



AWS Upgrades Nvidia GPU Cloud Instances for Inferencing, Graphics

Graphics processor acceleration in the form of G4 cloud instances have been unleashed by Amazon Web Services for machine learning applications.
AWS (NASDAQ: AMZN) on Friday (Sept. 20) announced general availability of the new Elastic Compute Cloud instance providing access to Nvidia’s (NASDAQ: NVDA) T4 Tensor Core GPUs, which are based on the Turing architecture. The EC2 instances are available in the public cloud provider’s North American, Asian and European regions.
The instances are available in six sizes:
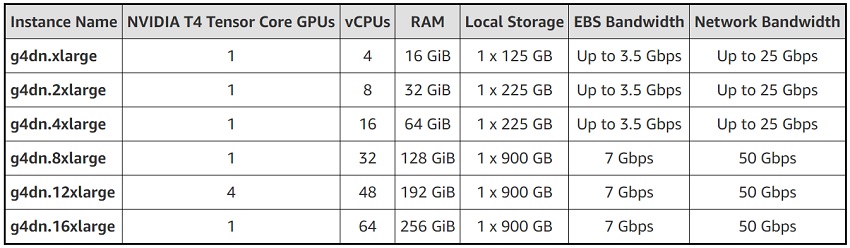 AWS is also working on a bare metal instance (g4dn.metal) with eight GPUs and 96 vCPUs, which it says will be available “in the coming months.” On demand pricing (in US East region) ranges from $0.526/hr for the g4dn.xlarge to $4.352 for the g4dn.16xlarge. Pricing for the bare metal instance has not been announced yet.
AWS is also working on a bare metal instance (g4dn.metal) with eight GPUs and 96 vCPUs, which it says will be available “in the coming months.” On demand pricing (in US East region) ranges from $0.526/hr for the g4dn.xlarge to $4.352 for the g4dn.16xlarge. Pricing for the bare metal instance has not been announced yet.
The partners said the new cloud GPUs would help accelerate machine learning inference and graphics-heavy workloads with up to 130 TOPS of INT8 performance. Inference applications benefitting from cloud-based GPUs include automated speech recognition, object detection and language translation.
Along with Nvidia GPU accelerators, the new G4 instances run second-generation Intel Xeon Scalable processors (Cascade Lake). The upgrade also includes up to 100 Gbps of networking bandwidth (on the bare metal version) and as much as 1.8 Tbytes of local storage supported by NVM Express connectivity, Amazon said.
Machine learning workloads can be launched on the G4 platform using Amazon’s Sagemaker machine/deep learning stack or other deep learning tools such as TensorFlow, PyTorch or Caffe2. The goal, the partners said, it to get GPU acceleration into the hands of more machine learning developers.
Nvidia said the accompanying G4 software platform incudes its cuDNN for deep learning and RAPIDS for data analytics and machine learning, among others.
The T4 is Nvidia’s second-generation Tensor Core GPU, following the Nvidia V100 Tensor Core GPUs, launched in 2017. While the V100 helps reduce model training from days to hours, AWS estimates inference tasks account for as much as 90 percent of overall costs for running machine learning workloads. Hence, the cloud provider asserts the new G4 instances would help reduce the hefty operational costs associated with machine learning inference.
Nvidia heralded the T4-backed instances as the first to offer its RTX ray tracing in the cloud. AWS said graphic applications running on the G4 instances also would benefit from video decode protocols. Support for the latest protocols would boost performance over G3 instances by about 1.8-2X at about the same cost, it added.
Rival cloud vendor Google also offers Nvidia T4 GPUs in its cloud; Google announced global availability back in April.






