



At ISC – Goh on Go: Humans Can’t Scale, the Data-Centric Learning Machine Can

Source:Shutterstock 223391185
I've seen the future this week at ISC, it’s on display in prototype and Powerpoint form, and it’s going to blow you away. The future is an AI neural network designed to emulate, compete with and, ultimately, dwarf the human brain.
Scoff at such talk as farfetched or off in a hazy utopic/dystopic future. Tell us we’ve heard the hype before (you might remember a supercomputer company from 25 years ago with the inflated name of “Thinking Machines,” long defunct). But it’s neither futuristic nor hype, it’s happening now, the pieces are falling into place and the implications for business, for the world of work and for our everyday lives – for good or ill – are as staggering as they are real.
Aside: Conference attendees here in Frankfurt don’t seem particularly interested in those implications - nearly all the talk is about the “how” of AI, not the “what then?” But there’s one anecdote making the rounds that's raising eyebrows: when Google engineers were asked how its AlphaGo AI machine made the winning move against the world champion Go (the world’s most complex board game) player, the answer was: “We don’t know.”
The new, game-changing system architecture is an emerging style of computing called “data intensive” or “data centric.” It replaces processing with memory (i.e., data) at the center of the computing universe. New memory and processor technologies will be combined with advanced algorithms to make the new architecture a practical reality. Once the pieces are in place, these systems will be scaled beyond all measure of human brain capacity.
What does data centric computing mean? How does it work? Why does it represent a major shift in advanced scale computing?
Let’s start by looking at how data centric systems are measured. The benchmark for new AI systems isn’t how fast they solve linear algebra problems (i.e., LINPACK). That’s how processor-centric systems are measured, and considering the capabilities of data-centric systems under development, that benchmark seems wholly inadequate.
Rather than throughput, AI-based systems are measured in relation to people: their ability to compete with humans at our most intellectually challenging games of reason – checkers, chess, Go, poker. The standard of success isn’t training the system to become perfect at it, or to “solve” the game (i.e., work out the right response to every possible combination of moves). The benchmark is playing the game better than any human.
That’s the objective. Once the system is better than any of us, it’s ready to move into an advisory role, providing guidance and suggestions, augmenting our capabilities. For now. In a decade or so, these systems will take over tasks for us altogether.
Driving a car is a prime example. If driving were a game, humans would still beat machines – even though statistics show we’re getting worse at it (according to Dr. Pradeep Dubey, Intel Fellow, Intel Labs & Director, Parallel Computing Lab, who presented at ISC on autonomous vehicle technology). Around the world, two people are killed in car accidents each minute. In the U.S., 40,000 people are killed annually and 2 million suffer permanent injuries.
While we go on killing and injuring each other in cars, AI is enabling machines to steadily improve at driving. For now, the AI in cars available to the public is limited to navigating, warning us about traffic conditions and setting off beepers when we get close to curbs and other cars. But a convergence point is coming.
The next step: our roads will have special lanes where we’ll temporarily hand over operation of the car to itself. A few years after that, we won’t drive at all. Driving is a game in which machines will soon overtake out skills.
Dr. Eng Lim Goh, Vice President of HPE and an industry visionary for decades, is a prime driver of new AI system development. At ISC this week, he discussed why AI in all its forms – machine learning, deep learning, strategic reasoning, etc. – is the driving force bringing about “data intensive” computing architectures.
Here’s his schema for the data intensive computer:
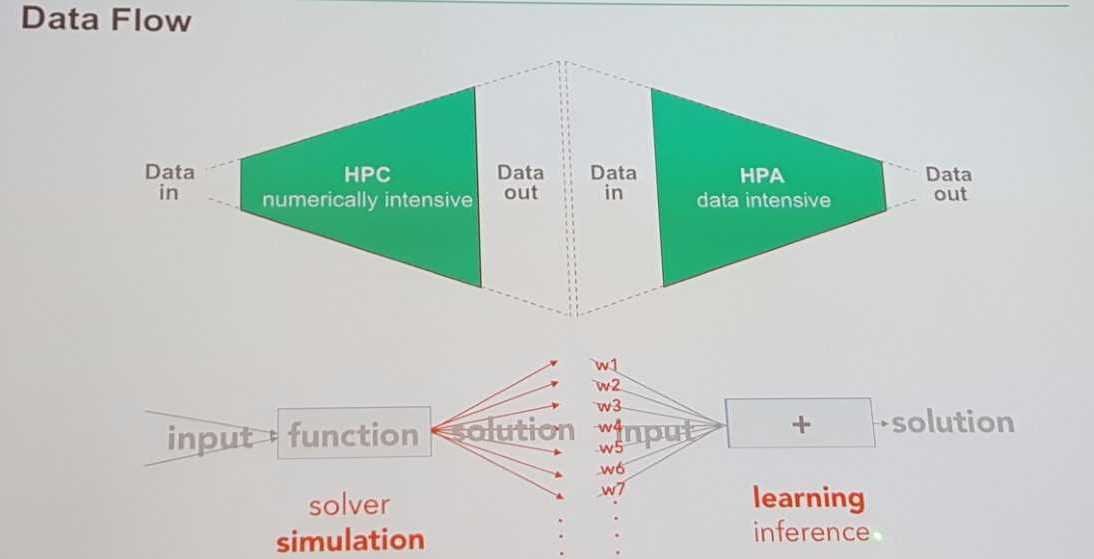 The left side of the diagram is old-style, LINPACK-benchmarked, processor-centric computing. That’s where HPC happens. The processor is at the center. Data is sent to the CPU, simulations are run, and new, and more, data comes out. HPC systems have hit a wall of their own making. When they run their simulations, exponentially more machine-generated data is produced than they started with, data in volumes beyond the capability of data scientists to manage or big data analytics to analyze.
The left side of the diagram is old-style, LINPACK-benchmarked, processor-centric computing. That’s where HPC happens. The processor is at the center. Data is sent to the CPU, simulations are run, and new, and more, data comes out. HPC systems have hit a wall of their own making. When they run their simulations, exponentially more machine-generated data is produced than they started with, data in volumes beyond the capability of data scientists to manage or big data analytics to analyze.
“For 30 years we’ve lived in this world where small amounts of data go in, and we apply supercomputing power onto our partial differential equations, or our models, to generate lots of data,” he said. But already, Goh pointed out, there aren’t enough data scientists to meet demand for today’s data analytics requirements. For the torrents of machine-generated data to come, there’s an overwhelming need to automate how data is managed and analyzed.
Take for example seismic exploration.
For exploration of energy reserves at sea, ships drag cables with hydrophones, fire shots into the ocean floor and collect the echo on sensors. For every 10TB of data collected by the sensors, 1PB of simulation data is produced – 100X the original data.
That’s where the right side of the diagram comes in: high performance analytics (HPA), self-learning AI systems that can take voluminous amounts of data produced by HPC, put it in memory, and work up answers to questions.

Dr. Eng Lim Goh
The key to the data-centric system of the future is the border area in the middle of the diagram. That’s where memory (i.e., data) resides, like a queen bee. It will be surrounded by a variety of processors (CPUs, GPUs, FPGAs, ASICs, assigned jobs appropriate for their capabilities) operating around the data, like drones.
Looked at this way, in a world where most companies have analyzed only about 3 percent of their data on average, traditional HPC systems seem glaringly incomplete. But combining the left side of the diagram and the right, integrating HPC with HPA – that takes supercomputing somewhere new. That’s a machine with a new soul.
Goh conceded there are barriers to HPC and HPA joining forces.
“The two worlds are very different,” Goh said. “The HPC world where I lived, I’m guilty of this. All these years we assumed data movement was free. Guess what? When LINPACK started 20 years ago we didn’t consider data movement. Yet we’re still ranking our Top500 systems that way (processing throughput). We’re still guilty that way.
“But the data scientists of the world also have something to say about us,” he added. “They assume compute is free. Take Hadoop. Hadoop is a technique where you map your data out onto compute nodes, then do your computation, then you reduce the data you bring back. The data world called this MapReduce. So we have to bring the two worlds together. More and more now, people should be investing in one system of left and right, not just the left.”
Goh pointed to the middle of his diagram and said that’s where the big architectural challenge lies. “If you have to move an exabyte of data between system A and B, if they are two different systems, it will be impractical. The world will come to this (integration of HPC and HPA).”
That’s why the U.S. effort to develop a “capable” exascale computer by the early 2020’s puts as much emphasis on compute power as memory capacity. A mission document issued by the Exascale Computing Project said its intent to build a system not just with an exaflop of processing power but one that also can handle an exabyte of data in memory.
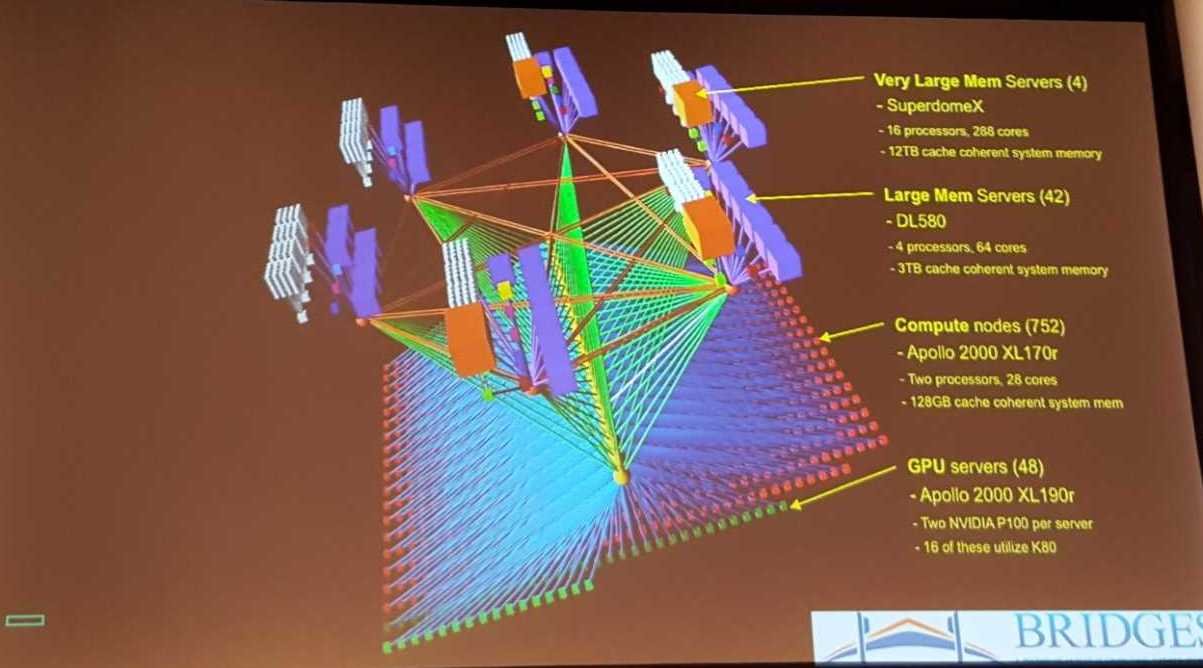
Goh described HPE’s “Bridges” system at the Pittsburgh Supercomputer Center as a data-centric supercomputer that incorporates HPC and HPA, designed specifically for “scalable deep learning.”
“Essentially, it’s a bandwidth machine,” Goh said. “It’s a supercomputer, but really it’s a data mover. Not only are NVlinks all connected, they’re also GPU-connected, so clumps of four GPUs can talk to other clumps of four GPUs directly. Then we have four OPA’s coming out of each node, giving one OPA per GPU. So this is really a data machine.”
 The Bridges supercomputer pulled off one of the most impressive game wins of the emerging AI era when it defeated four of the world’s top poker players earlier this year. Actually, the competition stretched across two years, Goh said, with the AI system losing $700,000 to the human players the first year they played. The second year, with 10X more compute from the Bridges computer, the AI system (“Libratus”) took the four humans for $1.7 million, a classic hustle.
The Bridges supercomputer pulled off one of the most impressive game wins of the emerging AI era when it defeated four of the world’s top poker players earlier this year. Actually, the competition stretched across two years, Goh said, with the AI system losing $700,000 to the human players the first year they played. The second year, with 10X more compute from the Bridges computer, the AI system (“Libratus”) took the four humans for $1.7 million, a classic hustle.
While IBM Deep Blue (chess) and Google’s AlphaGo have grabbed most of the machine-defeated-human headlines of late, it’s less well known that starting 25 years ago machines have beaten humans at checkers, which has 1020 “naïve” (or possible) combinations. Chess has 1047 naïve combinations. How big is 1047? An exascale machine running for 100 years would complete only 1028 combinations. The point being that without integrated deep learning techniques, processing alone only gets you so far.
 Go, meanwhile, has 10171 combinations. Poker, with “only” 10160 combinations, offers up the added complexity of “incomplete information.” Unlike the three board games, in which you can see your opponents pieces, you don’t know what your poker opponents hold in their hands.
Go, meanwhile, has 10171 combinations. Poker, with “only” 10160 combinations, offers up the added complexity of “incomplete information.” Unlike the three board games, in which you can see your opponents pieces, you don’t know what your poker opponents hold in their hands.
“So we didn’t solve chess, machines didn’t solve chess,” Goh said, “all they did was be good enough to be superhuman – to beat any human. That’s a term were going to hear more and more now.”
After Goh’s presentation, he was asked about Google not understanding how AlpaGo won the Go tournament. The issue, he said, is overcoming opacity.
“We’re working very hard to increasing transparency,” he said. “Some people have discussed the idea that there are many stages in a neural network, to intercept it in between those stages, and take its output and see if you can make sense of it.”
Leaving a strong role for human supervision also is important. He pointed out that since the Industrial Revolution, workers get promoted from first operating a machine and then supervising machines.
He also discussed the distinction between the “correct” and the “right” answer. An AI-based system may deliver a correct answer, but whether it’s “right” – acceptable within human social mores, the bounds of business ethics, or aesthetic judgment – is something only humans can decide.
“Societal values need to be applied, human values need to be applied,” he said.






