



Intel Charges Spark Workloads with Optane Persistent Memory

Optane is Intel‘s latest storage innovation that blends the characteristics of fast but volatile RAM and slower but persistent NAND storage technology. Originally based on the 3D Xpoint technology that it started co-developing with Micron years ago, the storage-class memory technology was designed to provide a major boost in the ability of users to work with large data sets by providing the speed of DRAM but the capacity and persistence of NAND.
Intel already shipped an Optane product in the form of NVMe drive, and now it’s coming to market in the guise of Optane DCPMMs. Delivered as standard DIMMs, Optane DCPMMs plug right into the PCIe bus on industry-standard X86 servers. Those systems will, however, need to be running Cascade Lake processors, while the NVMe format was more flexible in system configurations. However, what the DCPMM lacks in flexibility it should make up in capability.
Intel is shipping DCPMMs in three sizes: 128GB, 256GB, and 512GB. Each DCPMM requires its own memory channel, and customers can load up to six DCPMM DIMMs in single socket. Users can co-locate DCPMMs next to DRAM, but they cannot use multiple sizes of DCPMMs.
This gives customers with a two-socket server the capability to have up to 6TB of memory per server, according Intel engineer Piotr Balcer, who spoke at Databricks‘ Spark + AI Summit 2019 recently. “Quite a lot of space for your whole data,” he said.
With multiple servers, DCPMM enables customers to store up to 1PB of data in 1U of a rack, Intel said.
Speeding Data with Optane
There are two modes supported with Optane DCPMM: App Direct mode and Memory Mode (there’s also Storage Over App Direct Mode).
Users who want to take advantage of Optane’s data persistence capabilities will need to choose App Direct mode, since the data is wiped clean during power shutdowns in Memory Mode, which is how traditional DRAM works. (But because DCPMMs are still cheaper than traditional DRAM DIMMs, Optane retains an advantage.)
Balcer and his Intel colleague Cheng Xu demonstrated how Spark users can get a performance boost during their Spark + AI Summit session, titled “Accelerate Your Apache Spark with Intel Optane DC Persistent Memory.”
“Persistent memory is exposed to the application through the file system,” Balcer said. “It uses the same normal interface as storage.” Currently DCPMM supports XFS, EXT4, and NTFS file systems, using those file systems’ block storage system calls to read and write data.
“It behaves like DRAM for access, so you can use normal load semantics, which means we don’t have to go through the kernel,” he said. “We don’t have to have that control point.”
To enable applications to directly access data and use normal load storage instructions, Intel developed something called DAX, which stands for direct access, Balcer said.
“Which means it allows the application to mount the persistent memory into the other space of the application, and bypass the page cache, because the page cache is what you traditionally will use when you use memory mounts,” he said. “Because we now have very, very fast memory, we don’t really need the page cache to amortize the block storage.”
Using the DAX layer, DCPMM enables users to mount persistent memory into the address space of the application and then use the load store instructions of the CPU, which is the fastest data path the application can take, Balcer said.
“What this ultimately means,” he continued, “is that the application can now store data persistently on storage yielding the load store instructions of the CPU, and that was never possible before. So there’s nothing in between the application and the storage. There’s no software. There’s no firmware. Well, there is firmware, but there’s nothing in the kernel space that interferes with the application performance.”
Spark on Optane
The performance benefits of DCPMM are directly applicable to Spark SQL and machine learning workloads that are either memory-bound or are burdened by large amounts of I/O, the Intel engineers told the Spark + AI audience.
 In App Direct Mode, DCPMM has the potential to move data at multiple tens of gigabytes per second with nanosecond latencies, compared to single-digit GB/s on throughput with microsecond latencies with fast NAND-based solid state disks, according to Lenovo’s handbook on DCPMM.
In App Direct Mode, DCPMM has the potential to move data at multiple tens of gigabytes per second with nanosecond latencies, compared to single-digit GB/s on throughput with microsecond latencies with fast NAND-based solid state disks, according to Lenovo’s handbook on DCPMM.
However, achieving those rates requires users to specially configure their DCPMM setup, Lenovo states. “If an application hasn’t been modified to support App Direct Mode, it can utilize DCPMM in Storage over App Direct Mode operation, which is a more conventional setup using a supported DAX model in the operating system,” the vendor writes.
Intel has addressed this requirement by developing special software that allows Spark users to take full advantage of the DCPMM capabilities, without modifying their Spark machine learning or SQL applications.
Intel’s Spark on DCPMM stack consists of several layers, including a DAX file system interface discussed above, Intel’s native DCPMM library dubbed VMEMCACHE, and OAP, or the Open Analytics Packager.
The Scala-based OAP contains several elements that make it easy for Spark users to take advantage of DCPMM with their SQL and machine learning workloads, According to Xu.
“Today Spark is running very fast and very easy for the user to use. But sometimes a customer may be facing a memory issue,” Xu said. “We hear a lot of customer complaining about memory usage, so that sometimes they try to config the memory for specific workload, but when they try to run another workload, they run into other issues.”
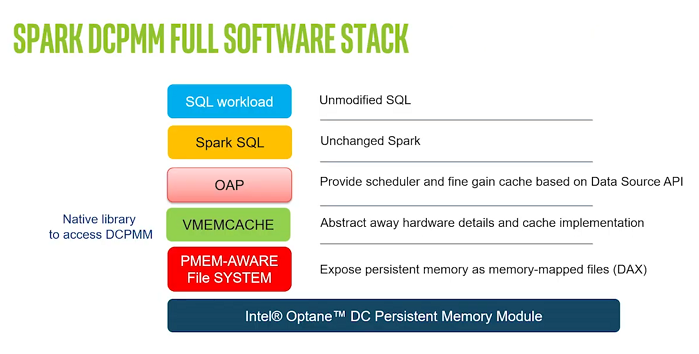 Optimizing Spark’s usage of memory is one of the goals of OAP, which is a free and open source piece of software that users can obtain at Github. OAP levaerges DCPMM to bring three key capabilities to Spark users, including a front-end I/O cache, a cache-aware scheduler, and self-management of off-heap memory.
Optimizing Spark’s usage of memory is one of the goals of OAP, which is a free and open source piece of software that users can obtain at Github. OAP levaerges DCPMM to bring three key capabilities to Spark users, including a front-end I/O cache, a cache-aware scheduler, and self-management of off-heap memory.
The I/O cache will be especially useful for Spark SQL and machine learning users who are pulling data from slower data stores, including on-premise hard disk drives and also from remote BLOB stores, such as Azure ALDS or Amazon S3, Xu said.
“For example, you have a table ABC, but for your workload, you just access the first column A,” Xu said. “In our implementation, we just cache column A because column A is hotter data compared to the rest of the columns.”
The I/O cache will also help machine learning use cases on Spark, Xu said, particularly for algorithms with an interactive nature, such as Kmeans. “Now we have a very large capacity of memory, so you can put the entire data set into the Optane persistent memory, so you can achieve even better performance than the previous tiered storage design,” he said.
OAP’s cache-aware scheduler will also boost performance for Spark users by optimizing workloads according to data locality, Xu said. The cache-aware scheduler is based on Apache Spark version 2.0 APIs, he added. Lastly, better management of off-heap memory will also boost Spark application, Xu said.
You can access the Intel employees’ recorded Spark + AI Summit session here.
This article originally appeared at sister publication Datanami.






