



IBM Talks Power’s Future at Hot Chips

With processor, memory and networking technologies all racing to fill in for an ailing Moore’s law, the era of the heterogeneous datacenter is well underway, and IBM is positioning its chips to be the air traffic controller at the center of it all. That was the high-level takeway of our interview with IBM Power architects Jeff Stuecheli and Bill Starke at Hot Chips this week.
The accomplished engineers were at the 30th iteration of Hot Chips to focus on the Power9 scale-up chips and servers, but they also provided details on upcoming developments in the roadmap, including a new buffered memory system suitable for scale-out processors.
Having launched both the scale-out and scale-up Power9s, IBM is now working on a third P9 variant with “advanced I/O,” featuring IBM’s 25 GT/s PowerAXON signaling technology with upgraded OpenCAPI and NVLink protocols, and a new open standard for buffered memory.

Source: IBM slide (Hot Chips 30)
AXON is an inspired appellation that the Power engineering team came up with and the IBM marketing team signed off on. The A and X are designations for IBM’s SMP buses – X links are on-module and A links are off; the O and N stand for OpenCAPI and NVLINK, respectively. The convenient acronym would be fine at that, but aligning with IBM’s penchant for cognitive computing, axons are the brain’s signalling devices, allowing neurons to communicate, so you could say, as Witnix founder and former Harvard HPC guy James Cuff did, that AI is literally “built right into the wire."
“The PowerAXON concept gives us a lot of flexibility,” said Stuecheli. “One chip can be deployed to be a big SMP, it can be deployed to talk to lots of GPUs, it can talk to a mix of FPGAs and GPUs – that’s really our goal here is to build a processor that can then be customized toward these domain specific applications.”
For its future products, IBM is focusing on lots of lanes and lots of frequency. Its Power10 roadmap incorporates 32 GT/s signalling technology that will be able to run in 50 GT/s mode.
The idea that IO is composable is what OpenCAPI and PowerAXON are all about – and now IBM is bringing this same ethos to memory through the development of an open standard for buffered memory, appropriately called OpenCAPI memory.
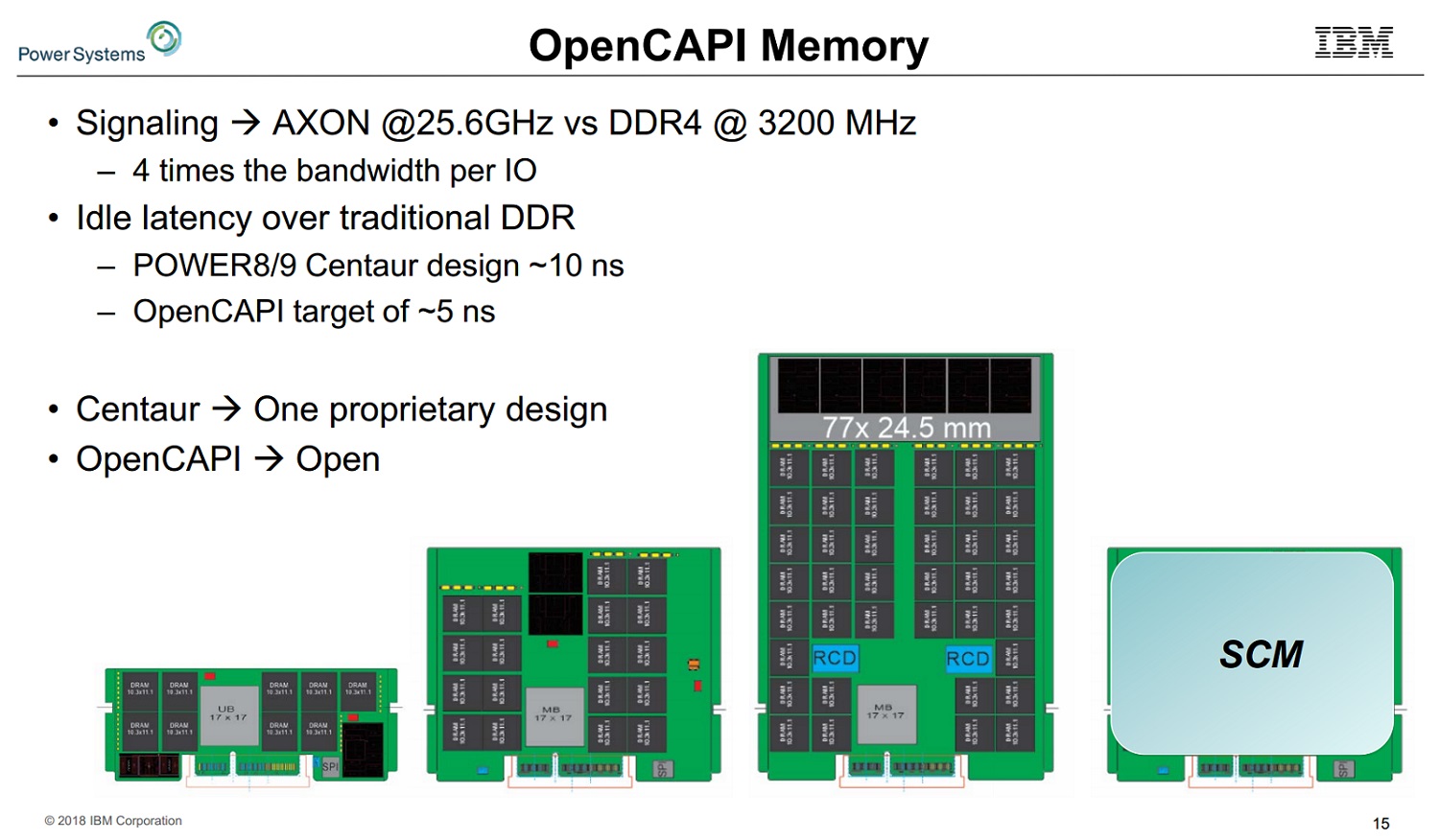
With both Power8 and Power9, the chips made for scale-out boxes support direct-attached memory, while the scale-up variants, intended for machines with more than two sockets, employ buffered memory. The buffered memory system puts DRAM chips right next to IBM’s Centaur buffer chip (see figure below-right), enabling a large number of DDR channels to be funneled into one processor over SERDES. The agnostic interface hides the exact memory technology that’s on the DIMM from the processor, so the processor can work with different kinds of memory. This decoupling of memory technology from the processor technology means that, for example, enterprise customers upgrading from Power8 to Power9 can keep their existing DDR4 DRAM DIMMs.
Stuecheli shared that the current buffered memory system (on Power8 and Power9 SU chips) adds a latency of approximately 10 nanoseconds compared to direct attached. This minimal overhead was accomplished “through careful framing of the packets as they go across the SERDES and bypasses in the DDR scheduling,” said Stuecheli.
While the Centaur-based approach is enterprise-focused, IBM wanted to offer the same buffered memory in its scale-out products. They are planning to introduce this capability as an open standard in the third (and presumably final) Power9 variant, due out in 2019. “We’ve been working through JEDEC to build memory DIMMs based around a thin buffer design,” said Stuecheli. “If you have an accelerator and you don’t like having that big expensive DDR PHY on it and you want to use just traditional SERDES to talk to memory you can do so with the new standardized memory interface we’re building,” he told the audience at Hot Chips. The interface spans from 1U small memory form factors all the way up to big tall DIMMs. The aim is to have an agnostic interface that attaches to a variety of memory types to it, whether that’s storage-class memory, or very high bandwidth, low capacity memory.
While the latency add was 10 nanoseconds on the proprietary design (with one port going to four DDR ports with a 16MB cache lookup), the new buffer IBM is building is a single port design with a single interface. It’s a much smaller chip without the cache, and IBM thinks it can reduce this latency to 5 nanoseconds. Stuecheli said that company-run simulations with loaded latency showed it doesn’t take much load at all before providing much lower latency than a direct-attached solution.
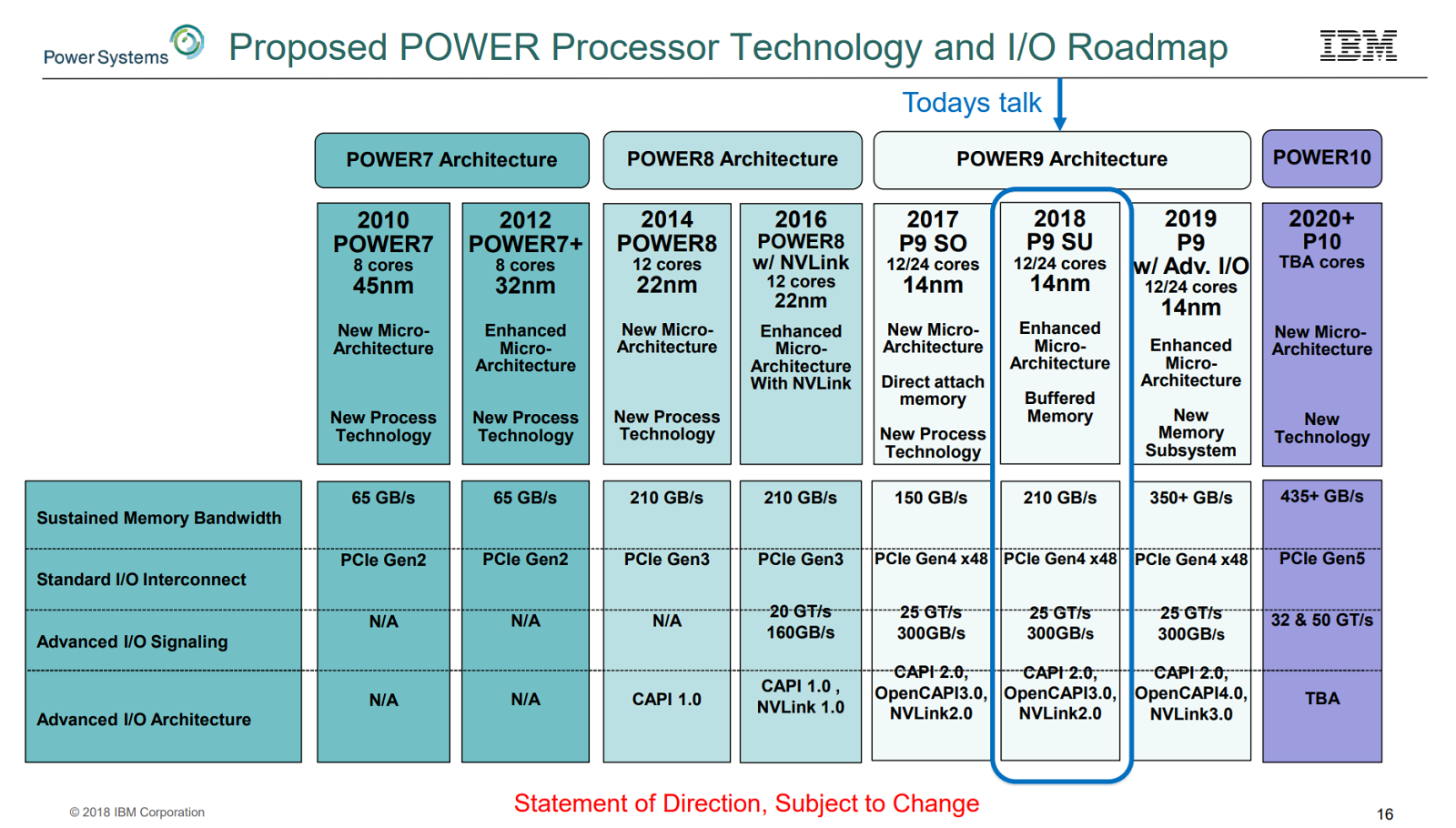
The roadmap shows the anticipated increase in memory bandwidth owing to the new memory system. Where the Power9 SU chip offers 210 GB/s of memory bandwidth (and Stuecheli says it’s actually closer to 230 GB/s), the next Power9 derivative chip, with the new memory technology, will be capable of deploying 350 GB/s per socket of bandwidth, according to Stuecheli.
“If you’re in HPC and disappointed in your bytes-per-flop ratio, that’s a pretty big improvement,” he said, adding “we’re taking what was essentially the Power10 memory subsystem and implementing that in Power9.” With Power10 bringing in DDR5, IBM expects to surpass 435 GB/s sustained memory bandwidth.
IBM believes that it has the right approach to push past DDR limitations. “When you think of Moore’s law kind of winding down, slowing down, you think of single-ended signaling with DDR memory slowing down,” Bill Starke said in a pre-briefing. “This composable system construct [that IBM is architecting] is enabling a proliferation of more heterogeneity in compute technology, along with a wider variation of memory technologies, all in this composable plug-and-play, put-it-together-how-you-want way where it’s all about a big high-bandwidth low-latency switching infrastructure.”
“With the flexibility of the attach on the memory side and on the compute acceleration side, it really boils down to thinking of the CPU chip as this big switch,” Stuecheli followed, “this big data switch that’s just one big pile of bandwidth connectivity that’s enabling any kind of memory to talk to any kind of acceleration, and it all plumbs right past the powerful general-purpose processor cores, so you’re pulling that whole compute estate together.”
HPC analyst Addison Snell (CEO of Intersect360 Research) came away from Tuesday’s Hot Chips talk with a favorable impression of the Power play. “IBM’s presentation at Hot Chips underscored two major themes,” Snell commented by email. “One, Power9 has excellent memory bandwidth and performance. Two, it is a great platform for attaching accelerators or co-processors. It’s an odd statement of direction, but maybe a visionary one, essentially saying a processor isn’t about computation per se, but rather it’s about feeding data to other computational elements.”
This article originally appeared in sister publication HPCwire.






