



VAST Data: There Will Be No Tears Shed When Tiered Storage is History

All-flash storage startup VAST Data is hoping that its vision of universal storage without multiple tiers will become the new normal for enterprises that are struggling to manage growing repositories of valuable and critical business data.
Founded in 2016, the company insists it is on the verge of upending storage practices in line with its original mission to kill the hard drive, according to Jeff Denworth, VAST’s VP of products and marketing and one of its three founders. That’s a big claim and mission. Indeed, there are several data management/storage startups seeking to disrupt the roughly 20-to-30-year-old storage paradigm based on hard disk drives (HDD) and tape and data tiering.
No one disputes the power of flash but it (still) costs too much. Instead of becoming the dominant mainstream storage technology it has found many critical niches – burst buffers is just one example – where it dramatically improves performance. Without a doubt, flash’s storage system footprint is expanding. VAST Data argues that for large enough storage systems of one petabyte or greater, the company’s all-in-one tier approach along with critical coding innovations is both less expensive and offers higher performance than the current typical mix of HDD and tape.
We’ll see. VAST Data has raised a large $180 million war chest, attracted significant customers (Lawrence Livermore National Laboratory is one), and says it grew 3x in 2019 and that 2020 has shown no letdown despite the COVID-19 pandemic. Most recently, at the fall GTC conference, Nvidia highlighted VAST Data’s ability to leverage Nvidia’s new GPUDirect (direct path from storage to GPU) capabilities on a DGX A100 system where it outperformed traditional parallel file systems.

Jeff Denworth, VAST Data
The proof, of course, is in details and sales and because VAST Data is private, it’s hard to gauge. Growth of 3x can be impressive or disappointing depending on the starting point. Says Denworth, “I understand the point you’re trying to make, and I’m telling you that there’s something extremely exceptional happening here. We’ll start to take the covers off over the next couple of months.”
In a post-SC20 briefing with EnterpriseAI and sister publication HPCwire this week, Denworth provided a glimpse under the covers. He talked about how the company leverages container technology to gain scale and performance, discussed the innovations around erasure codes and approaches that VAST has developed, and about how the company is able to achieve long-term duty cycles (more than ten years) from commodity flash. He coalesced those ideas into a cost argument saying “that gets you to a price point that is not [just] on a TCO basis superior to what you’re buying today, but on a total cost of acquisition basis.”
Notably, VAST Data doesn’t see itself as an HPC storage supplier but as broader enterprise storage supplier with the scale and performance to serve HPC requirements and particularly well-suited to serve the AI and blended HPC/AI workloads where large datasets are critical, for example, in training. Its top segment is the financial services market, closely followed by genomics. Denworth also cited the intelligence community and automotive as important segments. Currently, its product is for on-premises only.
Like many, HPCwire is eager to see what “taking the covers off” in a few months means.
This interview (which first appeared on sister website HPCwire) is edited for clarity and brevity.
HPCwire: Give us a quick primer on Vast Data. The company and you haven’t been shy about tackling big goals.
Jeff Denworth: When we started the company, we discovered that customers weren’t looking for much more performance than what you could get from the generation of flash arrays that came out around the 2010 to 2015 timeframe. That kind of challenged this idea that there would be a big wide open market for even faster flash storage products. Around the same time, we saw a bunch of very high profile, super-fast flash companies and projects kind of dissolve. So when we stopped looking at performance, we started looking at capacity. We realized that there were many opportunities to innovate [there]. At the same time, we saw technology trends, like big data and AI starting to emerge, in particular where deep learning training sets get more efficient, more accurate, [and] more effective as you expose them to larger and larger data sets.
This conclusion that the pyramid of storage that customers had been managing for the last 20 to 30 years might actually be obsolete. [It was] a time when the capacity within your data centers is the most valuable thing as opposed to like some sort of small database that previously was the most valuable thing, because that’s how AI gets trained effectively. So we started VAST with a simple goal, which is to kill the hard drive. The objective is to basically take customers, from an operational perspective, to a simpler end state, where you can imagine one tier of storage for all of their data. Then applications benefit because then you elevate all of the data sets to basically NVMe levels of performance.
You can imagine a system that has been engineered to couple the performance that you get from a tier-one all flash array with the cost that you would pay for a tier-five archive. And it’s counterintuitive, but the only way to get the cost of storage underneath the price points that you pay for hard drive-based infrastructure is to use flash. The reason for that is the way these new data reduction codes that we’ve pioneered work. You need to basically store data in very small fragments. If you did that with a hard drive, you would basically kind of fragment the hell out of the drive and you wouldn’t be able to read from it. But with flash, you don’t care.
HPCwire: So if not performance, then capacity became the target, along with flexibility?
Jeff Denworth: When we looked at the capacity opportunity, we quickly understood that file systems and object storage is where most of the capacity was in the market. So if we were building high capacity flash, it made sense to make it a distributed file system. And here, just as with the tradeoff between performance and capacity, which is one that we think we’ve broken for the first time in 30 years, there’s also a tradeoff around protocols that we’re also trying to break. The way we saw things is people were using block storage for direct attached storage for lowest latency, sub-millisecond access to their data. You use file systems when you want easy data services provisioning. You buy parallel file systems, if you want RDMA support, and good scale out. Then you buy object storage if you just want to go cheap and deep with your data.
Here we’re making a scale-out file and object storage system that has the latency of an all-flash block device. So sub-millisecond. We’ve extended the utility of file interfaces, in particular NFS, to make it not only appropriate for environments like HPC cluster environments, but also AI. We have support for NFS over RDMA. We have support for NFS multi-pathing. Nvidia showcased the results of our GPU direct storage as part of the GTC conference they did a few weeks ago.
HPCwire: The Nvidia proof-point received a fair amount of notice. Interesting that you chose NFS to focus on rather than a parallel file system. What was the thinking there?

Nvidia DGX-A100
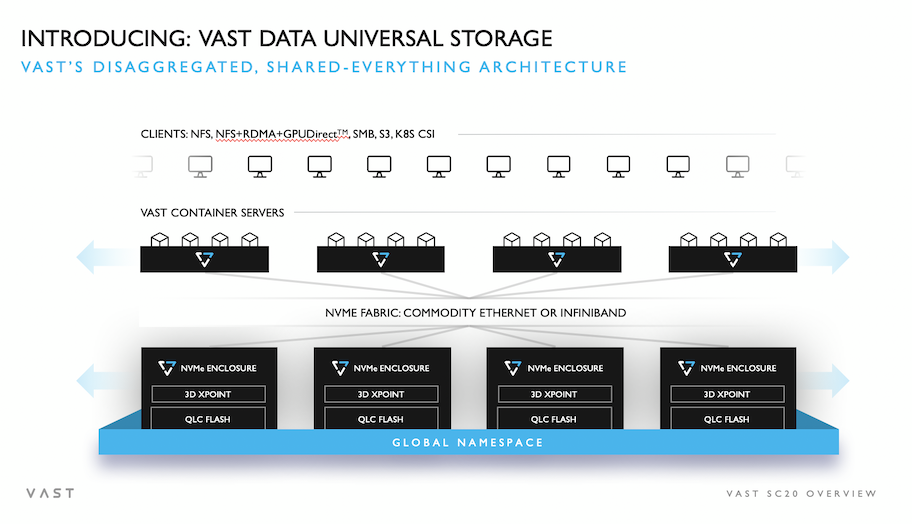
Jeff Denworth: The parallel file system companies are saying, you know, this [product] is x times faster than NFS. And that [product] is y times faster than NFS. But we were using NFS and were able to get for a single DGX A100, the fastest performance that Nvidia has seen. And so why do we take the path of building an enterprise NAS product as opposed to building a parallel file system out of this technology? Well, the first principle of VAST is that we want this to be broadly applicable. And NAS has always been much simpler to deploy, because you just get to use the capabilities that are in the host operating system; you don’t have to install custom parallel file system software on a customer’s cluster, which basically conflates their operating system strategy with their storage agenda because now those two are intertwined.
This is a level of complexity, we never wanted our customers to get to and we just want something that’s ubiquitous that any single application can consume. We made the decision to build a NAS, [and] we realized that there were a ton [of capabilities] in the kernel that could get NFS to a point where it could be, in our case, 90 times faster than what conventional TCP-based NFS has historically been. We call this the concept of Universal Storage, and it’s a product that you can use for everything from VMware to some of the largest distributed applications in the world. Whereas we don’t consider ourselves an HPC storage company, because the product is much more broadly applicable than just HPC storage has classically been, we make a very good storage product for HPC customers.
HPCwire: VAST touts the use of containers in its approach. How specifically does using containers help achieve the scale and performance goals?
Jeff Denworth: Containers, at their simplest level, provide two primary benefits for us. The first is that they are abstracted from the hardware. For example, you can upgrade your file server software without having to reboot your operating system. That in and of itself is such a liberation with respect to being able to build resilient infrastructure. But think of a more sophisticated environment where customers already got Kubernetes running within their environment. Imagine that there is no notion of a classic storage controller in your environment, but rather VAST is a microservice that runs within the environment and scales itself up and down dynamically. Based upon the needs of the application at any given time. This all becomes possible thanks to that abstraction.
Containers also buy you statelessness. What we built is a distributed systems architecture where there is absolutely no state within the controller code of our system. So every single CPU has some sort of Docker image running in it. Every Docker image has a global view to all of the state across the network on the NVMe fabric that we build on. Once you get there, that means that no two containers need to talk to each other at all, because they’re not coordinating any operation that’s happening within them. All of the data is being essentially journaled and articulated down in XPoint on the other side of the network.
Once you have stateless distributed storage systems, you can get to linear scalability. That’s one of the reasons that some of the larger customers in the space like our product, because every time you add a CPU, it becomes a linear unit of performance scale. Take any shared nothing cluster in the marketplace today, where the CPU owns some of the state of the file system, and every time there’s an update to one device within that machine, that update has to be propagated or broadcast out onto the network to all of the other machines. That creates cross talk that ultimately limits scalability.
We’ve sat down with some executives in the AI space, and they say, ‘Tell us how you can be as scalable as something like a parallel file system.’ And we have to say, ‘No, you have to understand this architecture is more scalable than a parallel file system [because] there is zero bottlenecks within the system.’ It’s basically just a large array of XPoint drives and flash drives, and an independent array of shared-everything loosely-coupled containers.
HPCwire: Does the use of persistent memory constrain you to using the Intel interface?
Jeff Denworth: We don’t use [Intel] persistent memory, actually, we use the XPoint, 2.5-inch drives, so there is no CPU, it just presents itself as a block device over NVMe fabrics to the machine. There’s no CPU dependency whatsoever.
HPCwire: How are you able to keep the system costs down. That’s a central part of the VAST Data pitch and flash is still not cheap.
Jeff Denworth: You could argue [there are] four ways we’ve done it. The first is, from the onset, we basically made a decision to support the lowest grade flash that that we can, at any given time, consume. A little-known fact about VAST, when we started, is a lot of our early systems and prototypes that we were shipping were built off laptop flash. Since then, we’ve evolved to ship enterprise grade data center grade QLC drives. The only reason that we’re using QLC drives as opposed to laptop flash is QLC is cheaper than the TLC laptop flash drives you could buy, [and] you get one SSD controller chip per 15 terabytes versus two terabytes. From a manufacturing cost, it’s more effective. QLC has the property of being by far the least expensive way that you can consume flash right now and we wanted to start from a basis of working with the lowest cost componentry.
[Doing] that requires an entirely different global storage controller architecture, to be able to drive to QLC flash in a way where it won’t wear down prematurely. We have to, in essence, shape writes through a form of log structuring. We take advantage of the fact that the system understands the long-term life expectancy of data as a file system. So we place data into flash blocks according to their life expectancy. And we never co-mingle long-term and short-term data within the same block. So we never have to do brute force garbage collection through the process. With this [approach], we get about 20 times the stated endurance out of these drives than when Intel first announced them and that allows us to put systems on the floor for up to a decade. If you can put flash on the floor for up to a decade, then you don’t worry about the same performance considerations that you did for hard drive-based storage, because you basically have just an endless pool of IOPs at that point. We have customers such as NOAA that have placed orders for 10-year system deployments from us.
The second thing we do is a new type of erasure code. This erasure code is also intended to break a [traditional] tradeoff. That’s a tradeoff between the overhead that you pay to protect against data loss and the resilience that you get from a system in the event of protecting yourself from data loss. We call them locally decodable codes, and the big invention here is we’ve reduced the time to rebuild and increased the number of redundancies you have in a write stripe. And because we write everything into 3D XPoint, the system has the luxury of time to build really fat write stripes. Then when they get moved down into flash at scale, you’re writing at 146-plus-four raid stripes. At 146-plus-four, you’re paying two and a half percent for your data protection overhead. At the same time, because we’ve got up to four redundancies and we’ve reduced the rebuild times, what you get out of it is 60 million years of meantime to data loss, which is also unprecedented.
HPCwire: You’d mentioned data reduction as another key.
Jeff Denworth: Yes, the third and the final thing we did is what I alluded to earlier about putting data into small pieces. It’s a new form of data reduction that we call similarity-based data reduction. The market has always known that flash gives you the ability to do more fine-grained deduplication and compression and that was great because you could reduce down a database or some virtual machines. When we started, it was our investors that actually said, ‘You know, you can’t do the same things with file and object data, just so you know, it’s already pre-reduced. All the work has been done there, there’s nothing to be gained.’ So we started looking at the nature of data. If you just take two log files, for example, even if they’re pre-compressed, you’ve got timestamps that are interwoven between these different log files on different days. All of this stuff is common across the files, but there’s enough entropy that’s woven across the data such that it would trip up a classic deduplication approach.
What we did is we basically tried to combine the best of both deduplication and compression. The way the system works is your data is written into the system and hits that XPoint buffer untransformed. Your application gets an acknowledgment back that the writes have been completed instantaneously, so you’re basically writing at XPoint speeds. In the background, what we do is we start to run a hashing algorithm against the data just like the backup appliance would work. But a backup appliance will use a SHA 256 hash and say, ‘Okay, if this exact block exists elsewhere in the system, just create a pointer for this new one and don’t store it twice.’
![]() That’s not how our approach works at all. What we are doing is basically a distance calculation; we’re measuring the relative distance between a new block that’s hit the system, and all of the other blocks that are already in the cluster. Once we find that two blocks are close enough to each other, they don’t have to be exactly the same, we start to compress them against each other using a compression algorithm that comes from Facebook called z standard. So compression goes down to byte granularity, which means that we’re basically doing Delta compression and just removing the random bytes and storing those as deltas after the fact.
That’s not how our approach works at all. What we are doing is basically a distance calculation; we’re measuring the relative distance between a new block that’s hit the system, and all of the other blocks that are already in the cluster. Once we find that two blocks are close enough to each other, they don’t have to be exactly the same, we start to compress them against each other using a compression algorithm that comes from Facebook called z standard. So compression goes down to byte granularity, which means that we’re basically doing Delta compression and just removing the random bytes and storing those as deltas after the fact.
If you’ve ever used, for example, Google image search, and you upload a photo, and say, ‘Okay, show me everything that’s like that,’ the principles of our similarity-based data reduction were pretty much the same. What we’re doing is we’re measuring the distance and once we find that stuff looks close enough to each other, then we start using a much more fine-grained data reduction approach than deduplication. The compression has some awesome advantages. For example, Lawrence Livermore right now is [getting] three-to-one data reduction. We’ve got customers that take backup software that already has deduplication and compression, then store those backups down into VAST as a target after they’ve been reduced and the VAST system will be able to reduce them by another three-to-one or to six-to-one data reduction, because we’re much more fine-grained.
HPCwire: So boil it all down for me.
Jeff Denworth: Okay. If you take your QLC, and you can extend [its] lifespan to 10 years, and then you add almost no overhead for data protection, and you amplify the system capacity through data reduction – those four things get you to a price point that is not [just] on a TCO basis superior to what you’re buying today, but on a total cost of acquisition basis. That’s how we are introducing entirely new flash economics.
Typically, we don’t sell systems of less than a petabyte. And the reason for that is the flash that we’re using was never intended to be a 10-terabyte system designed for a database to overwrite its logs every 24 hours. We’re building a system that is intended to essentially blur the lines between a capacity tier and performance tier, such that we can amortize the endurance of your applications across all of your flash investment. So a petabyte is basically the barrier today.
HPCwire: Could you briefly describe your target market?
Jeff Denworth: If you look at our customer base, it’s largely concentrated from a number of different industries where you have very high concentrations of performance and data. Our number one segment is financial services. This is everything from hedge funds to market makers to banks. We have one public reference in the space that came in April, it’s a company called Squarepoint Capital. They rolled out of Barclays some years ago. The genomics space probably rivals financial services as our other big target segment. We’ve sold to all of the major ASC labs within the Department of Energy. We’ve also got customers in the intelligence community around the world, we’ve got customers doing manufacturing, things like electric cars and autonomous vehicles. We have several customers in the web scale space and we have AI as a horizontal practice that cuts across all the markets that we work in.
This article first appeared on sister website HPCwire.






