



The Rise of AI Hardware: Overcoming the AI Compute Bottleneck Sponsored Content by AI Hardware Summit
There is little doubt that AI hardware is a focal point this year for tech industrialists, computer scientists, AI researchers and governments alike, after a Cambrian explosion of new hardware precipitated by a sudden and huge demand for computational power coinciding with an impending transformation of the existing computing paradigm. The landscape of the technology industry, and the fundamental way in which computing is done, will almost certainly look very different a decade from now, due in no small part to AI hardware, and the $65bn+ opportunity of this market.
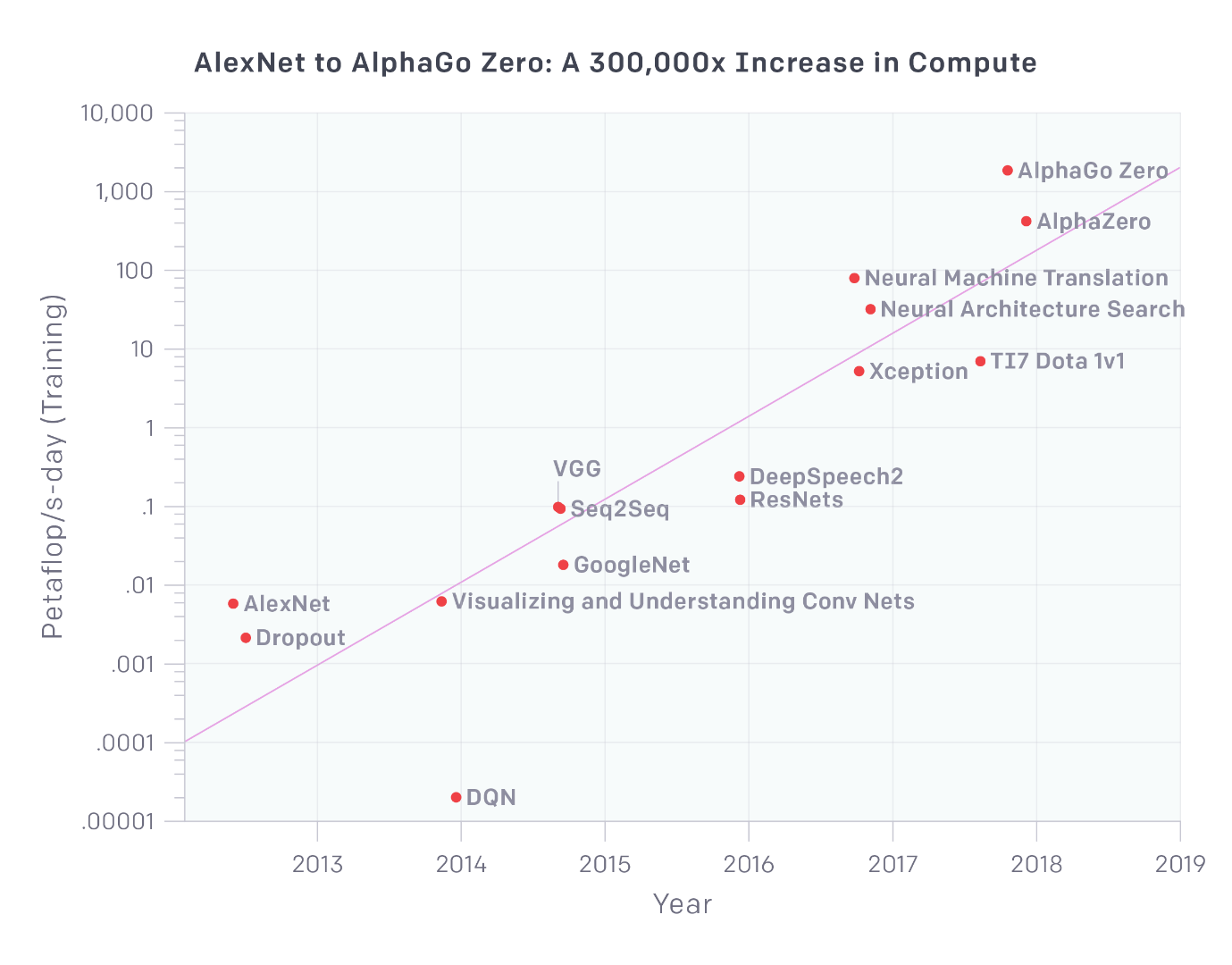
OpenAI’s ‘AI and Compute’ article from May 2018 showed that AI compute required for the largest training runs is roughly doubling every 3.5 months. In a fireside chat with Satya Nadella, OpenAI CEO, Sam Altman attributed this to an observation that “increasing the size of the largest models that we can train, keeps letting us solve seemingly impossible tasks. So we’ve been increasingly hungry for larger and larger neural networks, that we can train faster and faster.”
MLPerf’s recent publication of Google and NVIDIA’s AI training benchmark results demonstrated how far AI hardware has already come, in some areas at least. Both companies demonstrated staggering performance improvements over previous hardware generations, with NVIDIA’s DGX SuperPOD completing a ResNet-50 model training run in 80 seconds, 0.3% of the time that the original NVIDIA DGX-1 server from 2017 took to train the same model. Google’s results were similarly impressive, as results showed that Cloud TPU v3 Pods train models over 84% faster than the fastest on-premises systems in the MLPerf Closed Division.
Meanwhile, in the start-up world, there now exists such a bewildering array of challenger companies, at various stages of product development, it is almost futile for customers to try to keep tabs of the availability of newer solutions in real time. Complicating matters further are factors such as the immaturity of standardized industry benchmarks for performance, the lack of clarity around software support, and significant challenges around flexibility, resilience and scalability of new AI hardware.
An outstanding question concerns how, and to what extent, custom AI silicon will be consumed by enterprises. Intel Corporate Vice President & Head of the AI Products Group, Naveen Rao, shared his perspective on the potential ROI of AI hardware with us:
“We like to use the phrase “accelerate with purpose,” because for many customers, running their training on CPUs simply provides a faster path to getting started, and better ROI by utilizing excess capacity within their existing infrastructure. But there are definitely industries and applications where accelerating with AI-specific hardware is a key advantage. For training, it really depends on the speed and recurrence with which you need to train your model. For inference, applications like Facebook’s algorithms reflect the type of intensive, continuous, high-volume and mission-critical tensor compute where offloading a portion of the process to AI-specific hardware will be the right play for total cost of ownership.”
There is still some way to go before compute stops being a bottleneck to the exponential scaling of AI capabilities, but there is much reason for optimism.
On September 17 – 18, the AI Hardware Summit, Mt. View, gathers the leading minds in hardware, including Alphabet Chairman John Hennessy who will take to the stage, alongside hyperscalers and enterprise end users of AI hardware, to unpack some of the challenges of deploying new silicon and systems for AI processing. Last year’s event witnessed the launch of Habana Labs and the event guarantees more industry-defining announcements for the next 12 months. You can see the agenda for the event here.
Press contact for AI Hardware Summit:
Stephanie Wright
Head of Marketing, Kisaco Research
[email protected]
+44 (0)203 897 6804






