



Intel AI Summit: New ‘Keem Bay’ Edge VPU, AI Product Roadmap

Intel's Naveen Rao
At its AI Summit today in San Francisco, Intel touted a raft of AI training and inference hardware for deployments ranging from cloud to edge and designed to support organizations at various points of their AI journeys.
The company revealed its Movidius Myriad Vision Processing Unit (VPU), codenamed “Keem Bay,” for edge media, computer vision and inference applications. The company said the VPU, available the first half of 2020, incorporates “highly efficient architectural advances” and will deliver more than 10 times the inference performance of current Movidius VPUs and up to six times the power efficiency of competitor processors. Intel claimed that “early performance testing indicates that Keem Bay will offer more than 4x the inference throughput of Nvidia’s similar-range TX2 SOC at one third less power, and nearly equivalent throughput of Nvidia’s next higher class SOC, Nvidia Xavier, at one fifth the power. Keem Bay measures 72mm2 size compared with Nvidia Xavier’s 350mm, according to Intel.
Keem Bay will also be supported by Intel’s OpenVINO Toolkit for development of computer vision applications – “addresses a key pain point for developers — allowing them to try, prototype and test AI solutions on a broad range of Intel processors before they buy hardware,” according to Intel. It also will be incorporated into Intel’s newly announced Dev Cloud for the Edge, launched today, designed to allow developers to test algorithms on any Intel hardware.
Intel also offered the first live demonstrations and additional architectural details of its Nervana Neural Network Processors for training (NNP-T1000) and inference (NNP-I1000) ASICS for cloud and data center environments, first announced last August at the Hot Chips conference.
 In discussing the company's AI products roadmap (see above), Naveen Rao, corporate VP/GM of Intel’s AI Products Group, said the combination of “the new Intel hardware will enable the industry to embrace much larger and more complex AI algorithms, expanding what can be achieved with AI in the cloud and data center, an edge server, or an IoT device.”
In discussing the company's AI products roadmap (see above), Naveen Rao, corporate VP/GM of Intel’s AI Products Group, said the combination of “the new Intel hardware will enable the industry to embrace much larger and more complex AI algorithms, expanding what can be achieved with AI in the cloud and data center, an edge server, or an IoT device.”
“With this next phase of AI, we’re reaching a breaking point in terms of computational hardware and memory,” said Rao. “Purpose-built hardware like Intel Nervana NNPs and Movidius Myriad VPUs are necessary to continue the incredible progress in AI. Using more advanced forms of system-level AI will help us move from the conversion of data into information toward the transformation of information into knowledge.”
Rao announced that Intel expects to generate more than $3.5 billion in AI revenue this year. He touted the company’s systems-level AI product portfolio, developed with open components and deep learning framework integration and ranging across different ranges of need, sophistication and scale.
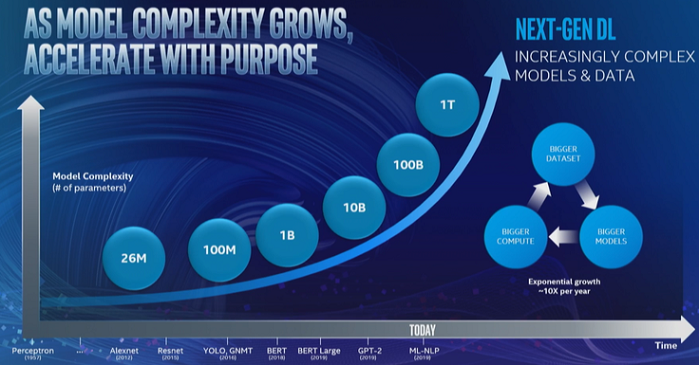 “While most enterprises are only getting started on their AI journey with smaller models that typically do not require acceleration,” he said, “AI super users – generally CSPs (cloud services providers) – are embracing next-gen AI models with billions or trillions of parameters that require new approaches to AI acceleration. Intel has a unique position and perspective on AI, with a comprehensive edge-to-cloud product portfolio that makes a wide breadth of AI solutions possible: from smart IoT edge devices to classic enterprise machine learning to next-generation deep learning for true AI super-users. This last group are developing the next generation of models that will move us from more basic intelligence to algorithms capable of using reasoning and context to make decisions and scale knowledge.”
“While most enterprises are only getting started on their AI journey with smaller models that typically do not require acceleration,” he said, “AI super users – generally CSPs (cloud services providers) – are embracing next-gen AI models with billions or trillions of parameters that require new approaches to AI acceleration. Intel has a unique position and perspective on AI, with a comprehensive edge-to-cloud product portfolio that makes a wide breadth of AI solutions possible: from smart IoT edge devices to classic enterprise machine learning to next-generation deep learning for true AI super-users. This last group are developing the next generation of models that will move us from more basic intelligence to algorithms capable of using reasoning and context to make decisions and scale knowledge.”
He added that the pressure on chip vendors to keep pace with rising training and inference processing demands is intense.
"This next wave of AI requires huge increases in data and model complexity, some with trillions of potential parameters," he said. "Training these cutting-edge algorithms requires demand for AI compute to double about every 3.5 months, which cannot be accomplished efficiently with today’s architectures. These AI breakthroughs require new architectures that are specifically designed for high-speed, mass-scale AI compute."
Rao said Nervana NNP-T targets high end AI customers, such as Baidu, and “carefully balances compute, memory and interconnect near-linear scaling.” He said it achieves up to 95 percent scaling with Resnet-50 convolutional neural network for image recognition training and the BERT natural language processing training model. “As a highly energy-efficient compute platform for training real-world deep learning applications, NNP-T ensures no loss in communications bandwidth when moving from an eight-card in-chassis system to a 32-card cross-chassis system, with the same data rate on 8 or 32 cards for large message sizes, scaling well beyond 32 cards,” he said.
Nervana NNP-I, meanwhile, “is power- and budget-efficient and ideal for running intense, multimodal inference at real-world scale using flexible form factors,” Rao said. In its M.2 form factor, NNP-I draws 12W and generates up to 50 TOPs; as a PCIe card drawing 75W it produces up to 170 TOPs, according to the company.






