



AI Trifecta – MLPerf Issues Latest HPC, Training, and Tiny Benchmarks

MLCommons yesterday issued its latest round of MLPerf benchmarks – for Training, HPC, and Tiny. Releasing three sets of benchmarks at the same time makes parsing the results, never an easy chore, even more so. Top line: Nvidia accelerators again dominated Training and HPC (didn’t submit in the Tiny category) but Habana’s Gaudi2 performed well in Training, and Intel’s forthcoming Sapphire Rapids CPU demonstrated that CPU-based training, though not blindingly fast, can also work well.
More broadly, while the number of submissions across the three different benchmark suites was impressive, the number of non-Nvidia accelerators used in the Training and HPC exercises remained low. In this round (Training and HPC) there was only one pure-play competitive accelerator. There were more (3) competitive offerings in the last round. It’s not clear what exactly this means.
![]() Here’s a snapshot of today’s announcement with links to each set of results:
Here’s a snapshot of today’s announcement with links to each set of results:
- MLPerf Training v2.1 benchmark, targeting machine learning models that are used in commercial applications,included nearly 200 results from 18 different submitters spanning small workstations to large-scale data center systems with thousands of processors. (Link to Training results)
- MLPerf HPC v2.0 benchmark, targeting supercomputers, included “over 20 results from 5 organizations” including submissions from some of the world’s largest supercomputers. (Link to HPC results)
- The MLPerf Tiny v1.0 benchmark, is intended for lowest power devices and small form factors and measures inference performance - how quickly a trained neural network can process new data and includes an optional energy measurement component. It had submissions from 8 different organizations including 59 performance results with 39 energy measurements. This was a new record for Tiny. (Link to Tiny results)
During an Nvidia pre-briefing, David Salvator, director of AI, benchmarking and cloud, was asked by analyst Karl Freund of Cambrian AI Research, “Given the dearth of competitive submissions, are you concerned about the long-term bias viability of MLPerf?”
Salvator responded, “That's a fair question. We are doing everything we can to encourage participation. It is our hope that as some of the new solutions continue to come to market from others, that they will want to show off the benefits of those solutions on an industry standard benchmark, as opposed to doing their own.”
At the broader MLPerf pre-briefing, MLCommons executive director David Kanter answered essentially the same question, “The first thing I would say, from an MLPerf standpoint, is I think that all submissions are interesting, regardless of what type of hardware or software is used. We have new submissions using new processors (Intel/Habana).” He also emphasized it’s not just hardware that’s being tested; there are many different software elements being tested which have a dramatic effect on performance. The latter is certainly true.
How important the lack of alternative accelerators is remains an open question and perhaps a sensitive point for MLCommons. There is a definite sense that systems buyers are asking systems vendors for MLPerf performance results, official or otherwise, to help guide their procurement decisions. For distinguishing between system vendors and various configurations intended for AI-related tasks, MLPerf is proving significantly useful.
That said Habana’s Gaudi2 was the only other “accelerator” used in submissions this round (Training and HPC). Intel’s forthcoming Sapphire Rapids CPU was its own accelerator, and leveraged Sapphire Rapids’ internal matrix multiply engine. Intel was quick to point out it wasn’t aiming to outrace dedicated AI servers here, but to demonstrate viability for those with many workloads and intermittent AI needs.

Intel's Sapphire Rapids
Jordan Plawner, senior director, AI product manager, Intel, said simply, “We have proven that on a standard two-socket system, [with] Intel Xeon scalable processors server, you can train – in this case three different deep learning workloads. And we are training much more now. Our cluster was only up a few weeks before the MLPerf submission, but we're training a dozen right now, and we'll submit even more for next time. This just says it can be done.”
For the moment, MLPerf remains largely a showcase for Nvidia GPUs and systems vendors’ ingenuity in using them for AI tasks. MLCommons has made digging into the results posted on its website relatively easy. Given three very different sets of benchmark results were issued today, it’s best to dig directly into the spreadsheet of interest. MLCommons also invites participating organizations to submit statements describing AI-relevant features of their systems – they range from mostly promotional to instructive. (Link to statements at end of article)
Presented are brief highlights from the MLPerf Training. We’ll have coverage of the HPC results soon in a subsequent article. To get the most out the MLPerf exercise it’s best to dig into the spreadsheet and carefully compare systems and their configuration (CPUs, number of accelerators, interconnects) across workloads of interest.
It’s (Mostly) the Nvidia Showcase Again
Training is generally considered the most compute-intensive of AI tasks and Nvidia’s A100-based system have dominated performance in MLPerf Training since the A100 introduction in 2020. For the latest round, Nvidia submitted systems using its new H100 GPU, introduced in the spring, but in the preview category (parts commercially available in six months) rather than the available now category. A100-based systems from a diverse array of vendors were in the available division (link to MLPerf Training rules).


In a blog today Nvidia is claiming a sweep of top performances by A100 in the closed division (apples-to-apples systems) and also touting the H100’s performance. In a press/analyst briefing, Salvator worked to shine a spotlight on both GPUs without diminishing either.
“H100 is delivering up to 6.7x. more performance than A100 and the way we're baselining is comparing it to the A100 submission that was made a couple of years ago. We're expressing it this way because the A100 has seen a 2.5x gain in just software optimizations alone over the last couple of years. This is the first time we're submitting H100. It will not be the last [time]. Over the next couple of years, I can't tell you absolutely that we're going to get 2.5x more performance on top of what we've gotten with Hopper now, but I can tell you, we will get more performance,” said Salvator.

The H100’s ability to perform mixed precision calculations using what Nvidia calls its transformer technology engine is a driver of H100 advantage over the A100.
“Transformer engine technology [works] layer by layer. We analyze each layer and ask, can we accurately run this layer using FP8? If the answer is yes, we use a FP8. If the answer is no, we use a higher-precision like mixed-precision, where we do our calculations using FP16 precision, and we accumulate those results using FP32 to preserve accuracy. This is key with MLPerf performance [whose] tests are about time-to-solution. What that means is you not only have to run fast, but you have to converge [on an accurate model]. The point is the transformer engine technology works well for transformer-based networks like BERT, and there's a lot of other transformer-based networks out [there].”
He cited NLP and Stable Diffusion (image generation from text) as examples that could benefit from Nvidia’s transformer engine technology.
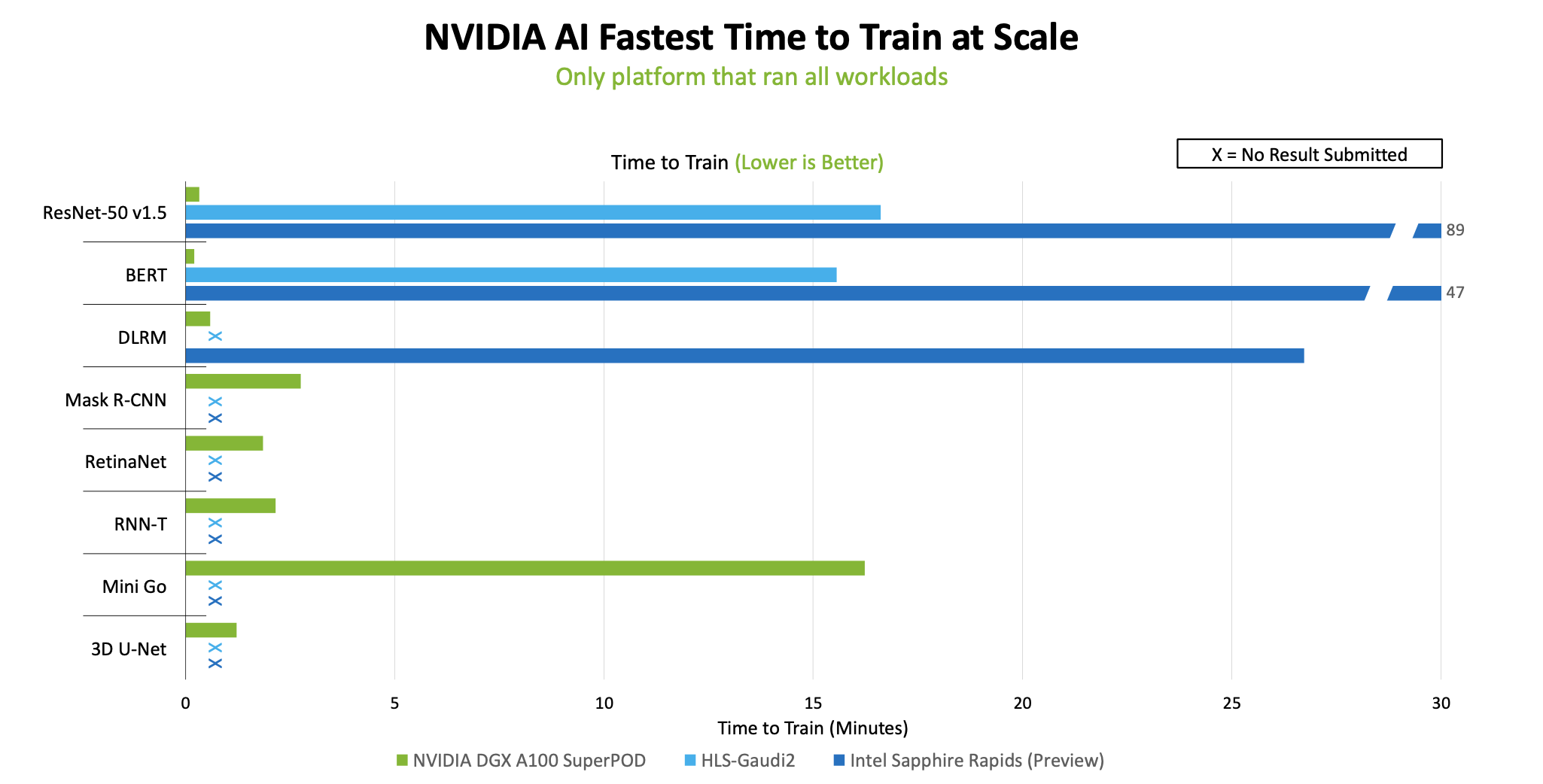

Gaudi2 and Sapphire Rapids Join the Chase
The only other pure-play accelerator was the Gaudi2 from Habana Labs, owned by Intel, which like the H100 was introduced in the spring. Intel/Habana was able to run Gaudi2-based systems shortly after its launch and in time for the MLPerf Training results released in June. It was a great show of out-of-the-box readiness if not full optimization and the Guadi2-based systems performed well. It posted the best time against the A100 on ResNet-Training.
At the time Habana blogged, “Compared to our first-generation Gaudi, Gaudi2 achieves 3x speed-up in Training throughput for ResNet-50 and 4.7x for BERT. These advances can be attributed to the transition to the 7nm process from 16nm, tripling the number of Tensor Processor Cores, increasing our GEMM engine compute capacity, tripling the in-package high bandwidth memory capacity and increasing its bandwidth, and doubling the SRAM size. For vision models, Gaudi2 has another new feature, an integrated media engine, which operates independently and can handle the entire pre-processing pipe for compressed imaging, including data augmentation required for AI training.”
Since then, Habana has been optimizing the software and Gaudi2’s performance in the latest MLPerf training round demonstrated that improvement as shown in the slide below.
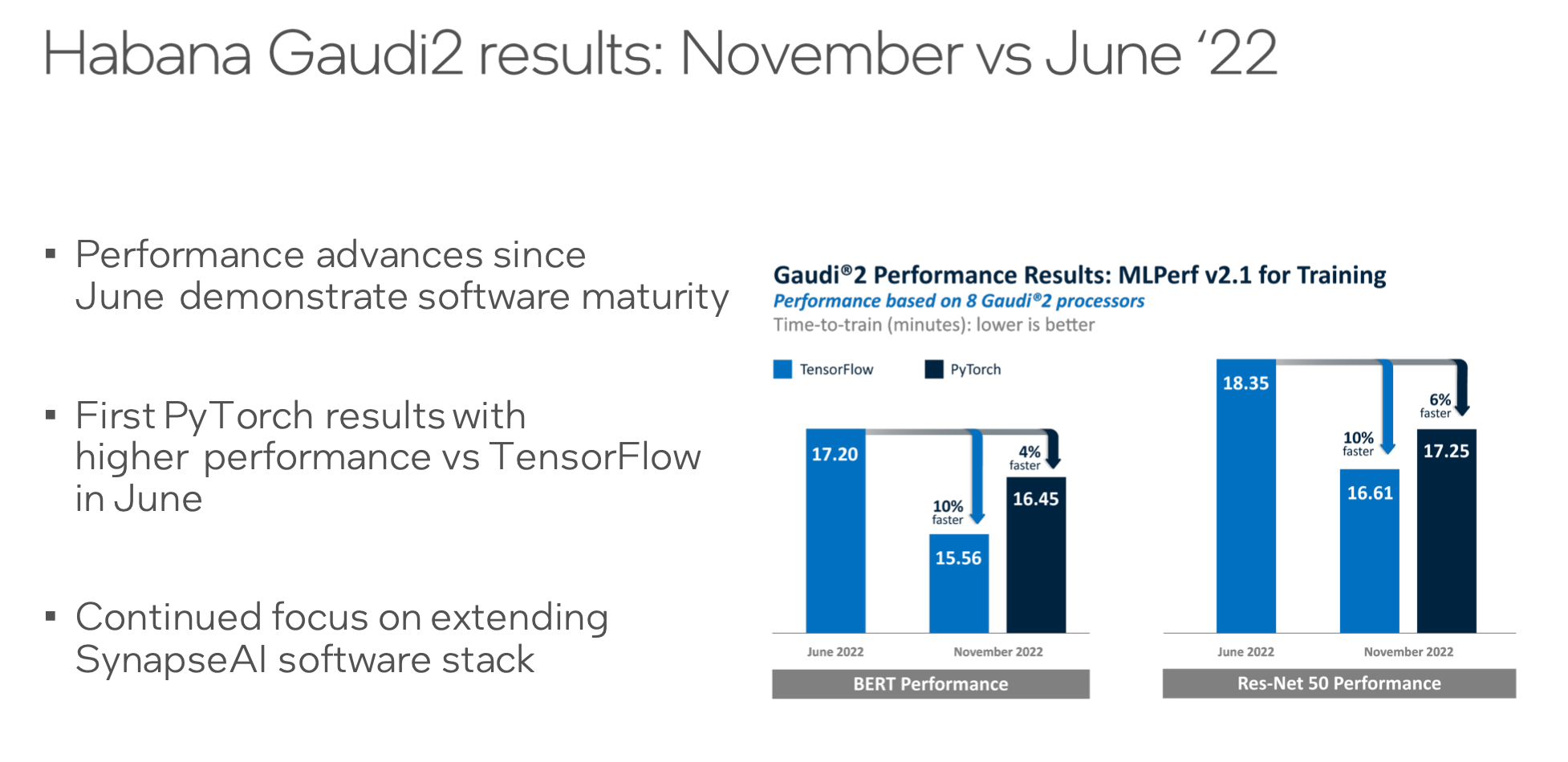
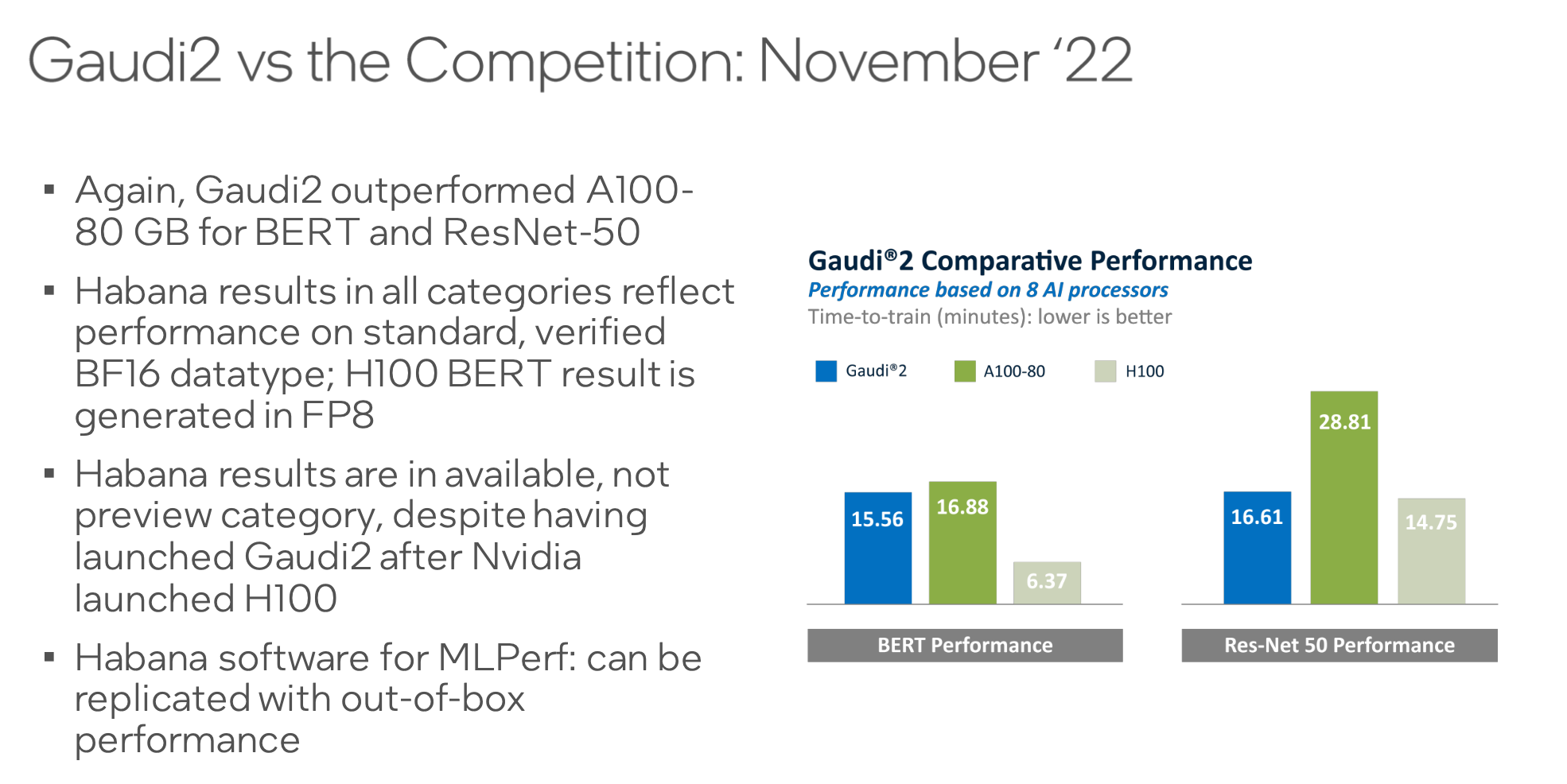
Habana reported that when comparing systems with the same number of accelerators – in this case 8 GPUs or 8 Gaudi2s – Gaudi2 again outperformed the A100, but not the H100. Habana COO Eitan Medina was not impressed with the H100 and took a jab at Nvidia in a pre-briefing with HPCwire.
“When we looked at them (H100), they actually took advantage of FP8 in the submission. We submitted still using FP16 even though we do have FP8 that the team is working to enable that in the next several months. So there's significant, you know, potential for improvement for us,” said Medina.
“What's jumping out, at least for me, is the fact that H100 is has not really improved as much as we expected, at least based on what was provided. If you review Nvidia documentation on what they expect the acceleration versus A00, it was actually much a larger factor than what was actually shown here. We don't know why. We can only speculate but I would have expected that if they said that GPT-3 would be accelerated by a factor of 6x over A100, how come it's only a factor of 2.6x,” he said.
One has the sense that this is just an early round in a marketing battle. Nvidia today dominates the market.
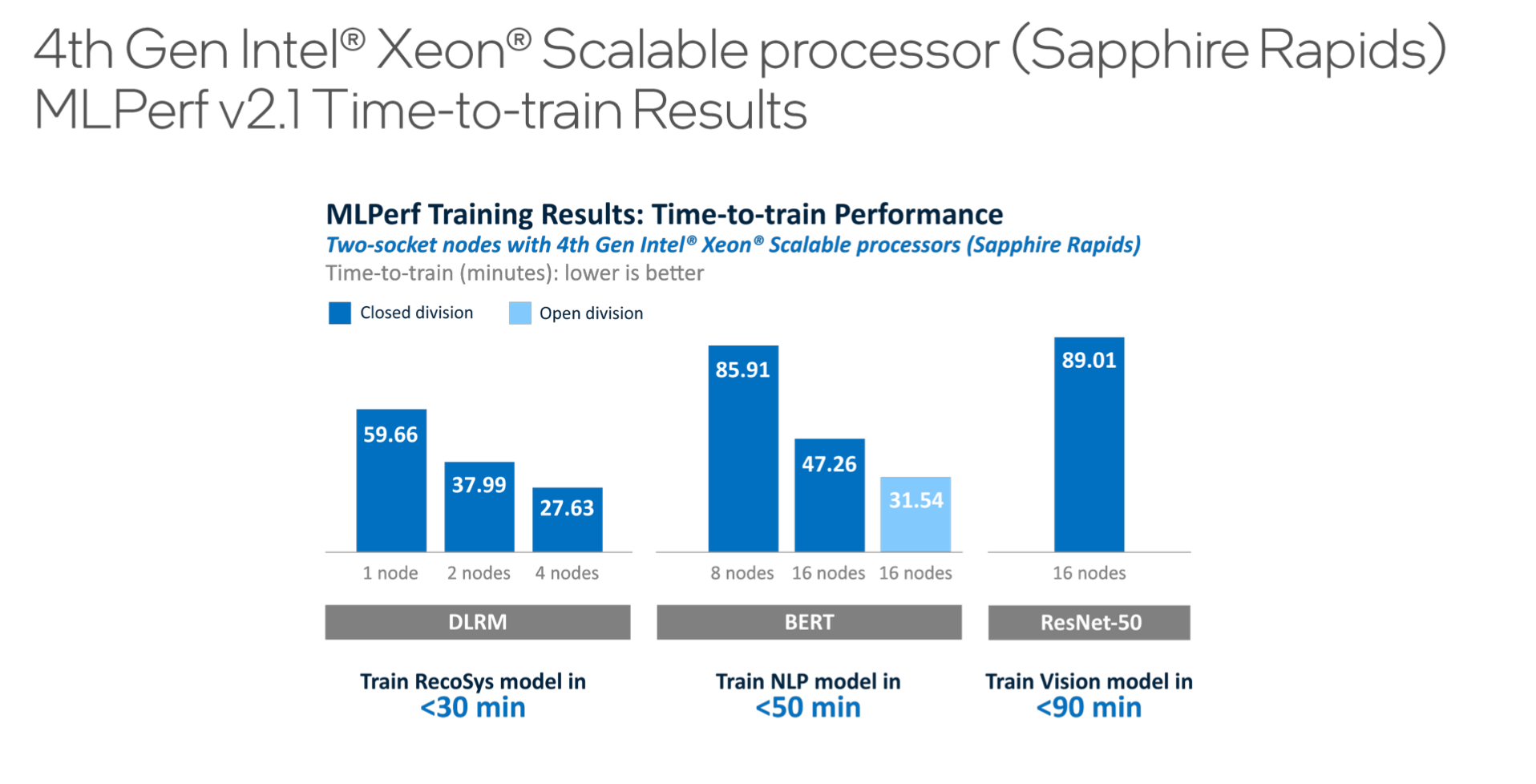
Lastly, there’s Intel’s Sapphire Rapids-based submission in the preview category. Leaving aside Sapphire Rapids’ much-watched trip to market, Intel was able to demonstrate, as Plawner said, that a two-socket system using Sapphire Rapids is able to effectively perform training.
Asked what makes Sapphire Rapids a good AI platform, Plawner said, “For any training accelerator/CPU, you need a balanced platform. So one of the areas where we've been imbalanced is we haven't had the compute power. Advanced matrix instructions, AMX, is kind of an ISA. You can almost think of it like a coprocessor that sits on every CPU core, that's invoked through an instruction set, and the functions are offloaded to that block within the CPU core. That's giving us – we've already talked about this architecture day, it’s at the operator level, sort of the lowest level of the model – an 8x speedup.
“But models are not all GEMs and operators, right. In practice, it's a 3-to-6x speed-up, because you have some models that are memory-IO bound and some that are more compute bound. You get closer to 8x with the compute-bound ones. You get closer to 3-or-4x with memory-bound ones. The other parts of the balanced platform are going to be PCIe Gen 5and DDR memory, because then that's what feeds the models and that's what feeds the compute engine. When we talk about Sapphire Rapids being a great platform for AI - it's really a balanced platform, it's advanced matrix instructions, PCIe Gen 5, and DDR and our cache hierarchy that all come together for this solution,” he said.
Intel’s ambition here, is not to build a dedicated Xeon-alone-based AI platform. (We’ll have to wait and see if Intel builds Sapphire Rapids-based system with multiple Intel GPUs for dedicated AI workloads).
Said Plawner, “While we can speed up training by just continually adding more nodes, we don't think it's practical to tell users to use 50 or 100 nodes. The point is to show people that on a reasonable number of nodes – reasonable being what you can get out of a cluster in your datacenter, what you can get from a CSP, what you might already have as a part of an HPC job-sharing cluster – and that if you don't need a dedicated all-day, year-round training for deep learning specifically, then you can just simply do your training on Xeon. The TCO here is that's TCO for all the workloads across the whole datacenter.”
He noted that Intel is looking at many training technology improvement. “[We’re] looking at fine tuning, that's not part of the MLPerf results here. But that's where you can take a large model and just bring the last few layers. We have some experiments in house now. We'll release them when we do the tech press briefings in December to show that we can train go do fine-tuning in less than 10 minutes on some of these models, including, you know, something as large as a BERT large model. It will share the specific data then once it's approved.”
Feature art: Nvidia's H100 GPU
Link to MLCommons press release, https://www.hpcwire.com/off-the-wire/latest-mlperf-results-display-gains-for-all/
Link to Nvidia blog, https://www.hpcwire.com/off-the-wire/nvidia-hopper-ampere-gpus-sweep-mlperf-benchmarks-in-ai-training
Link to Intel blog, https://www.intel.com/content/www/us/en/newsroom/news/leading-ai-performance-results-mlperf-benchmark.html#gs.hsm0cu
Links to statements by MLPerf submitters:






