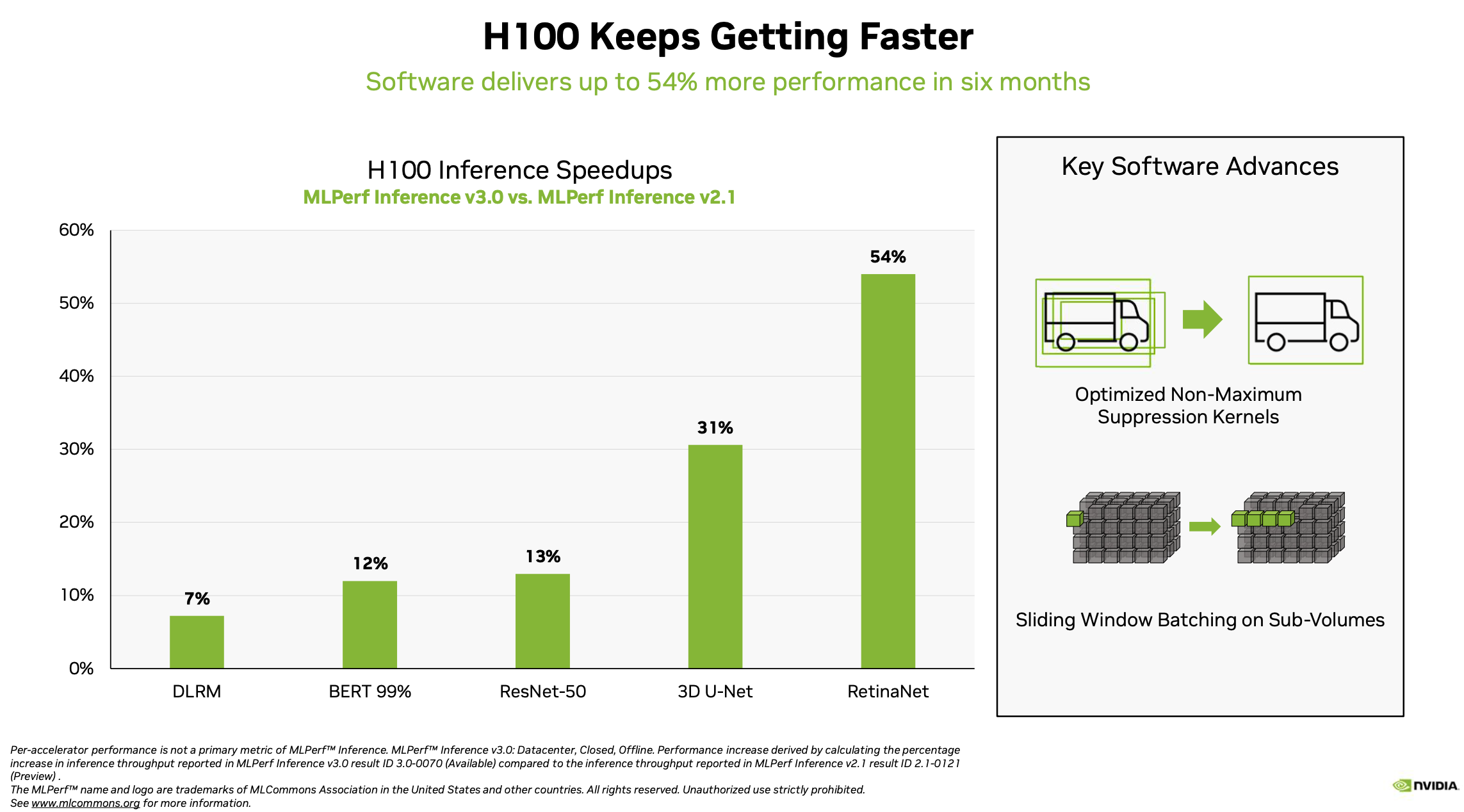
David Salvator, Nvidia director of AI, benchmarking, and cloud, provided a good top line summary, “We’ve seen some phenomenal performance gains in just six months up to 54% versus our first submissions just six months ago. That’s a testament to our ongoing work around software innovation. Typically, in any given generation of products that we build over the course of that product lifecycle, we’ll get about another 2x performance from software optimizations and continual tuning of our libraries, our drivers.
“Our L4 product, which we just launched at GTC, is making its first appearance in MLPerf, delivering results up over 3x versus our previous generation product. The third point of interest is our Jetson Orin platform also made great strides. This is not its first appearance in MLPerf, but through a combination of software and some power tuning at the platform level, we’ve been able to increase both performance and efficiency by up to 57% in the case of efficiency,” he said.
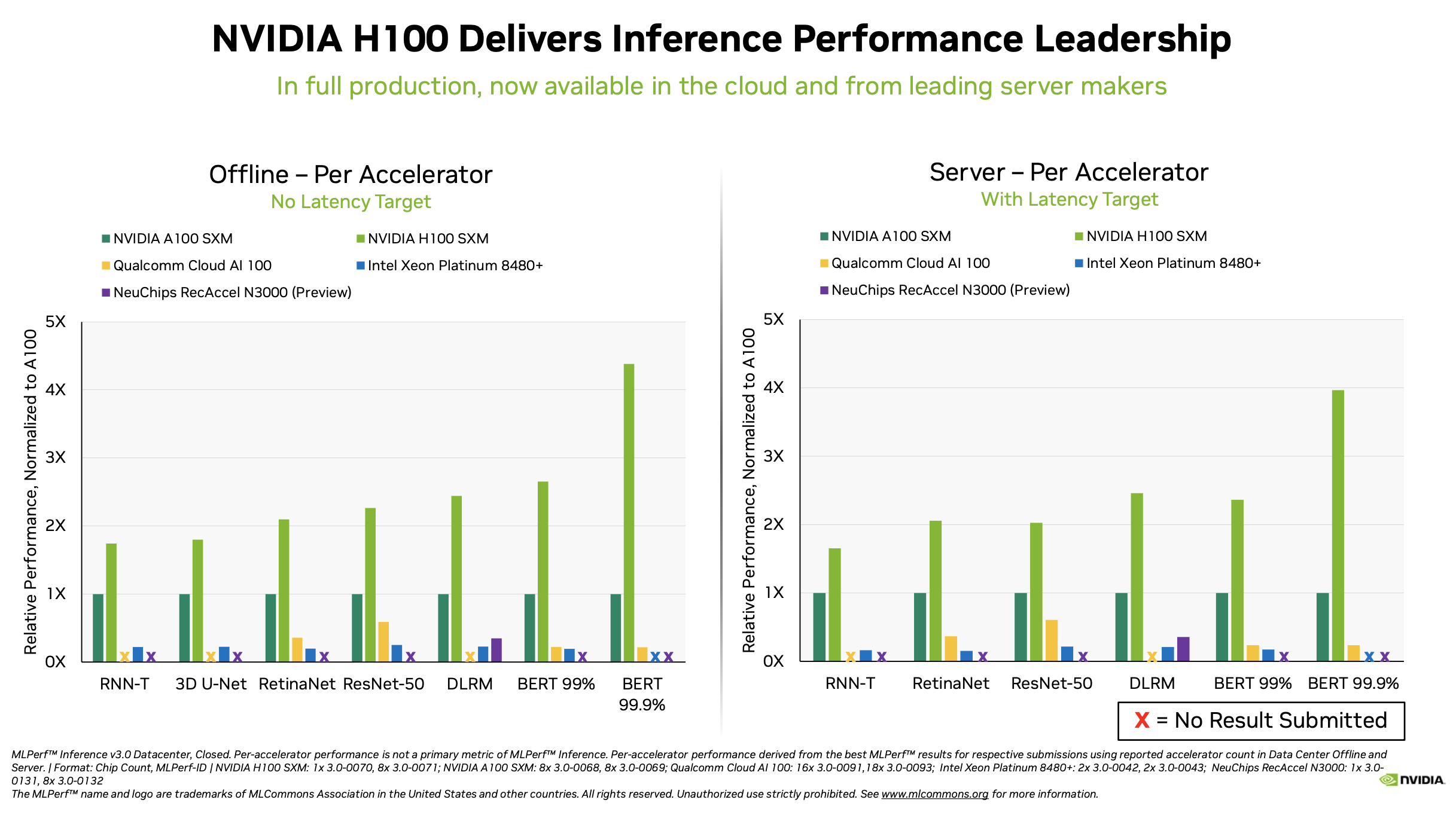
Salvator credited software improvement and the H100 Transformer Engine (library for using mixed precision formats). He also cited the use of non-maximum kernels for object detection inferencing. As shown in the slide below, bounded boxes are generally used to help identify objects. “Often those bounding boxes are done in a way that overlaps for the sake of being thorough, however [as shown] on the right-hand side of the slide (below) that’s overkill. What happens with NMS kernels, by optimizing those kernels, we were able to see some of the nice performance pickups in both 3D U-Net as well as ResNet-50,” he said.
Intel Sapphire Rapids Rises
In the last MLPerf Inference exercise, Intel submitted in the preview category, which is for products expected within six months. This round, Intel submitted in closed datacenter on one-node systems (1-node-2S-SPR-PyTorch-INT8) with two CPUs (Intel Xeon Platinum 8480+). There’s been a lot of discussion in the last couple of years around the notion that general purpose CPUs may be sufficient in some inferencing workloads, typically where inferencing is an occasional need and not the dedicated or dominant need.
The latest Intel submission, while not keeping pace with accelerator-based systems, was able to run workloads and showed improvement over the last MLPerf.
“With the fourth-generation Xeon scalable processor, previously codenamed Sapphire Rapids, we actually have a new accelerator in our product called AMX (advanced matrix instructions). The last submission was really us just getting Amex enabled. So, to build upon Nvidia’s point (about achieving performance improvement through software), now we’re actually tuning it and improving the software,” said Plawner.
 “We’re seeing across the board performance improvement on all models between 1.2x and 1.4x in just a matter of a few months. [We’ve] gone from just enabling AMX, which again is kind of new accelerator for us within the CPU cores, to getting a chance to tune the software. Similar to previous comments, we expect probably to get up to around 2x within the current generation, just by software, improvements alone. We all love Moore’s law at Intel but the only thing better than Moore’s law is actually what software can give you over time within the same silicon,” he said.
“We’re seeing across the board performance improvement on all models between 1.2x and 1.4x in just a matter of a few months. [We’ve] gone from just enabling AMX, which again is kind of new accelerator for us within the CPU cores, to getting a chance to tune the software. Similar to previous comments, we expect probably to get up to around 2x within the current generation, just by software, improvements alone. We all love Moore’s law at Intel but the only thing better than Moore’s law is actually what software can give you over time within the same silicon,” he said.
It’s worth mentioning here that competing vendors stuck to MLPerf’s rules that comments at its overall media/analyst briefing could not directly compare one product against a rival product. This was refreshing and useful. As mentioned earlier, it really is necessary to dig into the results data and compare like/similar systems (hardware, software, and no networking for new networking test) to like systems.
Many vendors are also publishing blogs touts their result and making competitive comparisons.
Qualcomm Shows Steady Gains
Qualcomm is no stranger to the MLPerf exercise and its Cloud AI 100 accelerator has consistently been a top performer, demonstrating low latency and excellent power efficiency. The company reported that its MLPerf v3.0 inference results surpassed all of its previous records of peak offline performance, power efficiency, and lower latencies in all categories.
“The 2U datacenter server platform with 18x Qualcomm Cloud AI 100 Pro (75W TDP) accelerators achieved the ResNet-50 offline peak performance of 430K+ inference per second and achieved power efficiency of 241 inference/second/watt. The Qualcomm Cloud AI 100 RetinaNet Network offline performance across all platforms has been optimized by ~40-80% and server performance by up to 110%,” reported Qualcomm.
“Since its first MLPerf 1.0 submission, Qualcomm Cloud AI 100 performance has been improved by up to 86% and power efficiency has been improved by up to 52%. The improvements have been achieved via software optimizations like improvements in AI Compiler, DCVS algorithms and memory usage. This highlights the continuous efforts and investment over the last few years,” according to the company.

VMware showcased its performance virtualizing an Nvidia Hopper system in collaboration with Dell and Nvidia. “We achieved 94% of 205% of bare metal performance. And the notable thing was that out of 128 logical CPU cores, we only used 16 CPU cores. All remaining 112 CPU code should be available in your datacenters for other workloads without impacting the performance of machines running your inference workloads. That is the power of virtualization,” said Uday Kurkure, staff engineer, VMware. A few results charts are shown in VMware’s supplement statement at the end of the article.
Unfortunately, there’s too much vendor-specific material to cover in a relatively short article. Perusing vendor statements at the end of the article can provide a flavor for many of the submissions.
What Flavor of LLM/GPT Best Fits MLPerf?
Lastly, the discussion at the analyst/media briefing around generative AI and large language models was interesting in that it seemed to be on everyone’s mind. In response to a question, Kanter noted that BERT was closest to GPT3/4 but the thought that scaling needed to implement LLMs would likely make BERT a relatively poor proxy, and as noted earlier, he said MLCommons plans to add an LLM soon.
“The computational aspects of ChatGPT will be most similar to BERT, however, it is dramatically larger. It may be that just because something does great on BERT does not necessarily guarantee that you can use that same system on ChatGPT. You’re going to need a lot more memory, or potentially very clever ways to handle memory. When you dive into the details of the model, there’s a lot of things that might be different,” said Kanter.
What was interesting was the submitters didn’t really agree; many thought BERT was actually a good first step.
“To your point, certainly the number of layers scales up, the parameters scale up, the sequence length scales up. But from an architecture perspective, you know, the matrix multiplications, the layer normalization, this base structure [is similar] and BERT Large, which is a transformer for most purposes, can be scaled up for GPT3. Three. Now it’s starting to iterate and change a bit, but I think – and I’m sure no one will have any objections to this – I think all the submitters who have done optimizations for BERT Large, these similar optimizations will transfer towards LLM workloads. It’s a matter of scale [and] managing everything else,” said Michael Goin of Neural Magic.
Plawner of Intel and Salvator of Nvidia broadly concurred.
Salvator said, “I agree with those comments. Because it is a transformer-based model, it [BERT Large] is a decent proxy for things like GPT. I think the interesting thing – and maybe David [Kanter] can speak to this from a [MLPerf] roadmap perspective – that has to be taken into account for things like GPT and ChatGPT and other services being built upon it, is the elements that are real time services. It’s not just a question of throughput. It’s also a question of being able to turn the answer around very, very quickly, whether that’s a combination of just scale or also [with] things like auto batching. That’s something, for instance, that we do with our Triton inference serving software, where you set a latency budget and then you’re able at least to automatically send a batch size that’s as big as possible within that latency budget. So you’re able to get best throughput while maintaining it. Basically, think of it as an SLA.”
Kanter pointed out latency “is an intrinsic part” of the MLPerf benchmark definition for the server mode and something MLCommons can work on.
It’s pretty clear an LLM of some sort will soon join the MLPerf benchmarking lineup. Stay tuned.
Link to MLPerf spreadsheet: https://mlcommons.org/en/inference-datacenter-30/
Link to Nvidia blog: https://developer.nvidia.com/blog/setting-new-records-in-mlperf-inference-v3-0-with-full-stack-optimizations-for-ai/
Link to Qualcomm blog: https://www.qualcomm.com/news/onq/2023/04/qualcomm-cloud-ai-100-continues-to-lead-in-power-efficiency-with-mlperf-v3-results
Feature image: Nvidia HGX H100






