



The New Data Landscape: 4 Sectors into 2

Driven by digital transformation, the data landscape is evolving from four sectors into two. The macro forces driving this shift range from IoT to machine learning and AI. Technology forces behind the change stem from requirements to ingest data quickly, analyze data in real time, and accommodate massive new data streams. These capabilities help businesses derive actionable insights rapidly, whether to support enterprise decision making or to drive personalized applications.
For several years, the data landscape has had four sectors mapped on two axes. Data falls into the four sectors when we ask ourselves:
- Is my datastore relational?
- Is my datastore real time?
The Data Landscape in Four Sectors
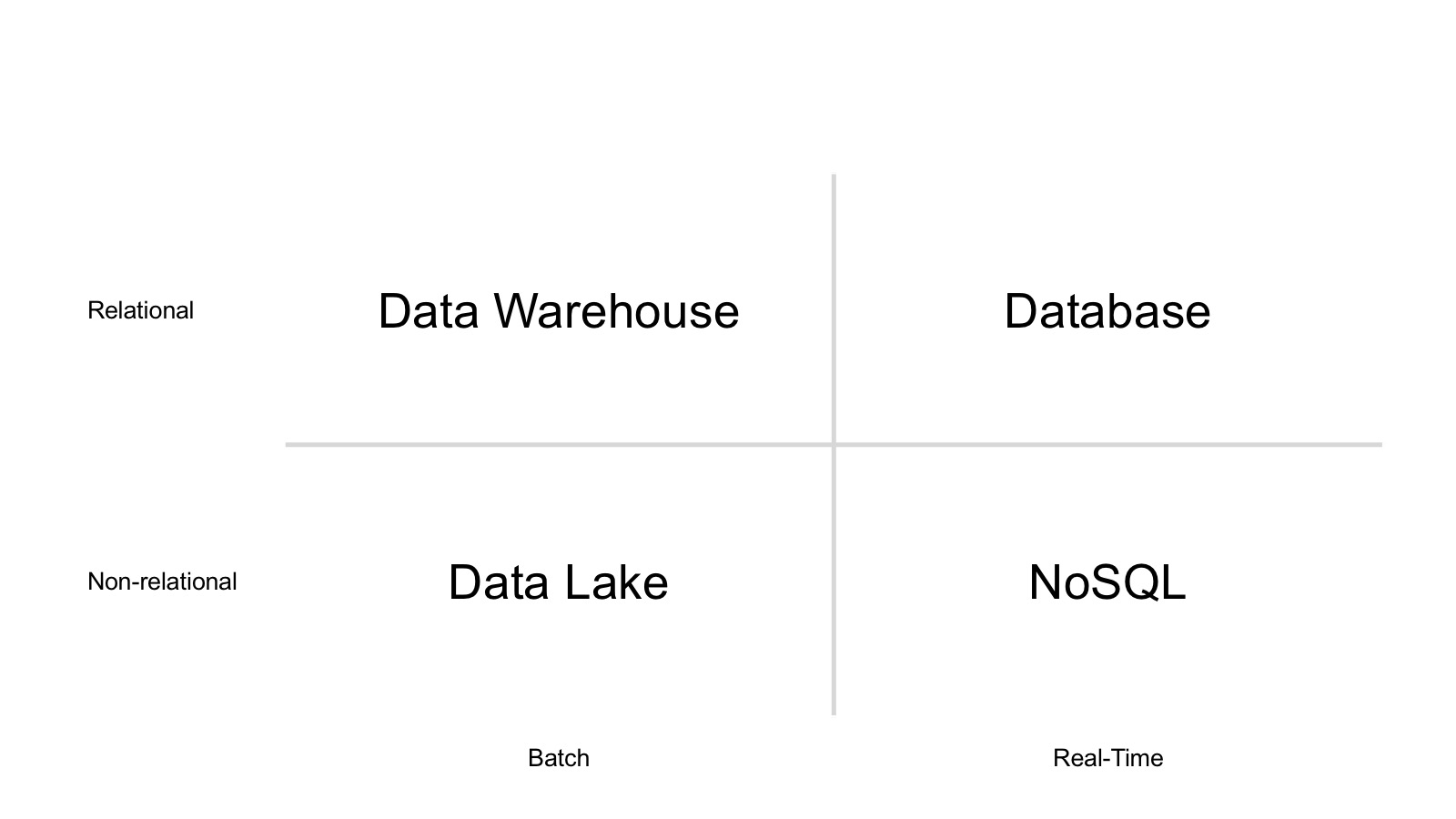
Figure 1. The Data Landscape in Four Sectors
Let’s briefly assess each sector:
The database remains the domain of transactional workloads and powers everyday business operations. Databases are the go-to software infrastructure to record the state of the business.
Data warehouses are the focal point for analytics. They help alleviate pressure from transactional databases by aggregating data and delivering responses to sophisticated analytical queries.
NoSQL is often used for simple transactional workloads where a basic key-value model is sufficient for the application.
Data lakes retain large amounts of historical data. They provide low-cost storage and the ability to store data in a number of different formats, including unstructured data types.
The Data Warehouse Split and NoSQL Integration
Let’s begin by examining the data warehouse split into two types: real-time and traditional. Data warehousing used to be an afterthought in the application food chain. First, the transactional application was designed, then came analytics, and finally business changes happened based on historical analysis.
But now, the interconnected world of devices – ranging from sensors to robotics to global smartphones – increasingly demands real time. As a result, applications must ingest and analyze massive streams of data with simple, operational analytics, ideally in a self-service format for business users. It’s this shift from historical to real-time analysis that separates traditional and real-time data warehousing.
As shown in the diagram below, traditional data warehousing aligns with the data lake, including storing historical data at the lowest cost. Traditional data warehouses provide easy insight to historical data, but lack support for real-time analytics and operational readiness.
The real-time data warehouse supports modern workloads, through the use of an operational architecture that aligns with the database, including transaction support. This may not mean full coverage of online transaction processing (OLTP) workloads, but this alignment does involve transactional semantics to ease application development.
To meet current enterprise requirements, a real-time data warehouse addresses:
- Structured and unstructured data
- Continuous data loading, including streaming ingest
- Ad hoc and compiled queries
- Transactionality, including updates
- Operational readiness
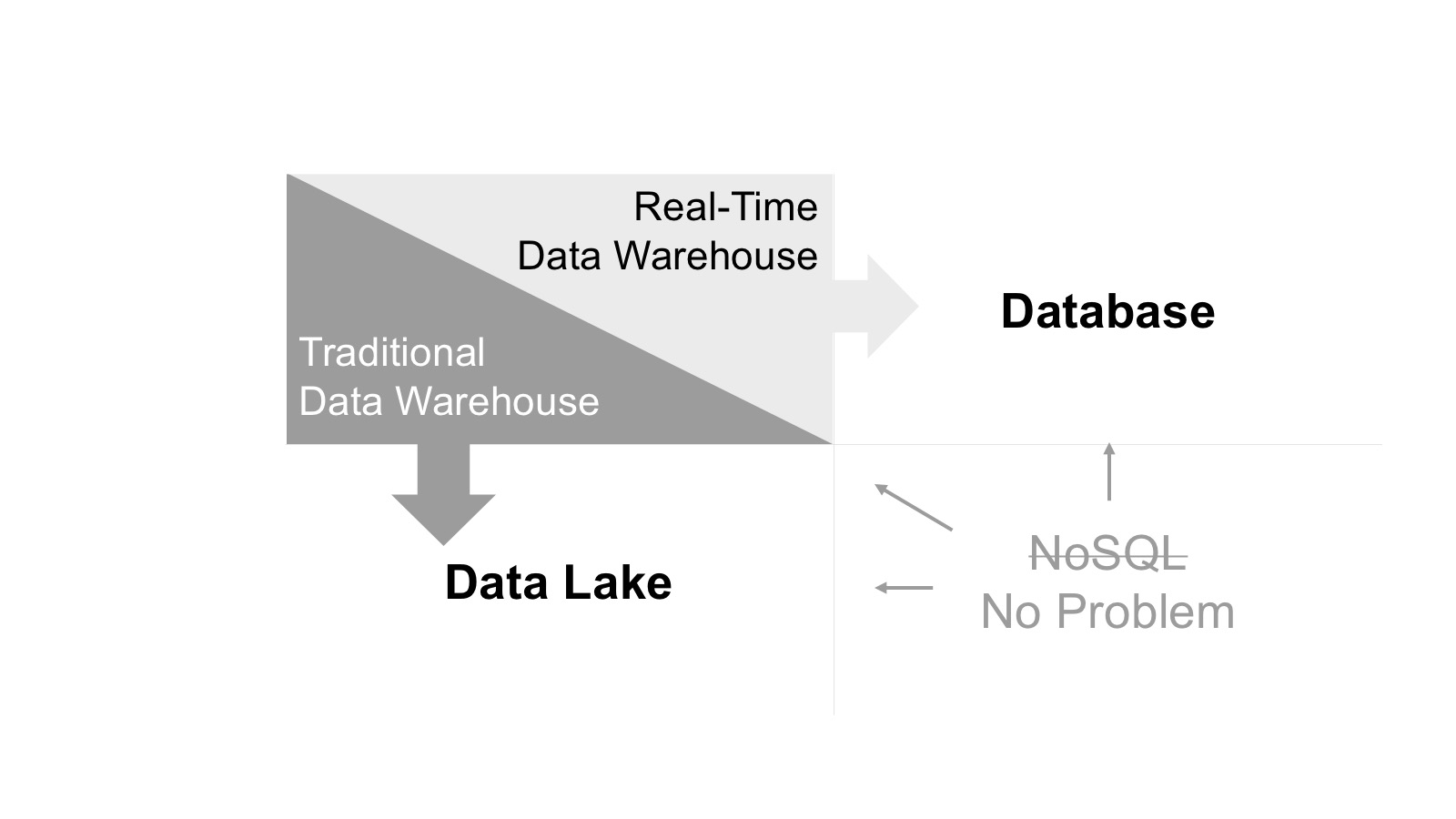
Figure 2. The Data Warehouse Split and NoSQL Integration
NoSQL Integration
Originally, NoSQL promised incredible scale for non-relational workloads, but unfortunately at a cost that made non-relational systems impractical for many. Now relational systems support flexible data models, and non-relational systems have moved to SQL. A Google paper from the SIGMOD conference showcases why NoSQL systems had to add SQL, and the blog summary [https://cloudplatform.googleblog.com/2017/06/from-NoSQL-to-New-SQL-how-Spanner-became-a-global-mission-critical-database.html] highlights four key themes:
- Although [Google] Spanner was initially designed as a NoSQL key-value store, new requirements led to an embrace of the relational model, as well
- The Spanner SQL query processor, while recognizable as a standard implementation, has unique capabilities that contribute to low-latency queries
- Long-term investments in SQL tooling have produced a familiar RDBMS-like user experience
- Spanner will soon rely on a new columnar format called Ressi designed for database-like access patterns (for hybrid OLAP/OLTP workloads)
Digging into the details, [http://dl.acm.org/citation.cfm?id=3056103] the authors explain the challenges of a building key-value system; developers of OLTP applications found it difficult to build applications without:
- A strong schema system
- Cross-row transactions
- Consistent replication
- A powerful query language
The paper describes initial attempts to build transaction processing on top of Bigtable. However these systems “lacked many traditional database features that application developers often rely on. A key example is a robust query language, meaning that developers had to write complex code to process and aggregate the data in their applications.”
In the final paragraph of the paper, the team stated that making Spanner a SQL system led them through milestones of:
- Scalability
- Manageability
- ACID transactions
- Relational model
- Schema DDL with indexing of nested data
- SQL
For other development organizations on a similar path we recommend starting with the relational model, once a scalable, available storage core is in place; well-known relational abstractions speed up the development and reduce the costs of foreseeable future migration.
So the NoSQL conclusion? For this team, they realized NoSQL would not work and they should have started with a relational model.
Industry analyst Mark Beyer of Gartner managed to sum it all up in a tweet:

Funny how it works. If I manage a basis of data, eventually language & database mgmt is needed. Or data mgmt solution, or...DBMS functions.
The Next End State for Data Architecture
While the data warehouse market splits and NoSQL functions are absorbed in other areas, the data lake emerges as the long-term storage location for static data. This is an area where the Hadoop Distributed File System (HDFS) and object stores such as Amazon S3 shine.
For applications without the need for real-time workflows or timely analytics, data lakes may work. For applications that involve real-time ingest and powerful analytics, a solution across the real-time data warehouse and database spectrum will do well.

Figure 3. The Next End State for Data Architecture
For enterprises seeking to save on data infrastructure, data lakes can be an appealing option. Architects should keep in mind that the ease of data lake loading correlates inversely with the ability to build fast, interactive applications.
If the data analytics project is directed towards an operational business application, then a path similar to Spanner’s, which bent heavily towards database functionally, will serve companies well. Finally, applications requiring real-time analytics and machine learning outputs will require a real-time data warehouse or database.
Gary Orenstein is senior vice president, product, at MemSQL.






