



Run:AI Looks to Bring 100% GPU Utilization to its AI-Focused Compute Orchestration Platform

One of the biggest challenges in AI development is to efficiently allocate and utilize the available power and performance of GPUs that are crunching AI models. Running those workloads on GPUs is expensive and companies want to make the process as streamlined and cost-effective as possible.
To help enterprises reach those goals, two-year-old Israel-based AI startup Run:AI announced that it will add two critical new GPU utilization features to its flagship Run:AI compute orchestration software platform for AI workloads in the fourth quarter of this year.
The new features, thin GPU provisioning and job swapping, promise automated new processes that aim to bring AI cluster utilization to almost 100 percent, according to the company. The new features are designed to prevent costly GPU resources from sitting idle when they are not being used directly on AI workloads by data scientists and developers.
The thin GPU provisioning is modeled after classic thin provisioning features introduced in the past in storage area networks, virtual disks and even for making CPUs more efficient. In the case of Run:AI, the thin GPU provisioning will essentially allocate GPU resources exactly when they are needed so they are not wasted by being held up in an unused state.
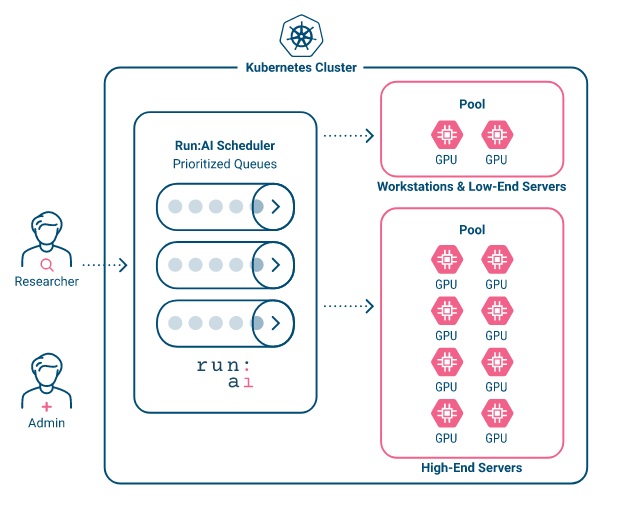
The new job swapping feature, meanwhile, will now allow the Kubernetes-based Run:AI compute orchestration platform to seamlessly swap workloads when one job is completed, and another is waiting to start, like when dinner reservations overlap in a busy restaurant.

Fara Hain of Run:AI
“You reserve a table from 8 to 10 p.m., but you ate quickly, and you left at 9 p.m.,” said Fara Hain, the vice president of marketing for Run:AI. “The swap allows us to put a new job right into that reserved table. I can immediately give it to new people who are waiting.”
For enterprise users, it is all about speed of execution and experimentation, she said. “Your job is pending in a long queue of jobs, but somebody else finished so now your job can run quick more quickly. It happens in an automated way. Nobody needs to look at this anymore.”
By adding the two new features, customers will be able to ensure that enough GPU resources are always available for all researchers, according to the company. Both features are currently in testing in Run:AI customer labs, with planned deployment of the feature updates later in the year.
But the problem is not just about saving money when talking about improving GPU resource allocation rates, said Hain. Even more important is assuring that whatever pools of AI compute resources that have been purchased by a company are being used to the max to maintain the most efficient development workflows by their data science teams.
“Researchers run a bunch of different types of jobs, and in the beginning, they are working on their code,” said Hain. “And then they run these short ‘build jobs.’ They are building a model, but they have to run something first to see if it works.”
 All that time, though, the developer holds onto the compute resources of that GPU, even when they are fixing the code in between running their actual models, she said.
All that time, though, the developer holds onto the compute resources of that GPU, even when they are fixing the code in between running their actual models, she said.
“That is the biggest waste of GPU resources, because they are hugging GPUs as they are doing that process, sometimes for days or weeks,” afraid to give it up and then not get it back later, said Hain.
The problem is that when GPU resources are held back like that, costs rise, efficiencies drop and whole clusters look like they are already allocated, even when they are not, she said. “What you see on our dashboard is that you might have 40 percent utilization on a cluster that is 100 percent allocated,” said Hain.
These are the scenarios that inspired the development of the new thin GPU provisioning and job swapping features by the company, she said. “What we want to do with everything we add is to get you closer and closer to 100 percent utilization of this very expensive resource.”
Customers do not want to buy more GPU compute resources just because they think they are at full utilization of what they already have, said Hain. Instead, they want to be able to predict when they will be fully utilizing what they have before adding more. “They are just flying blind right now. We are trying to make GPU utilization as efficient and effective as utilization of any hardware.”

Karl Freund, analyst
Karl Freund, founder and principal analyst at Cambrian AI Research, told EnterpriseAI that Run:AI is adding needed features to its application.
“GPU utilization is a big issue,” said Freund. “That is why Nvidia launched their hardware solution, Multi-Instance GPUs. But software is definitely needed to orchestrate and generally manage this in the data center, so I think Run:AI is on the right track.”

Chirag Dekate, analyst
Chirag Dekate, an AI infrastructure, HPC and emerging compute technologies analyst with Gartner, said the new features will be helpful.
“It will further strengthen their offering, enabling them to differentiate on a clearer set of platform oriented features,” said Dekate.
In January, Run:AI secured $30 million in new Series B funding from several investors, including by Insight Partners and previous investors TLV Partners and S-Capital.
Run:AI is designed to work with GPUs from any vendor, but so far it is implemented to work with GPUs from Nvidia, which is the market leader. The company expects to support GPUs from other vendors in the future.
Run:AI's deep learning virtualization platform has been available to customers since early 2020 and has been adopted by many large enterprise users in the financial, automotive and manufacturing industries.
The platform aims to help relieve the bottlenecks that many companies hit as they try to expand their AI research and development, according to the company. The enormous AI clusters that are being deployed on-premises, in public cloud environments and at the edge often can’t be fully utilized due to segmentation and compute limitations built into the systems. That is where Run:AI’s software can be benefit by tailoring its software to the needs of customer AI workloads running on GPUs and similar chipsets.
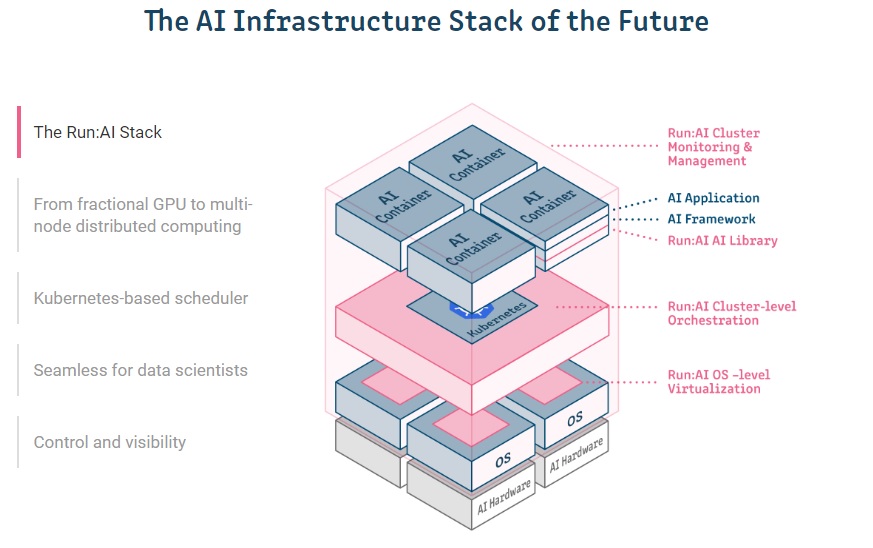 The company claims that its Kubernetes-based container platform is the first to bring OS-level virtualization software to workloads running on GPUs by automatically assigning the necessary amount of compute power – from fractions of GPUs to multiple GPUs or to multiple nodes of GPUs – so that researchers and data scientists can dynamically acquire as much compute power as they need, when they need it.
The company claims that its Kubernetes-based container platform is the first to bring OS-level virtualization software to workloads running on GPUs by automatically assigning the necessary amount of compute power – from fractions of GPUs to multiple GPUs or to multiple nodes of GPUs – so that researchers and data scientists can dynamically acquire as much compute power as they need, when they need it.






