



Intel Debuts Stratix 10 NX FPGAs Targeting AI Workloads

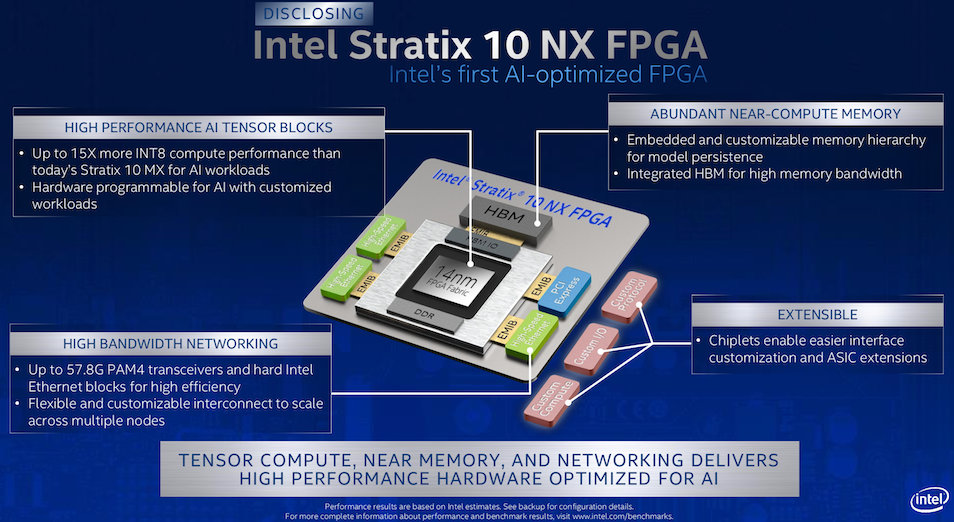
Intel today introduced its first AI-optimized FPGA – the Stratix 10 NX – which features expanded AI Tensor blocks (30 multipliers and 30 accumulators), integrated HBM memory, and high bandwidth networking. The new chip continues leveraging Intel’s chiplet architecture and the FPGA portion of the chip is fabbed using Intel’s 14nm technology.
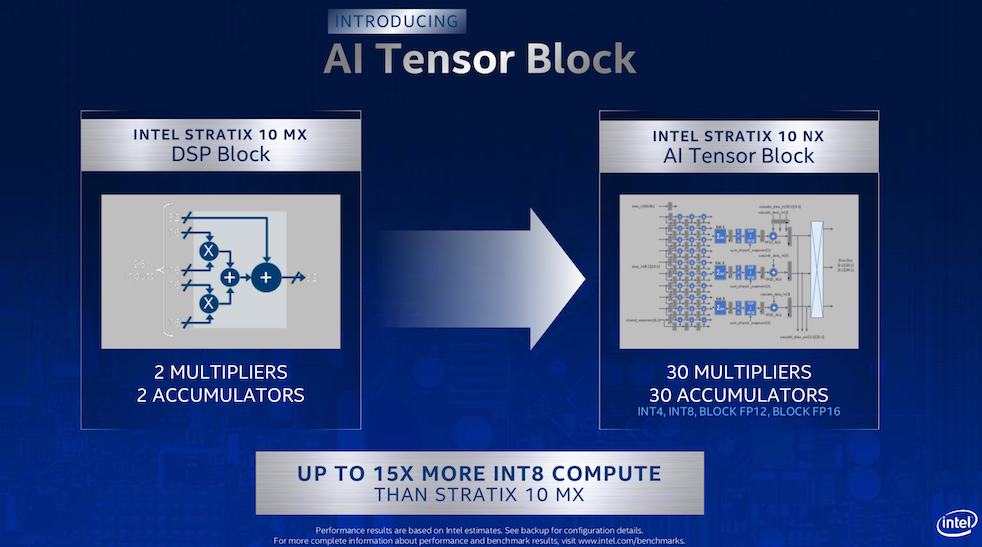
Intel reports the new FPGA will deliver up to 15X more INT8 compute than the Stratix 10 MX, which was introduced in late 2017 and whose DSP block only had two multipliers and two accumulators. The new chip also features “up to 57.8 Gig PAM4 transceivers and hard Intel Ethernet blocks for high efficiency.” The Stratix 10 NX will be available later this year, according to Intel.
“The most disruptive trend that has emerged is the exponential increase in AI model size and complexity,” said David Moore, corporate VP, GM, programmable solutions group, Data Platforms Group, Intel, in a media pre-briefing. “What we’re seeing is AI model complexity is doubling about every three and a half months or 10x per year. So [it’s] heading to 10s of billions of parameters and beyond in the largest and next generation transformer models such as BERT and GPT.”
“Our current (MX) compute block is really designed for general purpose compute. So a broad level of flexibility to meet demanding requirements across a range of signal processing applications, operations, and precision [requirements]. The design of the AI tensor block is focused on accelerating AI applications, optimizing for efficient tensor pipelines and reduced precision, integer and floating point formats commonly used in the AI space. These innovations allow us to pack 15X more compute into the same footprint as our standard DSP compute block,” said Moore.

FPGAs are expected to play a growing role as lower-cost, high-performance devices in more specialized application niches. Among FPGA’s advantages are the ability to implement low latency processing and to reduce costs associated with unused silicon in general purpose CPUs. Long dogged by a reputation for being difficult to program/develop, newer tools are making FPGA development somewhat easier. The hope that FPGAs would lead to more generally reconfigurable systems has so far not materialized.
“We typically see FPGAs differentiate in real-time, low-batch applications. So the FPGAs flexibility and configurable memory hierarchy enables developers to really customize their designs to create optimized low latency solutions,” said Moore who cited fraud detection and video data ingest in smart city applications as examples.
Taking aim at Nvidia, Intel says its Stratix 10 NX device is up to 2.3X faster than Nvidia V100 GPUs for BERT batch processing, 9.5X faster in LSTM batch processing, and 3.8X faster in ResNet50 batch processing. (See slide below)
The swing towards heterogeneous architecture is now in full force at Intel. Moore said, “Clearly, the Xeon, AI, and FPGA developer communities are coming together to solve heterogeneous compute challenges. Our focus includes not only the tools for hardware and software integration, but also the integration of those tools from standard libraries and frameworks to seamlessly support application development.”
Intel is betting big on oneAPI – the standards-based, unified programming model it is championing – to facilitate integration of heterogeneous Xeon platforms with various accelerators such as FPGAs.

Asked about how the NX differs from MX and how it relates to Intel’s FPGA development work done with Microsoft’s Project Brainwave*, Moore, described the NX as an evolution from the MX and Microsoft work rather than being starkly different.
Intel has, of course, acquired several accelerator companies and technologies in recent years including most recently Habana Labs.
Asked about plans for Habana during the briefing, Lisa Spelman, Intel corporate vice president and general manager, Xeon and Memory Group, said, “Habana is focused on the AI training or inference workload. Our math and our TCO calculations shows when you look at a workload flow, if the AI becomes a [high enough] percentage of the workload, your economics can improve by moving to acceleration or dedicated acceleration, complementing [the] underlying processor. [It] has to do on the size of the workload, the amount of data that you’re trying to handle through your training function or inference, and then the flow of the workloads.
“There are certain ones like, again I mentioned recommender systems, because the flow of the workload and the way that the inference is built into the response, the CPU is actually a very natural and most likely spot for those workloads to land. If you think [of others], potentially image processing in a very specific training environment, an accelerator like Habana dedicated to the task at hand could turn out to be the best total cost of ownership model even though it’s used for a narrower portion of the problem.”

* Microsoft Project Brainwave:
“Project Brainwave is a deep learning platform for real-time AI inference in the cloud and on the edge. A soft Neural Processing Unit (NPU), based on a high-performance field-programmable gate array (FPGA), accelerates deep neural network (DNN) inferencing, with applications in computer vision and natural language processing. Project Brainwave is transforming computing by augmenting CPUs with an interconnected and configurable compute layer composed of programmable silicon.
“For example, this FPGA configuration achieved more than an order of magnitude improvement in latency and throughput on RNNs for Bing, with no batching. By delivering real-time AI and ultra-low latency without batching required, software overhead and complexity are reduced.” https://www.microsoft.com/en-us/research/project/project-brainwave/






