



Nvidia Debuts Enterprise-Focused 530B Megatron Large Language Model and Framework at Fall GTC21
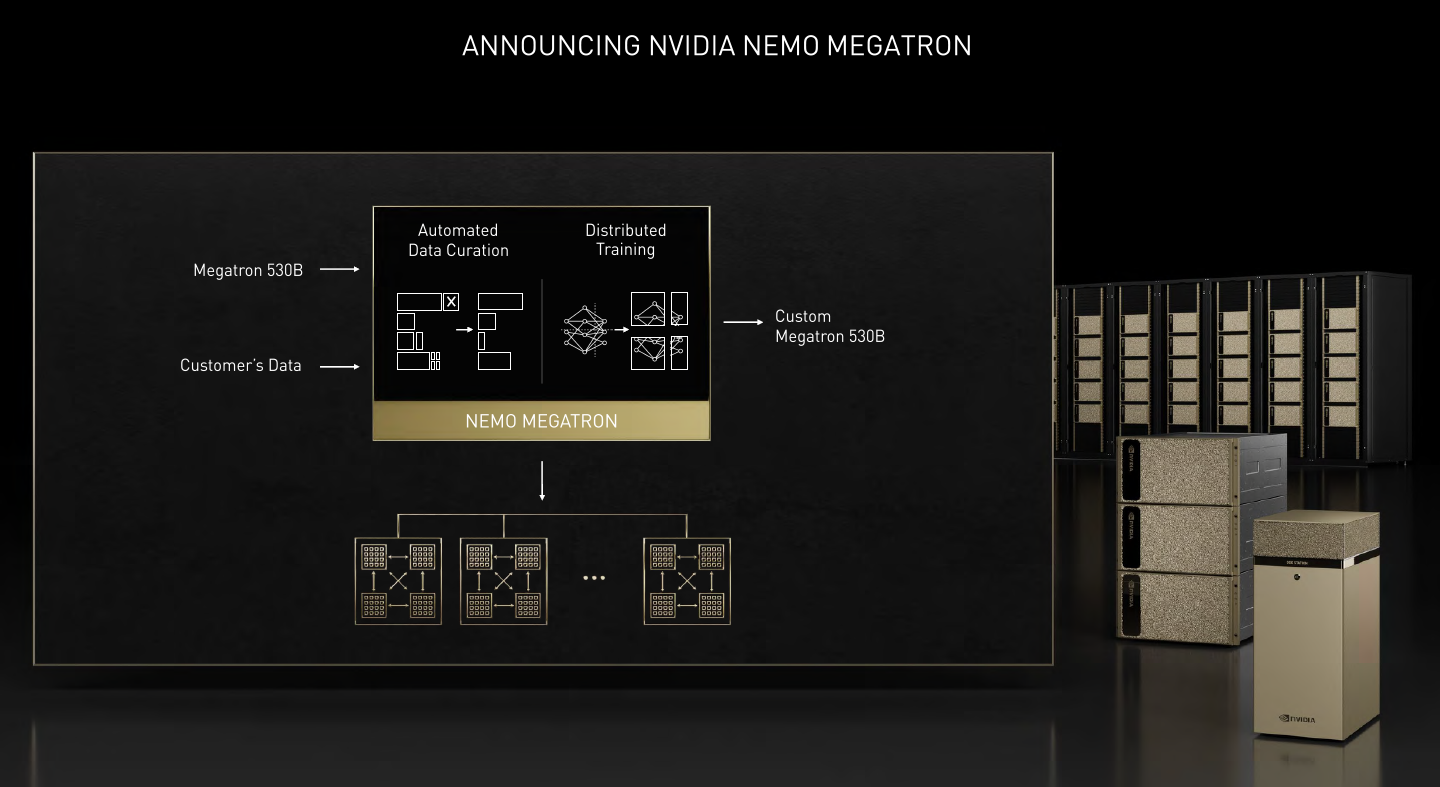
Bringing large language model (LLM) capabilities directly to enterprises to help them expand their business strategies and capabilities is the focus of Nvidia’s new NeMo Megatron large language framework and its latest customizable 530B parameter Megatron-Turing model.
Unveiled Nov. 9 at the company’s fall GTC21 conference, the new Megatron framework and the model itself were central themes for Nvidia CEO Jensen Huang’s event keynote, who described the technologies as giving enterprises promising capabilities to do much more with their data and business planning.
Also unveiled at the fall GTC21 event was a new Modulus AI framework that gives engineers, scientists and researchers a customizable, physics-based toolkit that will allow them to build neural network models of digital twins for enterprise use. GTC21 is being held virtually due to the lingering COVID-19 pandemic.
Megatron Framework and Models
Using LLMs, enterprises will be able to use the Megatron framework to train language models with trillions of parameters, while the Megatron-Turing NLG (natural language generator) 530B customizable LLM will be trainable for new domains and languages, according to Nvidia. The LLMs are envisioned as enabling enterprises to build their own domain-specific chatbots, personal assistants and other AI applications which will understand human languages with much more sensitive levels of subtlety, context and nuance. Using Nvidia DGX systems, the models aim to provide enterprises with production-ready, enterprise-grade capabilities to simplify the development and deployment of LLMs.
The Megatron framework and model build on Nvidia’s work with the open source Megatron project, which is led by Nvidia researchers who study the training of large transformer language models at scale. Megatron 530B is the world’s largest customizable language model, according to the company.
 “The recent breakthrough of Large Language Models is one of the great achievements in computer science,” said Huang in his keynote. “There is exciting work being done in self-supervised multi-modal learning and models that can do tasks that it was never trained on.”
“The recent breakthrough of Large Language Models is one of the great achievements in computer science,” said Huang in his keynote. “There is exciting work being done in self-supervised multi-modal learning and models that can do tasks that it was never trained on.”
The NeMo Megatron framework was designed and created with these tasks in mind, he said, with capabilities to train speech and language models with billions and trillions of parameters.
“LLMs can answer deep domain questions, comprehend and summarize complex documents, translate languages, write stories, write computer software, understand intent, be trained without supervision, and are zero-shot, meaning that they can perform tasks without being trained on any examples,” said Huang. “Our researchers trained GPT-3 on NVIDIA’s 500-node Selene DGX SuperPOD in 11 days and together with Microsoft trained the Megatron MT-NLG 530 billion parameter model in six weeks. With NeMo Megatron, any company can train state-of-the-art Large Language Models.”

Jensen Huang, Nvidia CEO
The growing potential of this technology is being seen regularly, said Huang. “Customizing large language models for new languages and domains is likely the largest supercomputing application ever to come along,” he said.
Nvidia Modulus AI Framework
Also getting Huang’s attention was Nvidia Modulus, a newly announced AI framework powered by physics machine learning models that can build neural network models of industrial digital twins which can then be used by enterprises for a wide range of development and business tasks. Modulus can also be used for climate science, protein engineering and more, according to Nvidia.
Digital twins allow data scientists and researchers to conduct experiments and see results by modeling ideas on virtual representations of actual factories, industrial facilities and other physical locations, infrastructure or products, instead of using real-world facilities or products. By using visual representations of real-world items or facilities, development costs and complexity can be reduced, and initial development can be done with far less effort. Digital twin modeling can help a wide range of problems, from a molecular level in drug discovery up to global challenges like climate change, according to Nvidia.
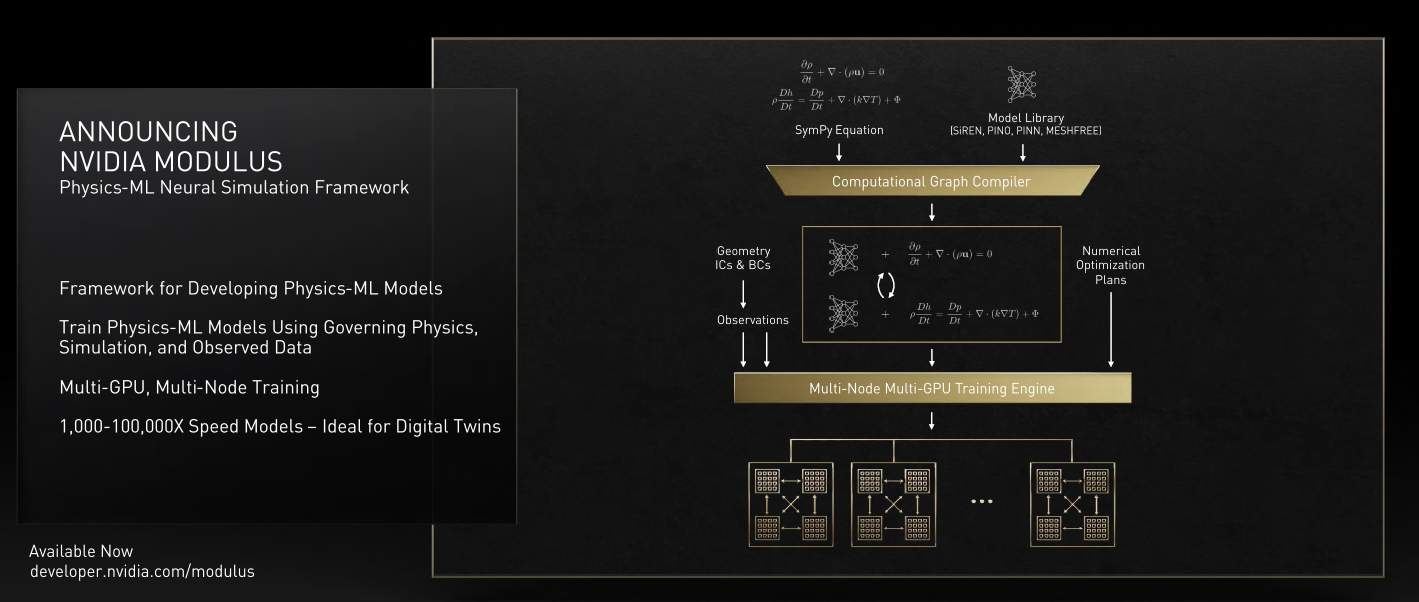 With Modulus, neural networks can be trained to use the fundamental laws of physics to model the behavior of complex systems in a wide range of fields. The surrogate model can then be used in various applications of digital twins from industrial use cases to climate science.
With Modulus, neural networks can be trained to use the fundamental laws of physics to model the behavior of complex systems in a wide range of fields. The surrogate model can then be used in various applications of digital twins from industrial use cases to climate science.
“Modulus has been optimized to train on multi-GPU and multi-node [systems],” said Huang. “The resulting model can emulate physics 1,000 to 100,000 times faster than simulation. With Modulus, scientists will be able to create digital twins to better understand large systems like never before.”
One area where major advancements could result is in climate science as the world continues to confront climate change, he said. “The largest reservoirs in the U.S. are at their lowest levels in two decades – some 150 feet below where they were. The combination of accelerated computing, physics-ML and giant computer systems can give us a million-X leap and give us a shot. We will use principled-physics models and observed data to teach AI to predict climate – in super-real-time.”
Ultimately, researchers could model the Earth itself, said Huang. “We can create a digital twin of the Earth that runs continuously to predict the future, calibrating and improving its predictions with observed data, and predict again.”
Modulus works with Python-based APIs to take symbolic governing partial differential equations and build physics-based neural networks. It also includes a physics-ML engine which takes uses PyTorch and TensorFlow to train models as well as the Nvidia CUDA Deep Neural Network library (cuDNN) for GPU acceleration and Nvidia Magnum IO for multi-GPU and multi-node scaling.
Interesting Moves, Say Analysts

Karl Freund, analyst
Karl Freund, the founder and principal analyst for Cambrian AI Research, said the latest Nvidia GTC announcements show how far the company has come in its evolution.
“Nvidia has now completed the transition from a GPU company to a provider of compute platforms, with all the hardware and software you need to build a solution,” said Freund. “While Facebook talks metaverse, Nvidia is delivering it to enterprises, and that is where the money is.”
Another analyst, R. Ray Wang of Constellation Research, said that Nvidia’s new Megatron LLM framework and model deliver solid choices for enterprise users that want to dive into this segment.

R. Ray Wang, analyst
“Basically, if you really want to get massive generative language models, this is the one [to use], and that is important because right now most of the models are lacking precision because there is not enough data [involved],” said Wang. “You want massive, massive parameters and massive datasets so it [delivers] better deep learning. This is one that is important.”






