



HPE Launches ML Development System, Swarm Learning Solution

In a one-two punch of new AI announcements, Hewlett Packard Enterprise (HPE) today announced its new Machine Learning Development System (MLDS) and Swarm Learning solutions. Both are aimed at easing the burdens of AI development in a development environment that increasingly features large amounts of protected data and specialized hardware.
HPE’s MLDS
HPE pitches the Machine Learning Development System as an end-to-end solution purpose-built for AI, stretching from software to hardware. The origins of the MLDS stretch back nearly a year to HPE’s acquisition of Determined AI, developer of a software stack for training AI models faster at scale. At the time, HPE promised to combine Determined AI’s software solution with HPE’s own AI and HPC offerings—and now with the MLDS, it’s doing exactly that.
The MLDS offers a full software and services stack, including a training platform (the HPE Machine Learning Development Environment), container management (Docker), cluster management (HPE Cluster Manager) and Red Hat Enterprise Linux.
“Then you’ve got a set of hardware, which is based around InfiniBand and leverages four Apollo A6500s that use eight 80GB Nvidia A100 GPUs—this is what’s being released today,” explained Justin Hotard, executive vice president and general manager for HPC and AI at HPE, in a prebriefing for press and analysts. “It combines the GPUs with service nodes and the option of storage in the form of the HPE Parallel File System Storage solution, and then connections into the enterprise via the Aruba 6300 switch.” This, he said, was the most basic configuration of the MLDS.

An overview of the MLDS. Image courtesy of HPE.
“This came to HPE as part of the acquisition of Determined AI, and this product—the Machine Learning Development System—is really an opportunity to combine the best of that software with the best hardware on the market and assemble it together as an appliance,” summarized Evan Sparks, vice president for HPC and AI at HPE. Sparks—who was the founder and CEO of Determined AI—added that it was a “complete offering” that could not have been achieved as an independent software company.
“This is something we’ve talked about pretty extensively since we acquired Determined AI last summer,” Hotard said. “Training these deep learning models is not only complex and time-consuming, it’s very resource-intensive. What we found through the acquisition of Determined AI and with many customers that we met ahead of that and following is: many of the engineers spend their time really managing infrastructure. They’re dealing with a lot of the technical intricacies of the infrastructure as opposed to really focusing on optimizing their goals and refining them at scale.”
“What we see is that -- much like we see in HPC -- customers need specialized infrastructure,” he continued. “There’s been a massive explosion in companies developing accelerators and looking for different levels of optimization and that actually makes it harder on the individual data scientists and engineers because that just drives up complexity as they’re working through their solution.” Hotard said that these specific, rigid solutions are costly and often ineffective at scale. HPE, he said, wanted to give developers flexibility in terms of where they could develop, train and deploy their models. With the MLDS, he argued, “they can focus their expertise on developing and training models at scale and on the business outcome and the business value.”
“What we’ve seen is that this platform has actually delivered faster performance compared to other systems on the market today, particularly when running an NLP workload, and also even faster—and somewhat more effective—when running a computer vision workload,” Hotard detailed.
By way of example, HPE cited a pilot customer: Aleph Alpha, a European natural language processing startup that needed a solution allowing for various levels of parallelism and scaling. Aleph Alpha deployed 16× the basic configuration of the MLDS, for a total of 64 HPE Apollo A6500 systems. HPE reported that the systems were set up in “just a couple days,” with training beginning in two days, and that Aleph Alpha quickly achieved faster results.
“We are seeing astonishing efficiency and performance of more than 150 teraflops by using the HPE Machine Learning Development System,” said Jonas Andrulis, founder and CEO of Aleph Alpha. “The system was quickly set up and we began training our models in hours instead of weeks. While running these massive workloads, combined with our ongoing research, being able to rely on an integrated solution for deployment and monitoring makes all the difference.”
The MLDS is now available worldwide.
HPE’s Swarm Learning
Hotard said that "the way things operate today" tends to center around collecting data and bringing into a single core location for model training and model development. “Realistically, that data is, in many cases, collected and gathered at the edge," he said. "In some cases, moving that data from the edge to the core has implications for compliance and GDPR and other regulations, and so it’s not trivial to simply move everything into one central location.”
This, he said, compounds the costs and complexities of moving that data on a technical and infrastructural level, and with data increasingly federated across cloud services and geographies, the problems are only getting worse. “What we’re trying to eliminate,” he said, “is the dependency on centralizing and consolidating the data.”
Enter Swarm Learning, HPE’s answer for edge ML, which allows models to be trained locally across a swarm of edge or distributed systems, which share their findings but not their data. Swarm Learning, HPE said, is effectively composed of a set of APIs and is purely software-based—and can be integrated with the MLDS, as well.
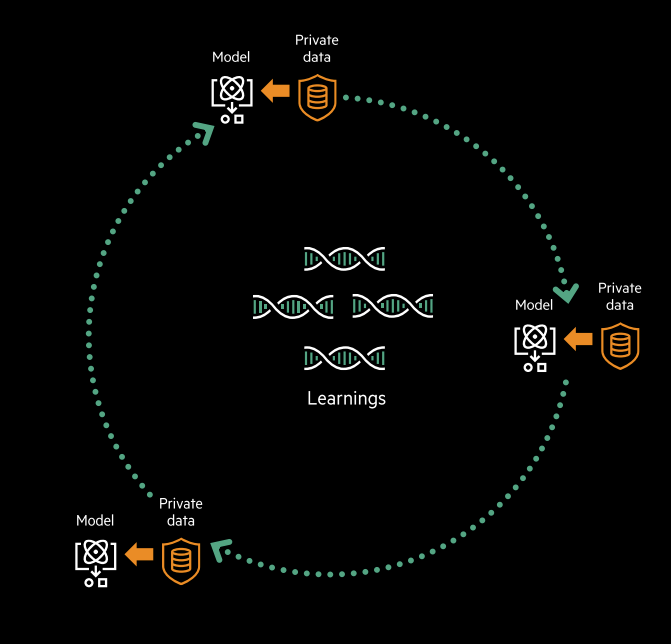
A basic diagram of HPE Swarm Learning. Image courtesy of HPE.
HPE cited a wide range of use cases for Swarm Learning, beginning with healthcare. Due to strong restrictions on the sharing of medical data between medical facilities—let alone between countries—HPE argued that it was a perfect sector for Swarm Learning, highlighting an example where models were able to be trained on health data among varied institutions and multiple countries “without violating GDPR, HIPAA or the Consumer Privacy Act.”
“We see many applications in this space,” Hotard said. “We see applications in finance, we see applications in government and in areas like climate and weather where there could be significant value in leveraging swarm learning to accelerate insight without compromising the data itself.”
HPE Swarm Learning is also available now.






