



Meta Releases AI Model That Translates Over 200 Languages

If you’ve ever witnessed the bizarre word stew that Facebook sometimes concocts when translating content between languages, you have seen how translation technology doesn't always hit its mark. That could be changing soon, especially for less common languages.
Meta has released an open source AI model capable of translating 202 different languages. The model is called NLLB-200 and is named after the company’s No Language Left Behind initiative. Meta says it will improve the quality of translations across its technologies by an average of 44% with that number jumping to 70% for some African and Indian languages, as shown by its BLEU benchmark scores.
The No Language Left Behind effort stems from the lack of high-quality translation tools for what natural language researchers call low resource languages, or those with little to no data available to train language models. Without proper means for translation, speakers of these languages, often found in Africa and Asia, may be unable to fully engage with online communication or content in their preferred or native languages. Meta’s initiative seeks to change that.
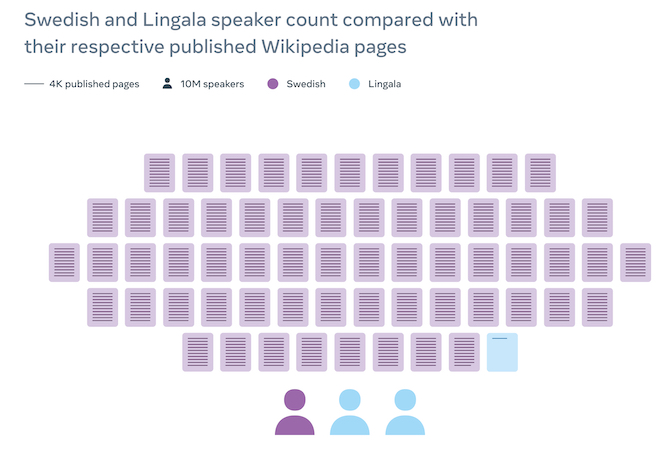
This graphic shows the disparity in Wikipedia articles available between Lingala and Swedish. Source: Meta
“Language is the key to inclusion. If you don’t understand what people are saying or writing, you can be left behind,” said Jean Maillard, research engineer at Meta AI in a video.
The model supports 55 African languages with high quality results, according to Meta, while other popular translation tools can only facilitate less than 25. In order to improve the NLLB-200 model and confirm that translations are high quality, Meta built an evaluative dataset called FLORES-200 that allows assessment of the model’s performance in 40,000 different language directions.
The company is now sharing NLLB-200 and FLORES-200 along with the model training code and the code for reproducing the training dataset. Meta is also offering grants up to $200,000 to nonprofit organizations and researchers for what it calls impactful uses of NLLB-200, or projects related to sustainability, food security, gender-based violence, or education. The company is specifically encouraging nonprofits focused on translating two or more African languages to apply for the grants, as well as researchers in linguistics, machine translation and language technology.
Meta has lofty goals for its own use of the language model. NLLB-200 will support over 25 billion translations used daily on Facebook, Instagram, and other platforms maintained by the company. The company asserts that higher accuracy in translations available for more languages may aid in finding harmful content or misinformation, protecting election integrity, and stopping online sexual exploitation and human trafficking.
Additionally, Meta has begun a partnership with the Wikimedia Foundation to improve translations on Wikipedia by using NLLB-200 as its back end content translation tool. For languages spoken mainly outside of Europe and North America, there are far fewer articles available than the over 6 million English entries or the 2.5 million available in Swedish. To illustrate, for the 45 million speakers of Lingala, a language spoken in several African countries including the Democratic Republic of the Congo, there are only 3,260 Wikipedia articles in their native language.
“This is going to change the way that people live their lives … the way they do business, the way that they are educated. No language left behind really keeps that mission at the heart of what we do, as people,” said Al Youngblood, user researcher at Meta AI in a video.
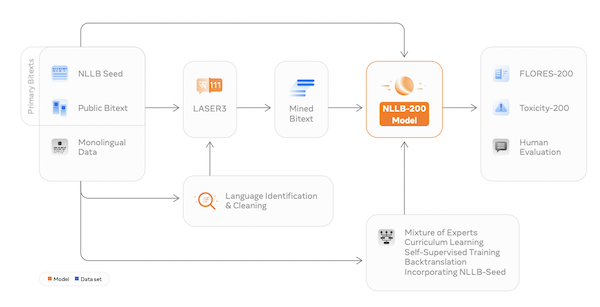
The final ecosystem of NLLB-200, encompassing all of the datasets and modeling techniques used in its creation. Source: Meta
Like most AI projects, NLLB-200 has come with challenges. AI models are trained with large amounts of data, and “for text translation systems, this typically consists of millions of sentences carefully matched between languages. But there simply aren’t large volumes of parallel sentences across, say, English and Fula,” the company noted.
Researchers could not go the usual route of overcoming this through mining data from the web, as the required data may not even exist in some cases and could lead to inaccuracy. Instead, Meta upgraded an existing NLP toolkit, LASER, into a new version. The LASER3 multilingual embedding method “uses a Transformer model that is trained in a self-supervised manner with a masked language modeling objective. We further boosted performance by using a teacher-student training procedure and creating language-group specific encoders, which enabled us to scale LASER3’s language coverage and produce massive quantities of sentence pairs, even for low-resource languages.” LASER3 and its billions of parallel sentences in different language pairs are also now being offered as open source tools.
Meta says that optimizing a single model to work effectively and accurately across hundreds of languages was also a significant challenge requiring ingenuity. Translation models can generate hard-to-trace errors such as misstatements, unsafe content, and “hallucinations,” or glitches that can change the meaning of training data completely.
“We completely overhauled our data cleaning pipeline to scale to 200 languages, adding major filtering steps that included first using our LID-200 models to filter data and remove noise from internet-scale corpora with high confidence. We developed toxicity lists for the full set of 200 languages, and then used those lists to assess and filter potential hallucinated toxicity,” the company said. “These steps ensured that we have cleaner and less toxic datasets with correctly identified languages. This is important for improving translation quality and reducing the risk of what is known as hallucinated toxicity, where the system mistakenly introduces toxic content during the translation process.”
For comprehensive technical specifications, read the Meta researcher’s full scientific paper at this link. To see NLLB-200's translation capabilities in action through stories translated with the technology, visit the Meta AI Demo Lab.






