



At SC19: Intel Debuts GPU and Outlines oneAPI Aspirations

Last night at Intel's HPC Developer Conference here at the SC19 conference in Denver, the company revealed a few more details about its forthcoming Xe line of GPUs – the top SKU is named Ponte Vecchio and will be the first planned U.S. exascale computer, "Aurora," whose basic node will feature two Xeons and six Ponte Vecchios. Intel also took time to dig deeper into its oneAPI effort, now in “beta launch” and positioned as both an industry initiative and a product intended to enhance development for heterogeneous compute architectures.
At a pre-briefing of the announcements last week, Raj Hazra, Intel VP/GM for enterprise and govenment, fleshed out the company's vision for converged HPC-AI and described Intel’s developing “XPU” strategy that embraces CPUs, GPUs, FPGAs, NNP (neural net processors), and other accelerators as necessary elements for advancing computing on all fronts from high-end HPC to small power hungry edge devices.
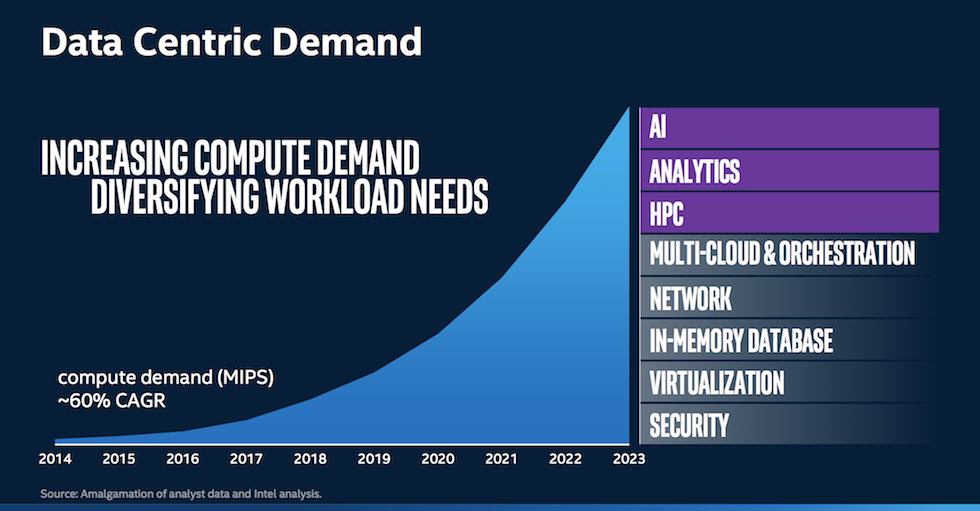
“No longer [does] one size fit all,” said Hazra. “We have to look at architectures tuned to the needs of varying kinds of workloads in this convergence era.” Citing a 60 percent CAGR for MIPS, Hazra said Intel now needed “a portfolio of architectures” to address compute needs, which he labelled as Intel’s XPU approach.
 Relatively few technical details about the Xe were discussed. It will use Intel’s new 7nm process technology, Foveros multi-die packaging, and be ready to use Intel-backed CXL interconnect technology. Ari Rauch, Intel GM visual technology team and graphics business, was coy when asked if Ponte Vecchio would use Intel’s nascent EMIB (embedded multi connect bridge) technology. “We’re not disclosing [that] but you can assume the device is taking into advantage all the latest and greatest technology from Intel …3D packaging, memory technology, they’re all in play.” Later at the DevCon, Intel confirmed the use of EMIB.
Relatively few technical details about the Xe were discussed. It will use Intel’s new 7nm process technology, Foveros multi-die packaging, and be ready to use Intel-backed CXL interconnect technology. Ari Rauch, Intel GM visual technology team and graphics business, was coy when asked if Ponte Vecchio would use Intel’s nascent EMIB (embedded multi connect bridge) technology. “We’re not disclosing [that] but you can assume the device is taking into advantage all the latest and greatest technology from Intel …3D packaging, memory technology, they’re all in play.” Later at the DevCon, Intel confirmed the use of EMIB.
He did say Intel was focused on having a common over-arching architecture and common programming model across the Xe line, but in the context of also delivering ‘microarchitectures’ targeting specific workloads. One can imagine a variety of memory, IO, and mixed precision, and power consumption attributes delivered in members of the Xeline. The first Ponte Vecchio devices to market will presumably be in Aurora which is due in 2021. Intel confirmed it planned to sell Xe GPUs as standalone products although with few details and no firm timeline. In fact, the first-to-market Xe device will appear in 2020 and be in a consumer setting according to Intel.

 Intel was likewise scant with new details about Aurora which will be located at Argonne National Laboratory. Hazra reiterated Aurora would have more than 200 racks, 230 petabytes of storage, and more than 10 petabytes of memory. The two CPUs on each node will be Sapphire Rapids generation Xeons connected to six Ponte Vecchios and be programmed with Intel’s oneAPI stack.
Intel was likewise scant with new details about Aurora which will be located at Argonne National Laboratory. Hazra reiterated Aurora would have more than 200 racks, 230 petabytes of storage, and more than 10 petabytes of memory. The two CPUs on each node will be Sapphire Rapids generation Xeons connected to six Ponte Vecchios and be programmed with Intel’s oneAPI stack.
When asked, Raj declined to say what the rack type would be or to specify the ratio of DDR5 to Optane memory planned. “We will be taking the covers off gradually over the next few months, and we will get to those levels of specific configuration details at that point,” he said. (Interestingly, from a macro level an Aurora node looks a lot like a Summit node – of course the devil is in the details.)
Bill Savage, GM for compute performance and developer products, provided a fair amount of detail around oneAPI which is now available on Intel’s DevCloud. Intel describes oneAPI as a unified programming model to simplify development across diverse architectures.
Savage noted developers generally rely on abstractions to get access to hardware through middleware and frameworks, and in the case of HPC, by coding more closely and directly to the hardware. Targeting new architectures typically requires low level programming and sometimes different programming languages and libraries. The same can said for middleware and frameworks often optimized for specific hardware. Savage pointed to TensorFlow which when first released was “optimized for one vendor’s GPU” and not for anything else.”
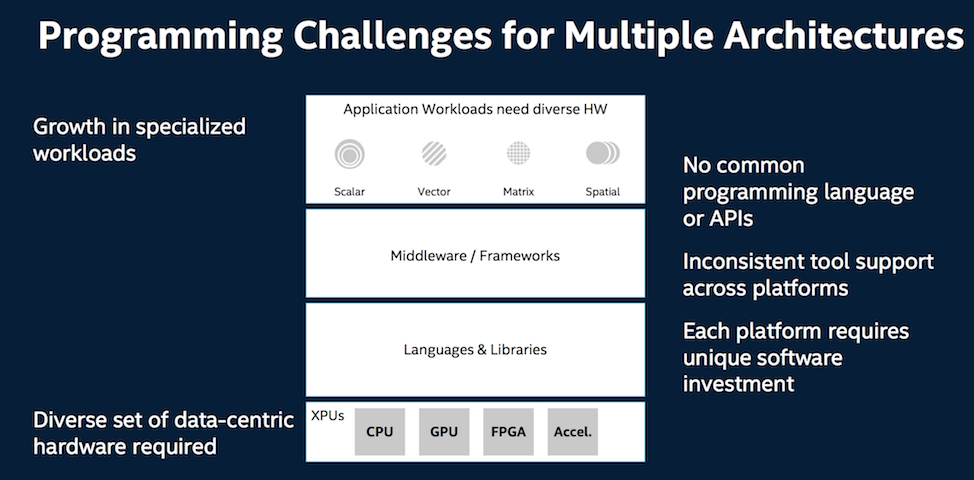 The oneAPI vision is expansive. It would offer a “low level common interface to heterogeneous hardware so that HPC developers can code directly to the hardware, through languages and libraries that are shared across architectures and across vendors as well as making sure that middleware and frameworks are powered by one API and fully optimized for the developers that live on top of abstractions.” That seems a worthy idea but a tall order.
The oneAPI vision is expansive. It would offer a “low level common interface to heterogeneous hardware so that HPC developers can code directly to the hardware, through languages and libraries that are shared across architectures and across vendors as well as making sure that middleware and frameworks are powered by one API and fully optimized for the developers that live on top of abstractions.” That seems a worthy idea but a tall order.
 Here is Savage on oneAPI and on the decision to create Data Parallel C++ (DPC++) as the base language:
Here is Savage on oneAPI and on the decision to create Data Parallel C++ (DPC++) as the base language:
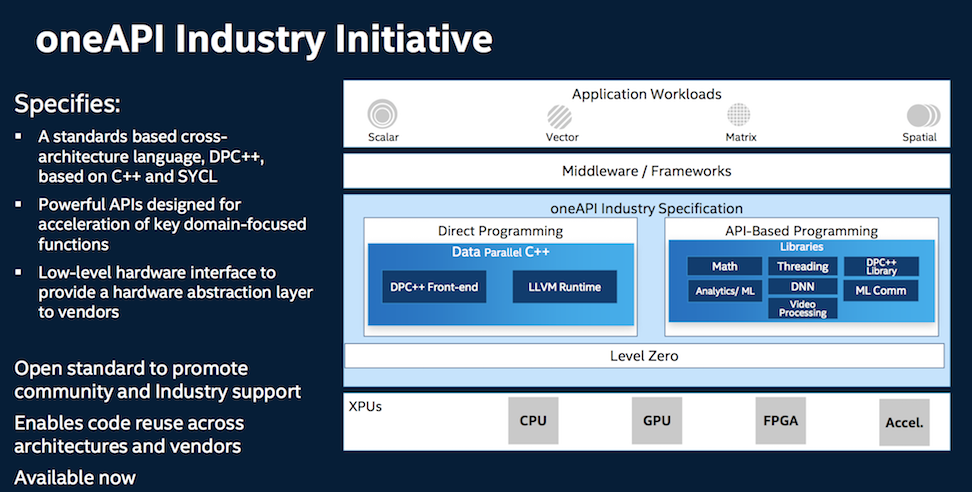
“It is both an industry initiative and an Intel product. [The] industry initiative is driving an open standard with an open source reference implementation with partners in the industry. [By doing this] we can share and reuse source code across architectures and vendors.
“We looked closely at OpenCL, Java and other languages, and how they had compromises in performance or delivered reuse of software. [We] selected a language that could deliver both the productivity and performance. It’s C++ based but has we’ve applied a number extensions to make it more usable, and developer friendly as well as deliver better performance. Then we added a set of APIs for low level libraries to offer a common set of capabilities across the domains of HPC and AI, as well as other domains at the low level. So those are parts of the standard.”
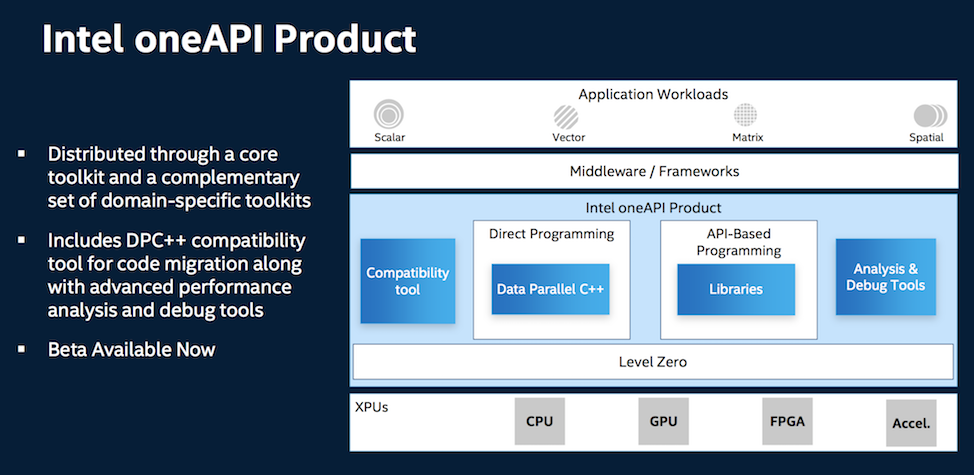
 The Intel oneAPI product has a few additional features including a compatibility tool and some analysis and debug tools.
The Intel oneAPI product has a few additional features including a compatibility tool and some analysis and debug tools.
“We have an implementation of the data parallel C++ compiler as well as the set of libraries that match the APIs in the specification. So that’s the core of the Intel one API product. In addition, we took our analysis tools like the VTune Inspector/Advisor, and we’ve enabled those for one API as well debugging and supporting tools,” said Savage.
Intel also developed compatibility tool to aid in source code migration such as Cuda to DPC++. “We get the source in our data parallel C++ that can cross architecture and vendor boundaries and you should get good performance in the first port,” said Savage. He expects tuning for specific microarchitectures will be required to achieve optimum performance.
 A big question is who is supporting the effort. At the media pre-briefing Intel promised more information on partners and organization of the initiative would be forthcoming during its developer conference now underway.
A big question is who is supporting the effort. At the media pre-briefing Intel promised more information on partners and organization of the initiative would be forthcoming during its developer conference now underway.
Lastly, lest you think the venerable Xeon is being lost in the shuffle of Intel’s emerging XPUs approach, Hazra called it the workhorse of Intel’s converged HPC/AI strategy. As shown below nothing really new about Intel’s CPU roadmap was presented but Hazra emphasized previously discussed plans particularly the addition of mixed-precision capabilities in forthcoming generations.
“We’re shipping our Cascade Lake 14 nanometer processor today with Intel DL Boost, which is also called VNNI (vector neural net instructions), and [it’s] enabled with Optane Datacenter Persistent Memory first generation. That beat continues in 2020 as we introduce Cooper Lake with the next generation of DL Boost and specifically bringing bfloat16, the industry’s converged reduced precision, numeric format for AI into the processor for the first time.”
 The 10nm Ice Lake ramp-up continues in the second half of 2020 and will provide more microarchitecture and architectural features for both traditional HPC and AI, said Hazra. Sapphire Rapids, of course, is due in 2021 in time for Aurora. Hazra said little about it beyond it would have impressive scale-out and scale-up performance.
The 10nm Ice Lake ramp-up continues in the second half of 2020 and will provide more microarchitecture and architectural features for both traditional HPC and AI, said Hazra. Sapphire Rapids, of course, is due in 2021 in time for Aurora. Hazra said little about it beyond it would have impressive scale-out and scale-up performance.
This article originally appeared in sister publication HPCwire.






