



Architecting for AI Workloads Sponsored Content by Dell EMC
Artificial intelligence has come of age. To capitalize fully on the opportunities, organizations need to design high-performance computing architectures for AI workloads.
After years of talking about the promise of artificial intelligence, enterprises around the world are now diving headfirst into AI-driven processes and business models. From financial services to manufacturing, from healthcare to retail, enterprises are now “all in” with AI and its supporting computing models — notably machine and deep learning. The same holds true for universities and government agencies. They are using AI for countless pursuits, from driving groundbreaking scientific discoveries to protecting our national security.
This widespread embrace of all things AI is fueled by the rise of more powerful processors and accelerators, advanced tools and techniques for data analytics, more precise algorithms and — most of all — an explosion of data, driven to a large degree by the Internet of Things. When you put it all together, you’ve got what it takes to put AI to work in countless applications.
Architecting for AI workloads
To capitalize fully on the opportunities in today’s data-driven world, IT organizations need to design high-performance computing architectures to accommodate demanding AI workloads. The HPC and AI community has started optimizing AI frameworks and developer tools to address performance needs, allowing for much larger batch sizes to be processed on industry standard CPUs. Within the last year, Intel® has seen up to 241x training performance gains through optimized frameworks with Intel® Math Kernel Library (MKL) on Intel Xeon® Scalable Processors over Haswell processors. This can take your time to train from hours to minutes, while these optimizations provide the eco-system greater access to AI capabilities.
This shift to AI-focused infrastructure is happening today as organizations roll out systems that bring together the capabilities of HPC, data analytics and AI. This is the case with the University of Cambridge’s latest supercomputer, called Cumulus. This groundbreaking system was designed to serve as a single HPC cluster that supports researchers’ needs for data analytics, machine learning and large-scale data processing. The goal is to solve extremely difficult big data, simulation and AI challenges.
To meet this goal, the Cumulus architecture was designed to address the broad range of system challenges, including those at the compute, network, storage and software layers. A key objective was to make the infrastructure perform well for diverse, data-intensive research workloads.
The Cumulus system provides more than 2 petaflops of performance, powered by Dell EMC PowerEdge™ servers and Intel Xeon Scalable processors, all connected via the Intel Omni-Path Architecture (OPA). The system incorporates OpenStack® software to control pools of compute, storage and networking resources and make them readily accessible to users via a cloud interface.
Solving for I/O bottlenecks
This architectural foundation alone doesn’t necessarily solve today’s persistent I/O challenges in HPC clusters. Here’s the problem: While data-processing power has raced forward in recent years, storage I/O limitations have created bottlenecks that slow time to insight, particularly for researchers running data-centric workloads that interact continuously with data storage systems.
The Cumulus system removes these bottlenecks with a unique solution called the Data Accelerator (aka DAC), which is designed into the network topology. DAC incorporates technologies from Dell EMC, Intel and Cambridge University. In this architecture, the DAC nodes work in conjunction with the Distributed Name Space (DNE) feature in the Lustre file system and Intel® Omni-Path switches to accelerate system I/O.
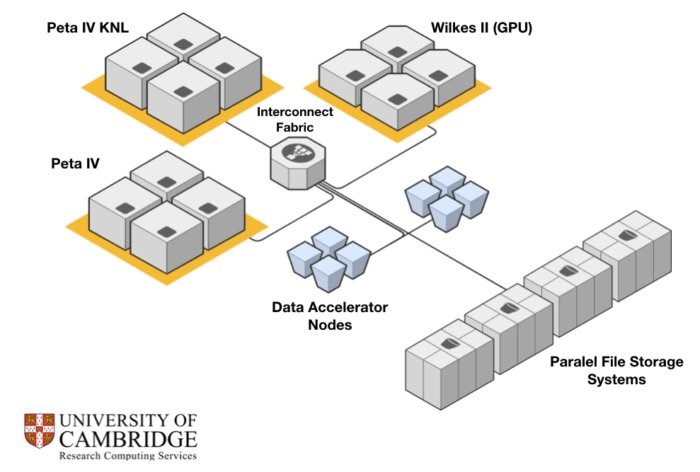 The results of this accelerated architecture have been rather amazing. With DAC under the hood, Cumulus provides more than 500 GB/s of I/O read performance, which makes it the UK’s fastest HPC I/O platform, according to the university’s Research Computing Service, which operates the Cumulus cluster.[1]
The results of this accelerated architecture have been rather amazing. With DAC under the hood, Cumulus provides more than 500 GB/s of I/O read performance, which makes it the UK’s fastest HPC I/O platform, according to the university’s Research Computing Service, which operates the Cumulus cluster.[1]
In benchmark testing, the Cumulus system achieved an IO-500 score of 158.7, which ranked the system third on the November 2018 IO-500 list. For system users, these numbers equate to big improvements in I/O performance for data-intensive HPC and AI workloads — and faster time to insight.
Building the right foundation for new and emerging workloads
For organizations searching for the right IT foundation for AI workloads, Intel offers expert insights in its high-level Guide to Developing an AI Infrastructure Strategy. The options outlined in this guide range from starting from scratch with your current systems to outsourcing your entire solution. One of these options is to build a broad platform that is designed to support a wide range of AI workloads — which is the approach the University of Cambridge took with its Cumulus system.
The guide explains: “This approach is similar to the emerging ‘platform’ architecture we now see prevalent across IT — that is, an approach that provides a highly scalable infrastructure layer that can be managed as a single pool, using virtualization and software-defined orchestration across server processing, storage and networking.”[2]
The guide presents this broad-platform infrastructure strategy in terms of a three-tier stack, with hardware, software and process layers that work together to enable AI workloads. A few highlights from this architecture:
- At the hardware layer, communication between devices and systems is based around an ultra-high speed backbone, such as the Intel® Omni-Path.
- The software layer includes operating system and virtualization layers, which support a library of AI-specific modules. These modules enable algorithmic processing and analytics, data management and I/O, as well as the delivery of data sources and the visualization of analysis results.
- The process layer runs the business logic of the AI application, using library modules to deliver capabilities like image recognition.
- Intel notes that this architecture results in a platform-based approach that offers a single point of configuration and a unique deployment target.
Key takeaways
The rise of artificial intelligence creates unprecedented opportunities for today’s enterprises. To fully capitalize on these opportunities, your organization needs a scalable HPC infrastructure that is specifically designed to incorporate the latest processor and fabric technologies, accommodate massive amounts of data, and leverage technologies to accelerate the data storage I/O and AI workloads.
To learn more
For a closer and more technical look at the University of Cambridge’s use of the Data Accelerator, visit the Research Computing Services’ Data Accelerator site. And for a broader look at the university’s Cumulus cluster, read the Dell EMC case study “UK Science Cloud.”
| The Convergence of HPC, Analytics and AI
High-performance computing, data analytics and artificial intelligence no longer live in separate domains. These complementary technologies are rapidly converging as organizations work to gain greater value from the data they capture and store. |
[1] Dell EMC case study, “UK Science Cloud,” November 2018.
[2] Intel, “Select the Best Infrastructure Strategy to Support Your AI Solution,” March 2018.






