



Habana AI Announces Breakthrough MLPerf Results for AI Training Platform
Dec. 1, 2021 -- The MLPerf community aims to design fair and useful benchmarks that provide “consistent measurements of accuracy, speed, and efficiency” for machine learning solutions. To that end, AI leaders from academia, research labs, and industry decided on a set of benchmarks and a defined set of strict rules that ensure fair comparisons among all vendors. As machine learning evolves, MLPerf evolves and thus continually expands and updates its benchmark scope, as well as sharpens submission rules. At Habana we find that MLPerf benchmark is the only reliable benchmark for the AI industry due to its explicit set of rules, which enables fair comparison on end-to-end tasks. Additionally, MLPerf submissions go through a month-long peer review process, which further validates the reported results.
MLPerf Submission Divisions and Categories
The MLPerf training benchmark has two submission divisions: Closed, which focuses on providing a fair comparison with results derived from an explicit set of assessment parameters— and Open, which allows vendors to showcase their solution(s) more favorably without the restrictive rules of the closed category. Customers evaluating these results are also provided additional categories to help them discern which solutions are mature and commercially available (“available” category) vs. solutions not yet publicly available but coming to market at some point in the reasonably near future (”preview” category) or experimental/for research purposes without a defined go-to-market expectation (“research” category).
Habana’s MLPerf training v1.1 Benchmark Results
We’re pleased to deliver the second set of results for the Habana Gaudi deep learning training processor, a purpose-built AI processor in Intel’s AI XPU portfolio. This time at scale!
Habana submitted results for language (BERT) and vision (ResNet-50) benchmarks on Gaudi-based clusters and demonstrated near-linear scalability of the Gaudi processors. Our ongoing efforts to optimize the Habana software stack (SynapseAI 1.1.0), which focused recently on including data packing, and checkpoint-saving, resulted in more than a 2x improvement in BERT time-to-train using the same Gaudi processors compared to our last round results. In addition, Gaudi time-to-train on ResNet-50 improved by 10%.
Time-to-Train Measurements
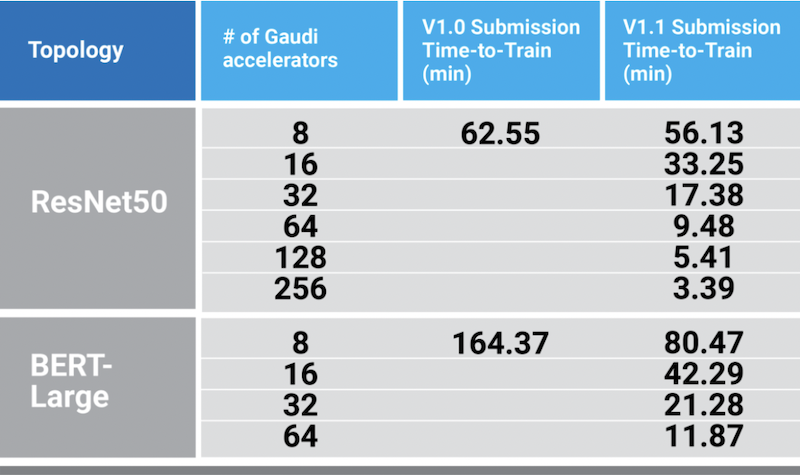
These results highlight the usability and scalability of Gaudi and demonstrate the capabilities of our SynapseAI software platform, which includes Habana’s graph compiler and runtime, communication libraries, TPC kernel library, firmware, and drivers. SynapseAI is integrated with TensorFlow and PyTorch frameworks and is performance-optimized for Gaudi processors.
Scale Up
Below are our naïve and weak scale up charts. The latter also considers the total number of samples required to achieve convergence. While many accelerators require increasing the batch size with the number of workers to fully utilize the hardware, here we see that up to 64 Gaudis the weak and naïve scale up have similar behavior. This is due to the Gaudi architecture, which can achieve high utilization even with small batch-sizes.
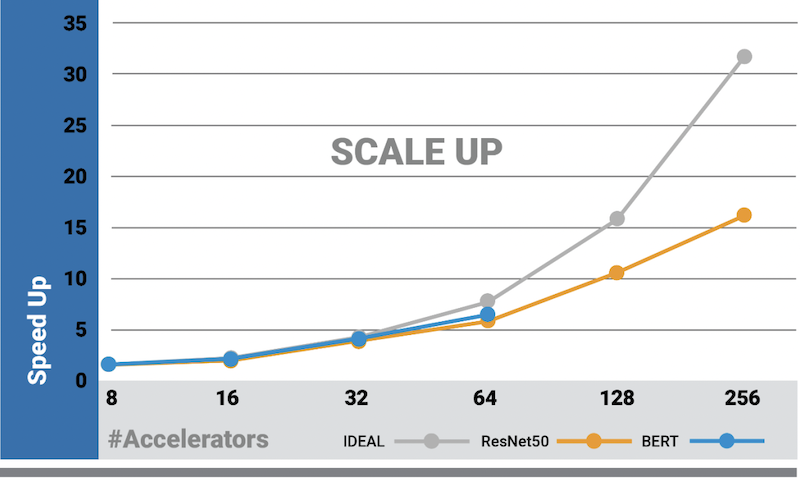
Naive Scale Up
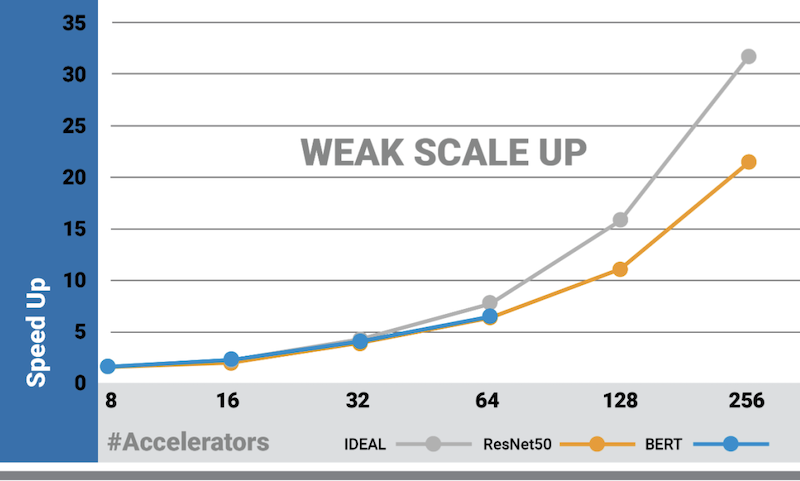
Weak Scale Up
The Technology Behind the Results
To achieve Gaudi’s substantial performance advances, we applied the following optimizations.
Data Packing
The BERT model works on sequences of different lengths. While the maximum sequence length is 512 tokens, the average sequence is only half of that. Thus, practitioners commonly pad short sequences with zero as to enter a fixed size of 512 tokens. This results in many unneeded operations that can be eliminated. In this submission, we used a new technique named data packing. Data packing takes several short sequences and packs them together to one multi-sequence of fixed size. As an example, 3 sequences with lengths of 100, 100, 312 would be packed into one sequence of 512. We detail the process of packing the data and the required changes to the model in our Jupyter notebook; Please see tutorial here.
Fast and Light Checkpoint Saving
When running on a few machines, the time required for checkpoint savings is negligible, but this is not the case when running at large scale. Therefore, in this submission, instead of letting one worker save the checkpoint, we asked each worker to save a subset of the model weights. Additionally, we saved only the required variable to run evaluation instead of the entire model, thus deriving greater efficiency resulting in higher performance.
Low Level Optimization
Habana is continually improving its SynapseAI software platform, which includes Habana’s graph compiler and runtime, communication libraries, TPC kernel library, firmware, and drivers.
Looking Forward
We continue to invest significant focus and resources to continually improve Gaudi software features, with additional models and performance optimizations. We look forward to our next set of advancements that can serve diverse applications and customer requirements.
Posted in Habana Blog.
Source: Habana AI






