



Google Cloud Nvidia A100 GPU A2 VM Instances Now Generally Available

Image credit: Shutterstock
Eight months after making its Nvidia A100 A2 VM cloud services available on Google Cloud as a beta service for customers, Google Cloud has announced that they are now generally available.
Google Cloud’s move follows its cloud rivals Oracle and Amazon Web Services (AWS), which made their Nvidia A100 GPU-based cloud instances generally available in September 2020 and November 2020 respectively. Microsoft Azure’s A100 cloud instances remain in public preview.
Google Cloud’s A100 program began in July 2020 on a private alpha basis to introduce its accelerator-optimized VM services (called A2 VM) to customers as part of its A2 VM offerings on the Google Compute Engine. Prior to the private alpha, the company had its A100 services in the works for some time, according to Google.
The new A2 VM general availability was announced by the company in a March 18 post on the Google Cloud Blog written by product managers Chris Kleban and Bharath Parthasarathy. The Nvidia A100 GPU instances are available so far in the us-central1, asia-southeast1 and europe-west4 Google Cloud regions.
“Our A2 VMs stand apart by providing 16 Nvidia A100 GPUs in a single VM—the largest single-node GPU instance from any major cloud provider on the market today,” they wrote. “The A2 VM also lets you choose smaller GPU configurations (1, 2, 4 and 8 GPUs per VM), providing the flexibility and choice you need to scale your workloads.”
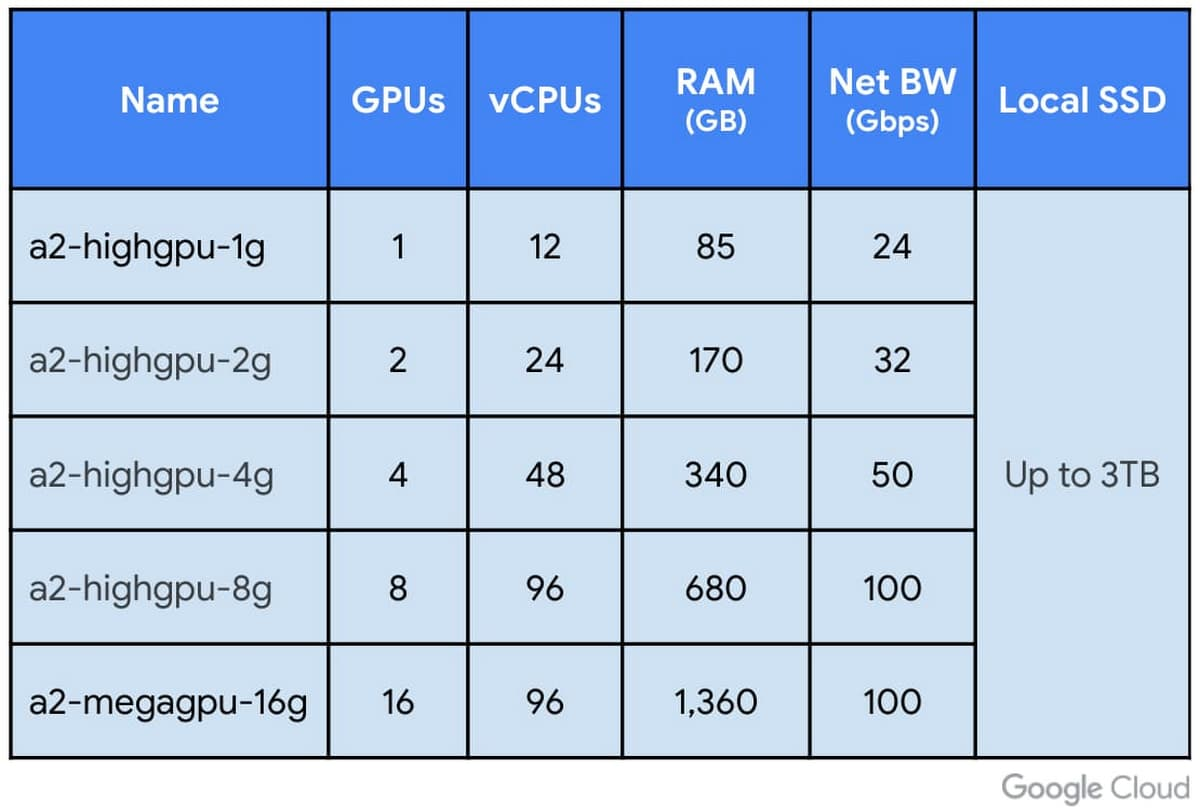
Image credit: Google Cloud
The AWS and Oracle A100-based cloud instances can so far only be configured with up to eight Nvidia A100 GPUs each, compared to the 16 available through Google Cloud’s A2 VM instances.
Google is not unveiling how many A100 instances are available to customers around the world, Kleban and Parthasarathy told EnterpriseAI. “We do not share our capacity externally,” they wrote in an email reply to questions. “Now that we are in GA, we have GPUs in the regions we have listed in the blog to support customer needs and more to come throughout 2021.”
The A2 VM instances use Nvidia HGX A100 systems to offer high-speed NVLink GPU-to-GPU bandwidth that delivers up to 600 GB/s, according the blog post. A2 VMs come with up to 96 Intel Cascade Lake vCPUs, optional local SSD for workloads requiring faster data feeds into the GPUs and up to 100 Gbps of networking. Additionally, A2 VMs provide full vNUMA transparency into the architecture of underlying GPU server platforms, enabling advanced performance tuning.
The A2 VM Google Cloud services are purpose-built for AI, ML and HPC workloads, allowing customers to scale from one to 16 GPUs without having to reconfigure their workflows, according to the company. This is Google’s first offering in its A2 VM cloud family and is built for workloads including CUDA-enabled ML training and inference and HPC.
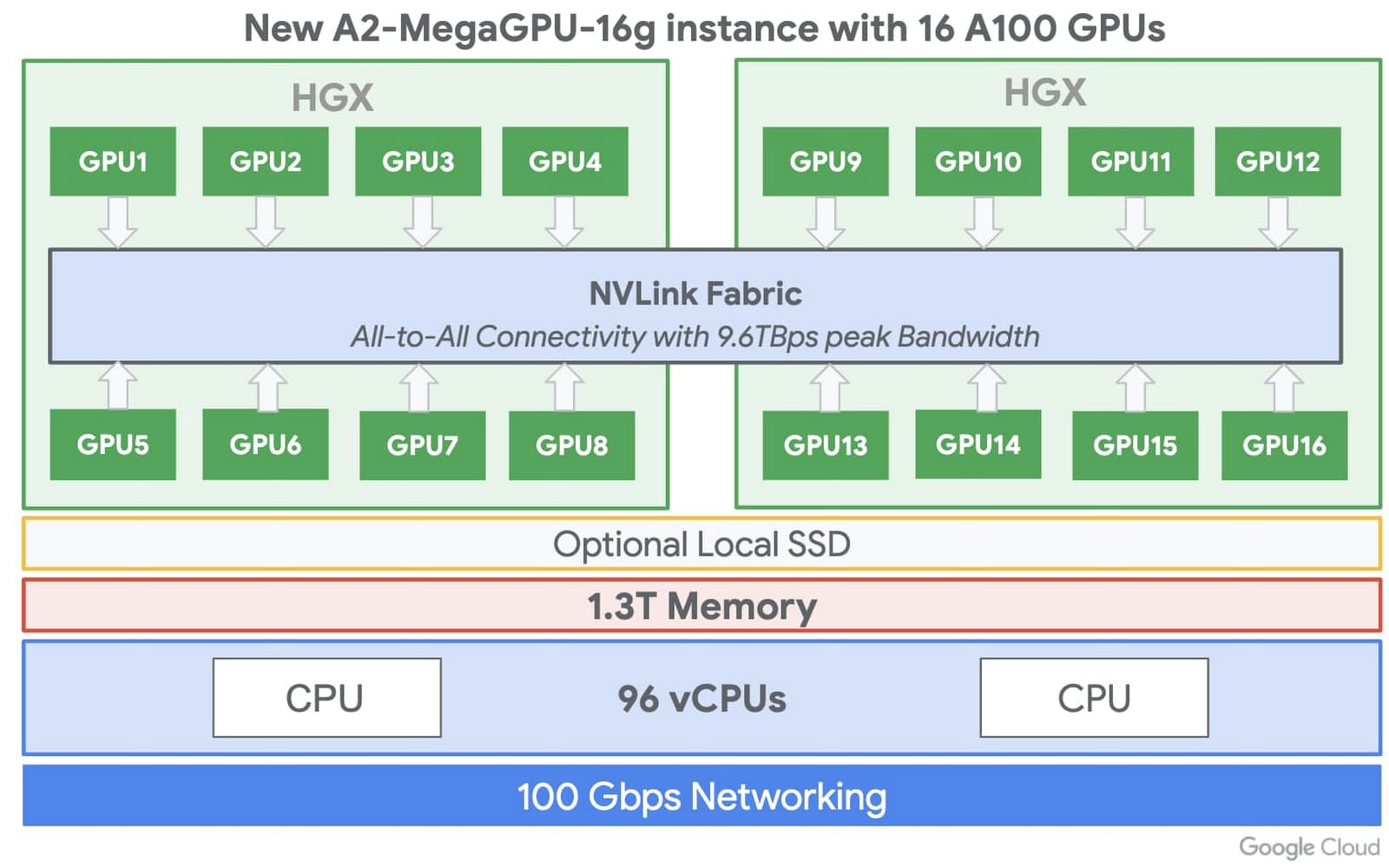
Image credit: Google Cloud
The new Google A100 instances are available immediately, allowing customers to start training ML models and serve inference workloads onto the GPUs using Google Cloud’s Deep Learning VM images in their available regions. The images include drivers, Nvidia CUDA-X AI libraries and popular AI frameworks like TensorFlow and PyTorch. The pre-built and optimized TensorFlow Enterprise Images also support A100 optimizations for current and older versions of TensorFlow (1.15, 2.1, and 2.3).
Google Cloud says it has more than 200 customers using the new service offerings, including Two Sigma, Citadel, SFDC, Square, PayPal and Walmart. Most are choosing the 16 GPU instance, according to the company.
The Nvidia A100 GPU instances are fully supported on Google Kubernetes Engine (GKE), Cloud AI Platform and other Google Cloud services.
In November of 2020, Nvidia unveiled an 80GB version of its original A100 40GB GPUs, which aims to drive new levels of supercomputing-class performance in a wide variety of uses, from AI and ML research to engineering and more. The A100 80GB GPU arrived just six months after the launch of the original A100 40GB GPUs.

Nvidia A100 80GB GPU (Image credit: Nvidia)
The A100 80GB includes third-generation Tensor Cores, which provide up to 20x the AI throughput of the previous Volta generation with a new format TF32, as well as 2.5x FP64 for HPC, 20x INT8 for AI inference and support for the BF16 data format. Also included is faster HBM2e (high-bandwidth memory) with more than 2 terabytes per second of memory bandwidth, and Nvidia MIG (multi-instance GPU) technology that doubles the memory per isolated instance, providing up to seven MIGs with 10 gigabytes each. Third-generation NVLink and NVSwitch capabilities are also included, which provides twice the GPU-to-GPU bandwidth of the previous generation interconnect technology and accelerating data transfers to the GPU for data-intensive workloads to 600 gigabytes per second.






