



Cerebras Systems Thinks Forward on AI Chips as it Claims Performance Win

Cerebras Systems makes the largest chip in the world, but is already thinking about its upcoming AI chips as learning models continue to grow at breakneck speed.
The company’s latest Wafer Scale Engine chip is indeed the size of a wafer, and is made using TSMC’s 7nm process. The next chip will pack in more cores to handle the fast-growing compute needs of AI, said Andrew Feldman, CEO of Cerebras Systems.
“In the future it will be five nanometers and it will keep growing. There are always opportunities to improve the performance,” Feldman said.
The WSE-2 chip (which powers the CS-2 system) has 850,000 cores and has 2.6 trillion transistors, and the company isn’t done maximizing the performance of the chip yet. On Wednesday, the company claimed it had trained the largest AI model ever trained on a single chip. This is an AI equivalent to a conventional CPU being the world’s fastest processor.
The AI model is the Eleuther-GPT-NeoX, a natural language processing framework with 20 billion parameters.
“It takes minutes to set these models up. And that you can quickly and easily move between these models with a few keystrokes,” Feldman said.
 Other multi-billion parameter NLP models trained by the CS-2 include GPT-3L (1.3 billion), GPT-J (6 billion), GPT-3 (13 billion).
Other multi-billion parameter NLP models trained by the CS-2 include GPT-3L (1.3 billion), GPT-J (6 billion), GPT-3 (13 billion).
The company made a comparison to training similar AI models on a cluster of graphics processors. The CS-2 can save time, power and space, the company claimed.
The number of parameters in natural language processing are exceeding 1 trillion, and the CS-2 could do much larger models than 20 billion parameters, and the company plans to announce more breakthroughs later this year.
“We could do 100 trillion,” Feldman said.
The company claims the CS-2 can build out a better network structure and compute for AI, which are then broken up over the on-chip cores. The GPU model involves orchestrating the calculations needed to be broken up to the ability of a GPU, and establishing a structure so the response times of the hundreds of GPUs are coordinated.
By comparison, CS-2 has everything on a chip, with its programmable cores in a mesh network adapting to the compute requirements.The company claims the bandwidth between the on-chip cores is faster than over a cluster of interconnected GPUs.
“We have more compute resources on chip and because of our weight-streaming architecture, we can support models with very large parameters on a single chip,” Feldman said, adding “the models are often in TensorFlow or PyTorch. You’ve got your model and you’ve got your data, and our compiler wraps it all up.”
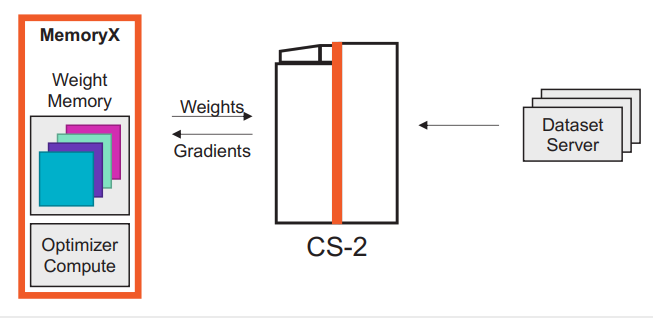
Cerebras Weight Streaming architecture disaggregates memory and compute.
Cerebras is largely making comparisons with Nvidia, which dominates the market and whose GPUs are driving AI computing. Nvidia’s dominance is good for the GPU chipmaker, but it’s also bad as it also exposes the weaknesses of the GPU architecture, Feldman said.
One of Cerebras’ notable wins, GlaxoSmithKline, in December last year in an academic paper said that Cerebras systems saved days on drug discovery compared to GPUs.
“Using standard GPU hardware, training a model with a large capacity appropriate to the dataset would have taken weeks or months. Cerebras Wafer Scale Engine (WSE) within the Cerebras CS-1 system enabled us to train models of this scale in just a few days, which also made it feasible to explore hyperparameters and architectures,” researchers at GSK wrote.
Computers from Cerebras Systems have also been adopted by academia. Leibniz Supercomputing Centre added a system that combined the CS-2 with a HPE Superdome Flex to its stash of high-performance computers.
CS-2 systems are set up at the Pittsburgh Supercomputing Center, Argonne National Laboratory, Lawrence Livermore National Laboratory and, most recently, the National Center for Supercomputing Applications. CS-2 systems typically cost millions of dollars, and Cerebras says it can help redirect researchers without big budgets to those supercomputing resources.






