



MIT Researchers See Neural Nets in a New Light

Convolutional neural networks that perform well in computer vision applications also can be used to predict behavioral and other brain-like data related to object recognition. One current limitation, however, is the model’s susceptibility to distortions called “adversarial attacks.” For instance, small changes to a few pixels can confuse a CNN model.
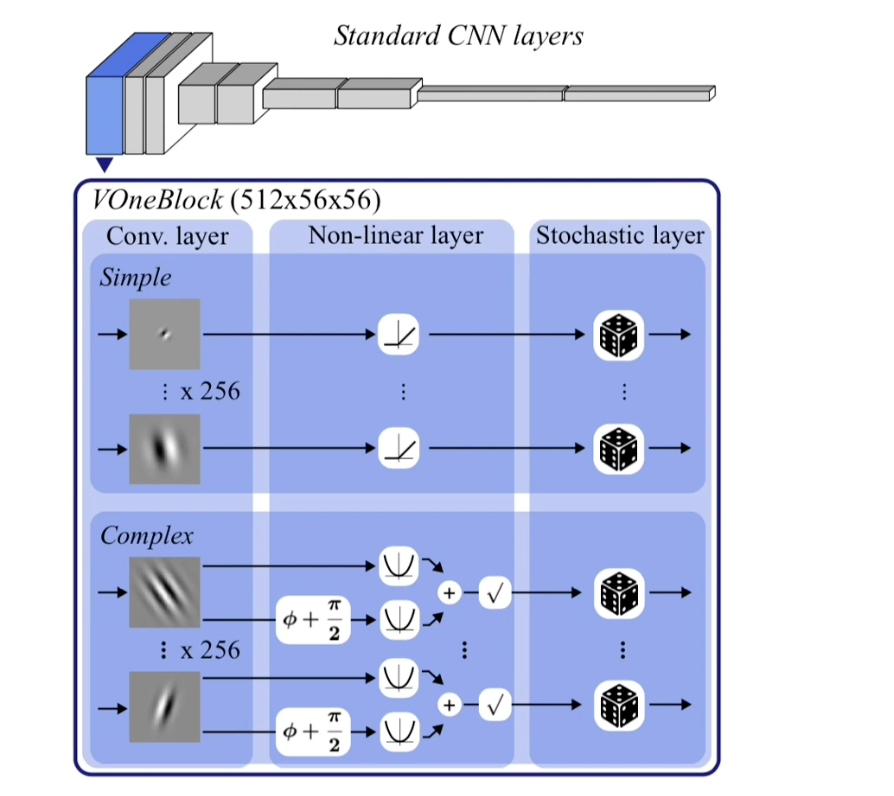
Researchers at Massachusetts Institute of Technology this week reported on a technique for overcoming adversarial attacks by adding a V1 layer to computer vision models. V1 is a reference to the ventral visual stream, the part of the brain responsible for the visual processing underlying object recognition, including the detection of edges or contours of objects.
The researchers note the V1 is among the most well-characterized components of the brain.
The research team reported during this week’s Neural Information Processing Systems meeting that it sought to gain a deeper understanding of precisely how convolutional networks identify objects. Among the goals was learning more about how the ventral visual stream is connected. That understanding would, they said, help develop more robust CNN models that are less vulnerable to adversarial attacks. Models that mimic those neural processes could then be used to train CNNs for specific tasks.
“While current CNN architectures are arguably brain-inspired, the results presented here demonstrate that more precisely mimicking just one stage of the primate visual system leads to new gains in ImageNet-level computer vision applications,” concluded the research team, which also includes investigators from Harvard University and IBM.
“Developing CNNs that are more robust would have big implications in both neuroscience and machine learning,” said Tiago Marques, an MIT researcher and one of the study’s lead authors. The challenge was developing a brain-like CNNs that identify objects as humans do.
The proposed solution is the addition of the V1 layer at the front end of a CNN used to perform object recognition. The V1-based model required no additional training and can handle distortions beyond adversarial attacks, the researchers noted.
Source: MIT
The result was a four-fold improvement in resisting adversarial attacks in three CNN models, with fewer mistakes in identifying objects caused by blurred or distorted images.
The researchers said they are next trying to identify key features of their V1 model that allow it to resist adversarial attacks. Those insights could boost the performance of future models while shedding more light on the mechanisms that allow the brain to recognize objects.
The study “directly shows that developing models that closely approximate the primate brain but were really developed by neuroscientists lead to substantial gains in computer vision,” said James DiCarlo, department head for MIT’s Brain and Cognitive Science lab and senior author of the study.
“I see this as just one example of a turn in a virtuous cycle, a cycle whereby neuroscience influences models of artificial intelligence and [AI] models come back to influence neuroscience as hypotheses and tools,” DiCarlo added.






